 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Sampling is Preconditioned Stochastic Gradient Descent on Zero-One Loss
Dec 05, 2018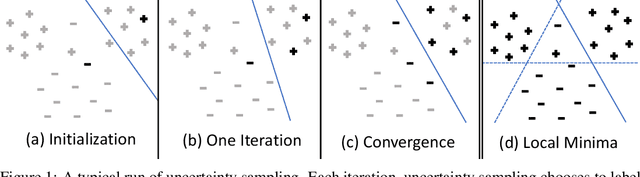
Uncertainty sampling, a popular active learning algorithm, is used to reduce the amount of data required to learn a classifier, but it has been observed in practice to converge to different parameters depending on the initialization and sometimes to even better parameters than standard training on all the data. In this work, we give a theoretical explanation of this phenomenon, showing that uncertainty sampling on a convex loss can be interpreted as performing a preconditioned stochastic gradient step on a smoothed version of the population zero-one loss that converges to the population zero-one loss. Furthermore, uncertainty sampling moves in a descent direction and converges to stationary points of the smoothed population zero-one loss. Experiments on synthetic and real datasets support this connection.
On the Relationship between Data Efficiency and Error for Uncertainty Sampling
Jun 15, 2018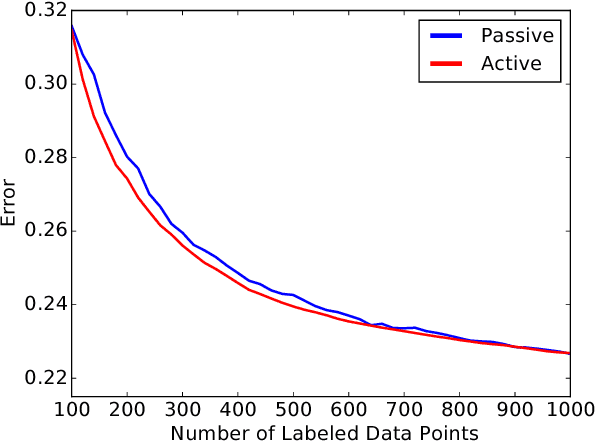
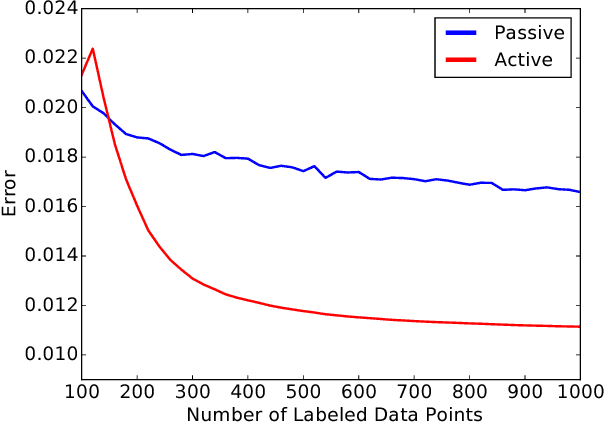
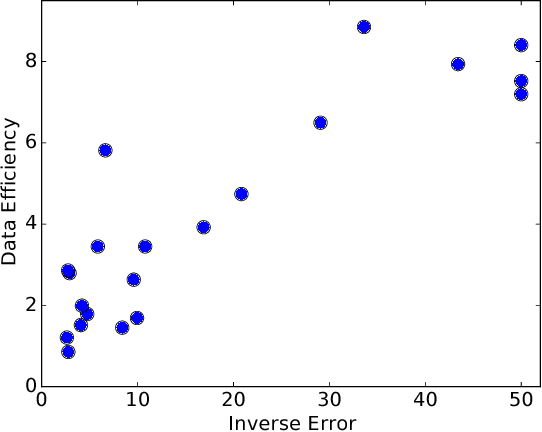
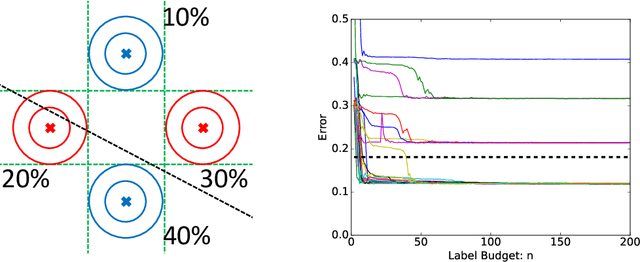
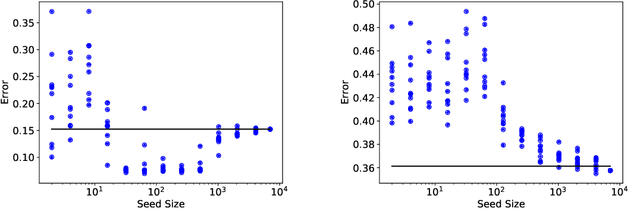
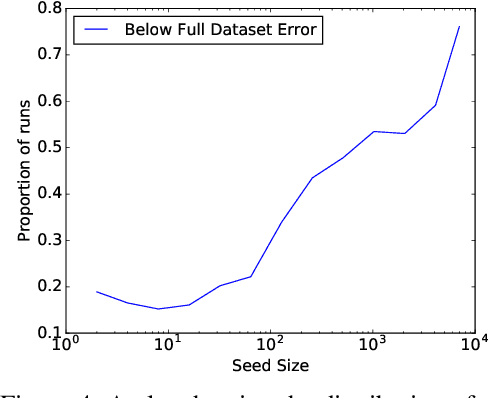
