Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Relationship between Data Efficiency and Error for Uncertainty Sampling
Paper and Code
Jun 15, 2018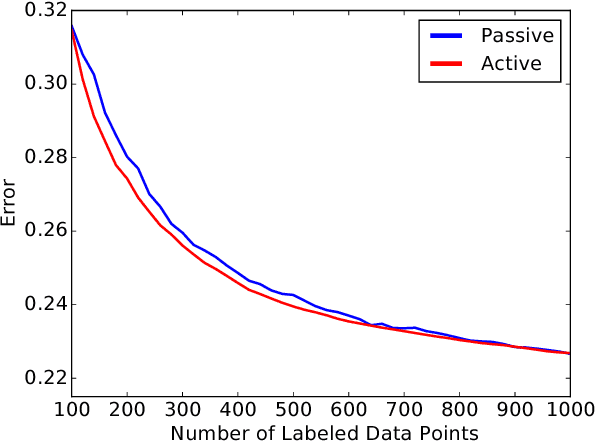
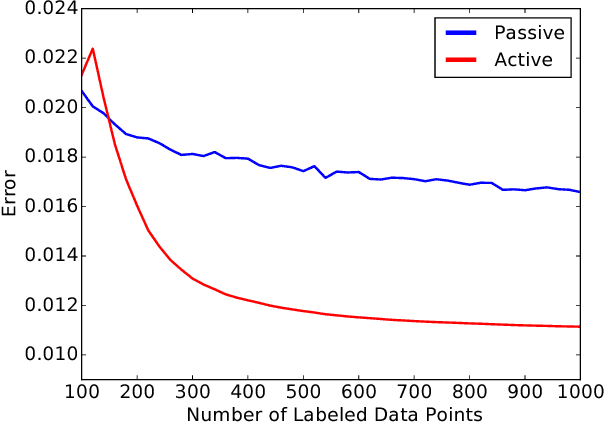
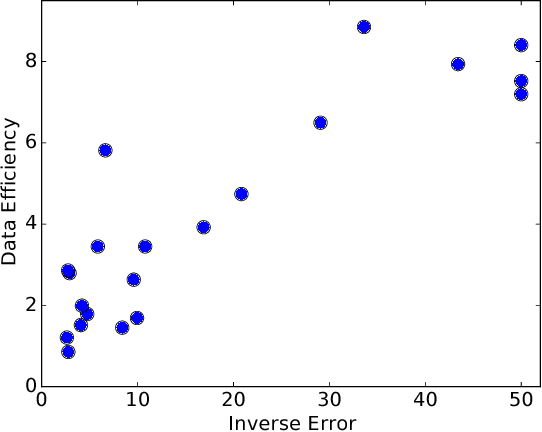
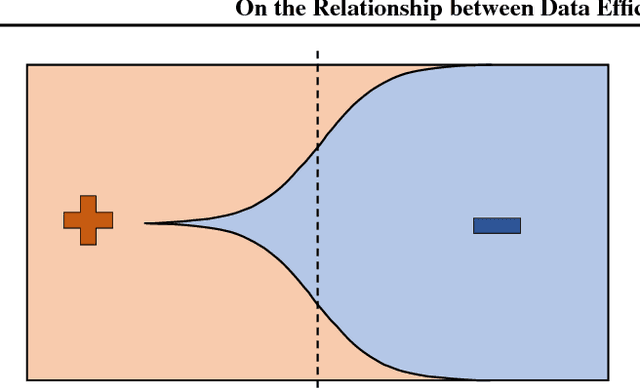
While active learning offers potential cost savings, the actual data efficiency---the reduction in amount of labeled data needed to obtain the same error rate---observed in practice is mixed. This paper poses a basic question: when is active learning actually helpful? We provide an answer for logistic regression with the popular active learning algorithm, uncertainty sampling. Empirically, on 21 datasets from OpenML, we find a strong inverse correlation between data efficiency and the error rate of the final classifier. Theoretically, we show that for a variant of uncertainty sampling, the asymptotic data efficiency is within a constant factor of the inverse error rate of the limiting classifier.
View paper on