 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spectral Revisit of the Distributional Bellman Operator under the Cramér Metric
Mar 13, 2026Distributional reinforcement learning (DRL) studies the evolution of full return distributions under Bellman updates rather than focusing on expected values. A classical result is that the distributional Bellman operator is contractive under the Cramér metric, which corresponds to an $L^2$ geometry on differences of cumulative distribution functions (CDFs). While this contraction ensures stability of policy evaluation, existing analyses remain largely metric, focusing on contraction properties without elucidating the structural action of the Bellman update on distributions. In this work, we analyse distributional Bellman dynamics directly at the level of CDFs, treating the Cramér geometry as the intrinsic analytical setting. At this level, the Bellman update acts affinely on CDFs and linearly on differences between CDFs, and its contraction property yields a uniform bound on this linear action. Building on this intrinsic formulation, we construct a family of regularised spectral Hilbert representations that realise the CDF-level geometry by exact conjugation, without modifying the underlying Bellman dynamics. The regularisation affects only the geometry and vanishes in the zero-regularisation limit, recovering the native Cramér metric. This framework clarifies the operator structure underlying distributional Bellman updates and provides a foundation for further functional and operator-theoretic analyses in DRL.
Learning and reusing primitive behaviours to improve Hindsight Experience Replay sample efficiency
Oct 03, 2023

Hindsight Experience Replay (HER) is a technique used in reinforcement learning (RL) that has proven to be very efficient for training off-policy RL-based agents to solve goal-based robotic manipulation tasks using sparse rewards. Even though HER improves the sample efficiency of RL-based agents by learning from mistakes made in past experiences, it does not provide any guidance while exploring the environment. This leads to very large training times due to the volume of experience required to train an agent using this replay strategy. In this paper, we propose a method that uses primitive behaviours that have been previously learned to solve simple tasks in order to guide the agent toward more rewarding actions during exploration while learning other more complex tasks. This guidance, however, is not executed by a manually designed curriculum, but rather using a critic network to decide at each timestep whether or not to use the actions proposed by the previously-learned primitive policies. We evaluate our method by comparing its performance against HER and other more efficient variations of this algorithm in several block manipulation tasks. We demonstrate the agents can learn a successful policy faster when using our proposed method, both in terms of sample efficiency and computation time. Code is available at https://github.com/franroldans/qmp-her.
Hierarchical reinforcement learning for in-hand robotic manipulation using Davenport chained rotations
Oct 03, 2022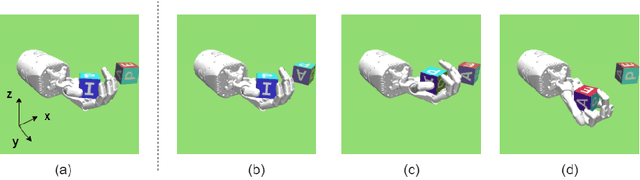
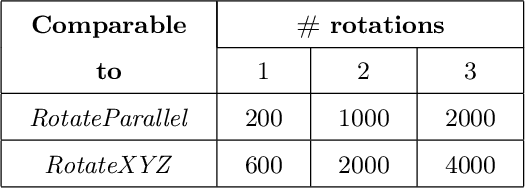
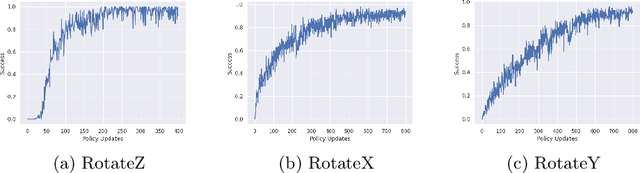

End-to-end reinforcement learning techniques are among the most successful methods for robotic manipulation tasks. However, the training time required to find a good policy capable of solving complex tasks is prohibitively large. Therefore, depending on the computing resources available, it might not be feasible to use such techniques. The use of domain knowledge to decompose manipulation tasks into primitive skills, to be performed in sequence, could reduce the overall complexity of the learning problem, and hence reduce the amount of training required to achieve dexterity. In this paper, we propose the use of Davenport chained rotations to decompose complex 3D rotation goals into a concatenation of a smaller set of more simple rotation skills. State-of-the-art reinforcement-learning-based methods can then be trained using less overall simulated experience. We compare its performance with the popular Hindsight Experience Replay method, trained in an end-to-end fashion using the same amount of experience in a simulated robotic hand environment. Despite a general decrease in performance of the primitive skills when being sequentially executed, we find that decomposing arbitrary 3D rotations into elementary rotations is beneficial when computing resources are limited, obtaining increases of success rates of approximately 10% on the most complex 3D rotations with respect to the success rates obtained by HER trained in an end-to-end fashion, and increases of success rates between 20% and 40% on the most simple rotations.
Towards advanced robotic manipulation
Sep 26, 2022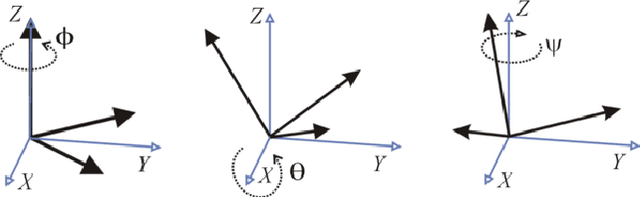
Robotic manipulation and control has increased in importance in recent years. However, state of the art techniques still have limitations when required to operate in real world applications. This paper explores Hindsight Experience Replay both in simulated and real environments, highlighting its weaknesses and proposing reinforcement-learning based alternatives based on reward and goal shaping. Additionally, several research questions are identified along with potential research directions that could be explored to tackle those questions.