While active learning offers potential cost savings, the actual data efficiency---the reduction in amount of labeled data needed to obtain the same error rate---observed in practice is mixed. This paper poses a basic question: when is active learning actually helpful? We provide an answer for logistic regression with the popular active learning algorithm, uncertainty sampling. Empirically, on 21 datasets from OpenML, we find a strong inverse correlation between data efficiency and the error rate of the final classifier. Theoretically, we show that for a variant of uncertainty sampling, the asymptotic data efficiency is within a constant factor of the inverse error rate of the limiting classifier.
Generalized Binary Search For Split-Neighborly Problems
Feb 27, 2018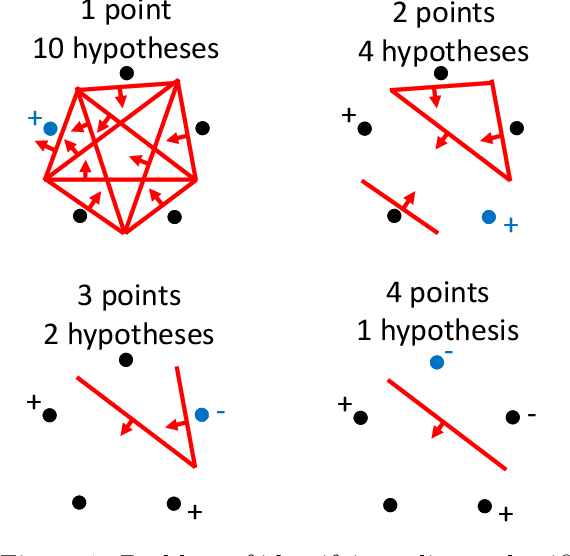
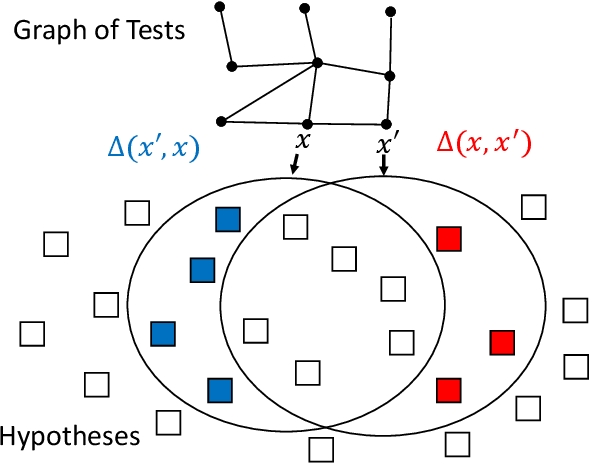
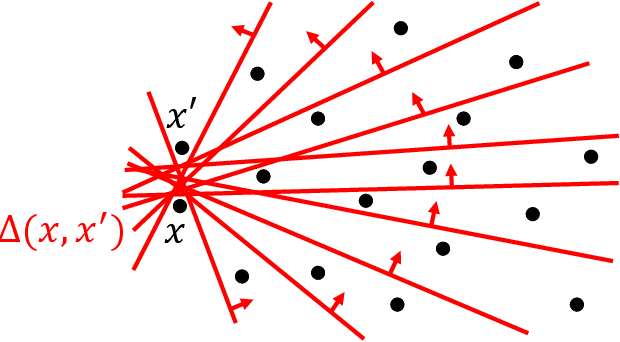
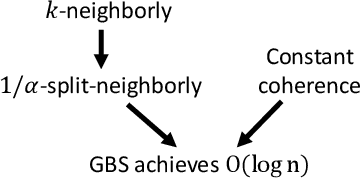
In sequential hypothesis testing, Generalized Binary Search (GBS) greedily chooses the test with the highest information gain at each step. It is known that GBS obtains the gold standard query cost of $O(\log n)$ for problems satisfying the $k$-neighborly condition, which requires any two tests to be connected by a sequence of tests where neighboring tests disagree on at most $k$ hypotheses. In this paper, we introduce a weaker condition, split-neighborly, which requires that for the set of hypotheses two neighbors disagree on, any subset is splittable by some test. For four problems that are not $k$-neighborly for any constant $k$, we prove that they are split-neighborly, which allows us to obtain the optimal $O(\log n)$ worst-case query cost.
Fast Amortized Inference and Learning in Log-linear Models with Randomly Perturbed Nearest Neighbor Search
Jul 11, 2017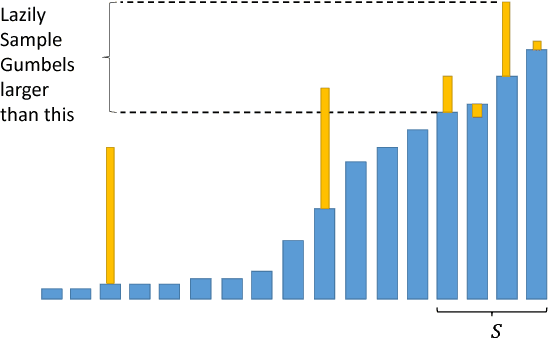

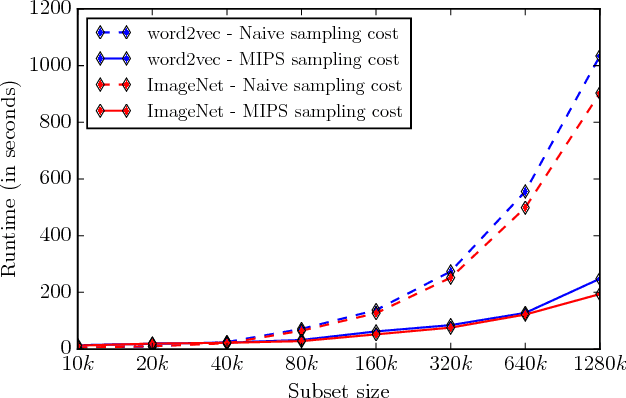

Inference in log-linear models scales linearly in the size of output space in the worst-case. This is often a bottleneck in natural language processing and computer vision tasks when the output space is feasibly enumerable but very large. We propose a method to perform inference in log-linear models with sublinear amortized cost. Our idea hinges on using Gumbel random variable perturbations and a pre-computed Maximum Inner Product Search data structure to access the most-likely elements in sublinear amortized time. Our method yields provable runtime and accuracy guarantees. Further, we present empirical experiments on ImageNet and Word Embeddings showing significant speedups for sampling, inference, and learning in log-linear models.
