 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Think Outside the Box: Wide-Baseline Light Field Depth Estimation with EPI-Shift
Sep 19, 2019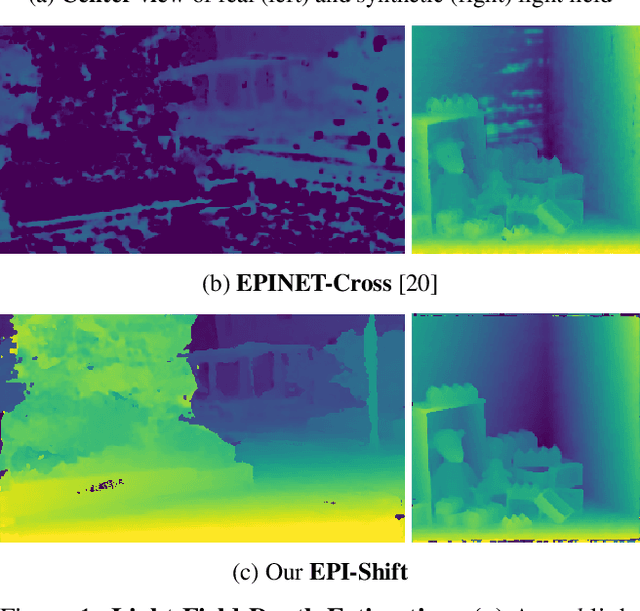


We propose a method for depth estimation from light field data, based on a fully convolutional neural network architecture. Our goal is to design a pipeline which achieves highly accurate results for small- and wide-baseline light fields. Since light field training data is scarce, all learning-based approaches use a small receptive field and operate on small disparity ranges. In order to work with wide-baseline light fields, we introduce the idea of EPI-Shift: To virtually shift the light field stack which enables to retain a small receptive field, independent of the disparity range. In this way, our approach "learns to think outside the box of the receptive field". Our network performs joint classification of integer disparities and regression of disparity-offsets. A U-Net component provides excellent long-range smoothing. EPI-Shift considerably outperforms the state-of-the-art learning-based approaches and is on par with hand-crafted methods. We demonstrate this on a publicly available, synthetic, small-baseline benchmark and on large-baseline real-world recordings.
Structural Similarity based Anatomical and Functional Brain Imaging Fusion
Aug 14, 2019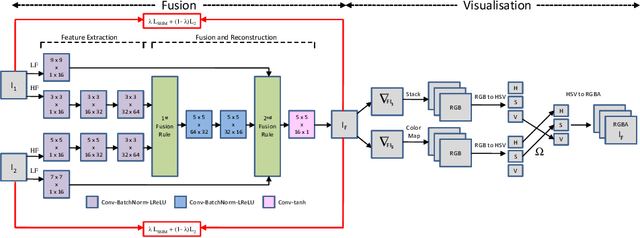
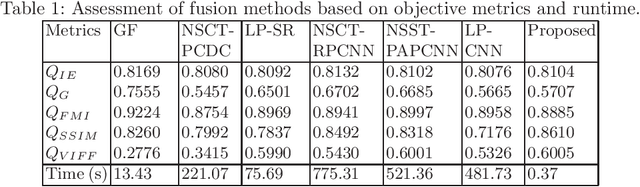
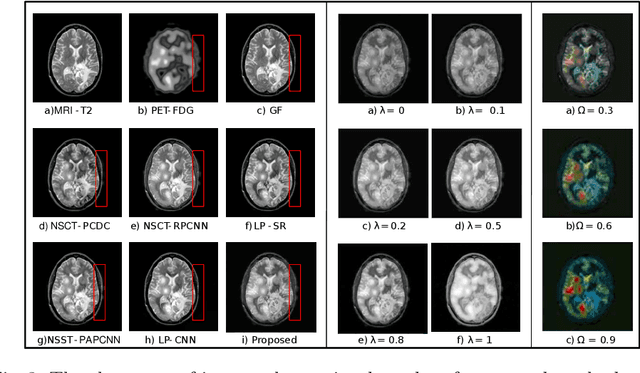
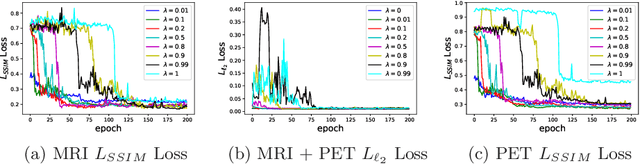
Multimodal medical image fusion helps in combining contrasting features from two or more input imaging modalities to represent fused information in a single image. One of the pivotal clinical applications of medical image fusion is the merging of anatomical and functional modalities for fast diagnosis of malignant tissues. In this paper, we present a novel end-to-end unsupervised learning-based Convolutional Neural Network (CNN) for fusing the high and low frequency components of MRI-PET grayscale image pairs, publicly available at ADNI, by exploiting Structural Similarity Index (SSIM) as the loss function during training. We then apply color coding for the visualization of the fused image by quantifying the contribution of each input image in terms of the partial derivatives of the fused image. We find that our fusion and visualization approach results in better visual perception of the fused image, while also comparing favorably to previous methods when applying various quantitative assessment metrics.
DSAC - Differentiable RANSAC for Camera Localization
Mar 21, 2018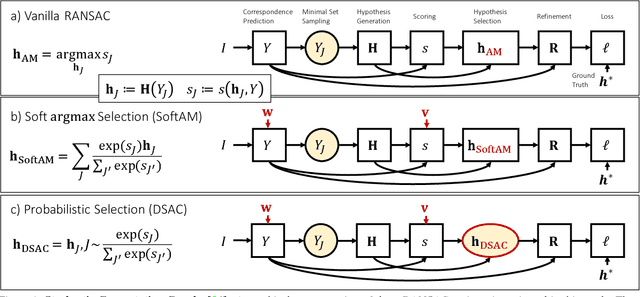
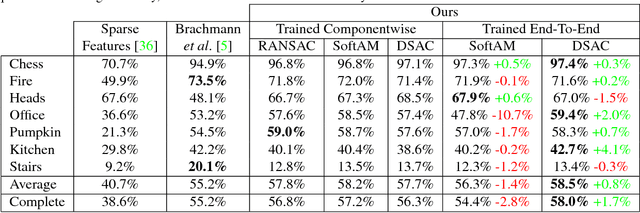

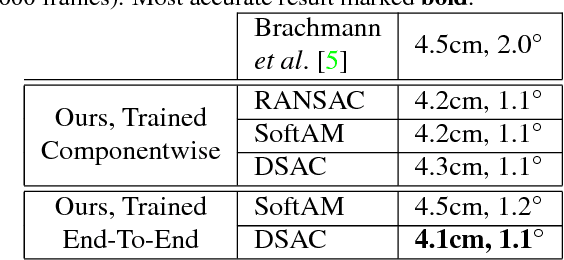
RANSAC is an important algorithm in robust optimization and a central building block for many computer vision applications. In recent years, traditionally hand-crafted pipelines have been replaced by deep learning pipelines, which can be trained in an end-to-end fashion. However, RANSAC has so far not been used as part of such deep learning pipelines, because its hypothesis selection procedure is non-differentiable. In this work, we present two different ways to overcome this limitation. The most promising approach is inspired by reinforcement learning, namely to replace the deterministic hypothesis selection by a probabilistic selection for which we can derive the expected loss w.r.t. to all learnable parameters. We call this approach DSAC, the differentiable counterpart of RANSAC. We apply DSAC to the problem of camera localization, where deep learning has so far failed to improve on traditional approaches. We demonstrate that by directly minimizing the expected loss of the output camera poses, robustly estimated by RANSAC, we achieve an increase in accuracy. In the future, any deep learning pipeline can use DSAC as a robust optimization component.