Understanding Trajectory Behavior: A Motion Pattern Approach
Jan 04, 2015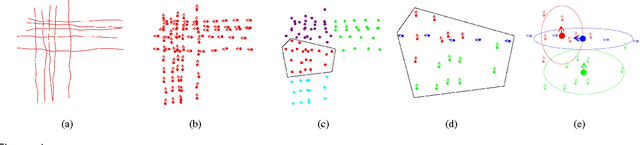
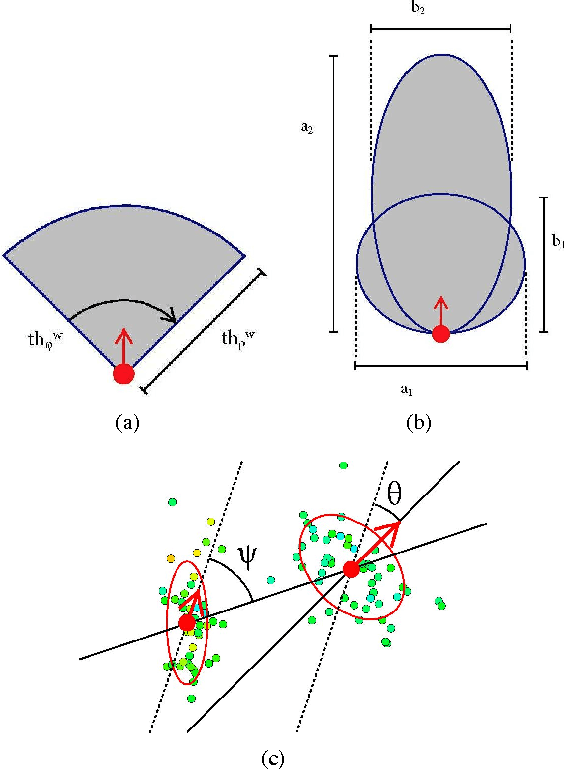
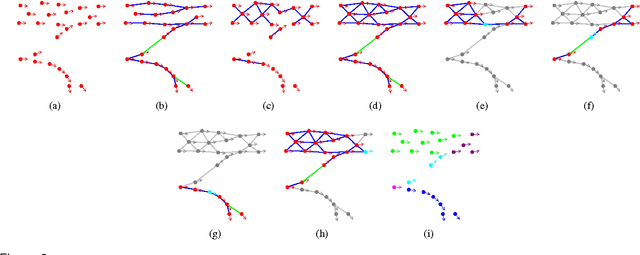

Mining the underlying patterns in gigantic and complex data is of great importance to data analysts. In this paper, we propose a motion pattern approach to mine frequent behaviors in trajectory data. Motion patterns, defined by a set of highly similar flow vector groups in a spatial locality, have been shown to be very effective in extracting dominant motion behaviors in video sequences. Inspired by applications and properties of motion patterns, we have designed a framework that successfully solves the general task of trajectory clustering. Our proposed algorithm consists of four phases: flow vector computation, motion component extraction, motion component's reachability set creation, and motion pattern formation. For the first phase, we break down trajectories into flow vectors that indicate instantaneous movements. In the second phase, via a Kmeans clustering approach, we create motion components by clustering the flow vectors with respect to their location and velocity. Next, we create motion components' reachability set in terms of spatial proximity and motion similarity. Finally, for the fourth phase, we cluster motion components using agglomerative clustering with the weighted Jaccard distance between the motion components' signatures, a set created using path reachability. We have evaluated the effectiveness of our proposed method in an extensive set of experiments on diverse datasets. Further, we have shown how our proposed method handles difficulties in the general task of trajectory clustering that challenge the existing state-of-the-art methods.