Global Hypothesis Generation for 6D Object Pose Estimation
Jan 02, 2017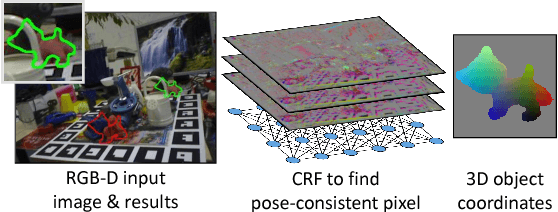
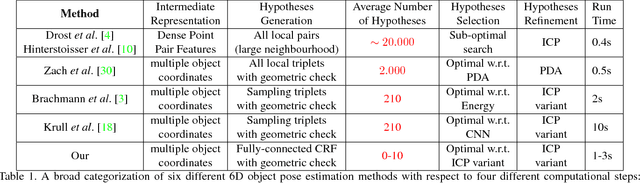
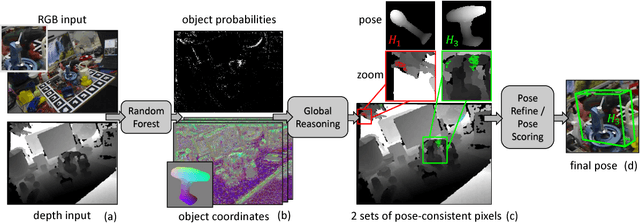
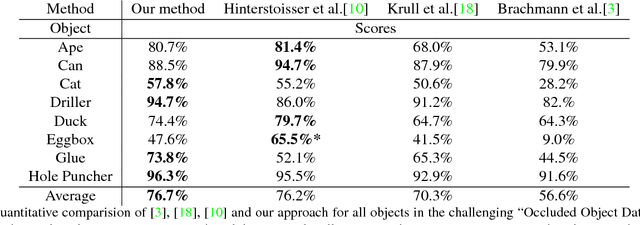
This paper addresses the task of estimating the 6D pose of a known 3D object from a single RGB-D image. Most modern approaches solve this task in three steps: i) Compute local features; ii) Generate a pool of pose-hypotheses; iii) Select and refine a pose from the pool. This work focuses on the second step. While all existing approaches generate the hypotheses pool via local reasoning, e.g. RANSAC or Hough-voting, we are the first to show that global reasoning is beneficial at this stage. In particular, we formulate a novel fully-connected Conditional Random Field (CRF) that outputs a very small number of pose-hypotheses. Despite the potential functions of the CRF being non-Gaussian, we give a new and efficient two-step optimization procedure, with some guarantees for optimality. We utilize our global hypotheses generation procedure to produce results that exceed state-of-the-art for the challenging "Occluded Object Dataset".
Learning Analysis-by-Synthesis for 6D Pose Estimation in RGB-D Images
Aug 19, 2015
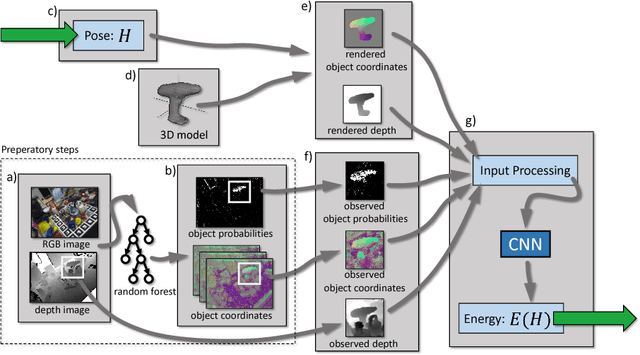

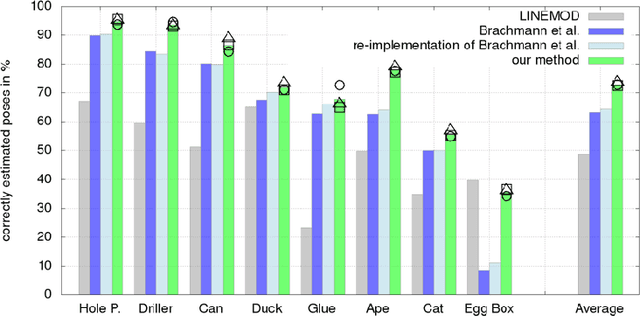
Analysis-by-synthesis has been a successful approach for many tasks in computer vision, such as 6D pose estimation of an object in an RGB-D image which is the topic of this work. The idea is to compare the observation with the output of a forward process, such as a rendered image of the object of interest in a particular pose. Due to occlusion or complicated sensor noise, it can be difficult to perform this comparison in a meaningful way. We propose an approach that "learns to compare", while taking these difficulties into account. This is done by describing the posterior density of a particular object pose with a convolutional neural network (CNN) that compares an observed and rendered image. The network is trained with the maximum likelihood paradigm. We observe empirically that the CNN does not specialize to the geometry or appearance of specific objects, and it can be used with objects of vastly different shapes and appearances, and in different backgrounds. Compared to state-of-the-art, we demonstrate a significant improvement on two different datasets which include a total of eleven objects, cluttered background, and heavy occlusion.