 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Video-To-Speech Synthesis using Generative Adversarial Networks
Apr 30, 2021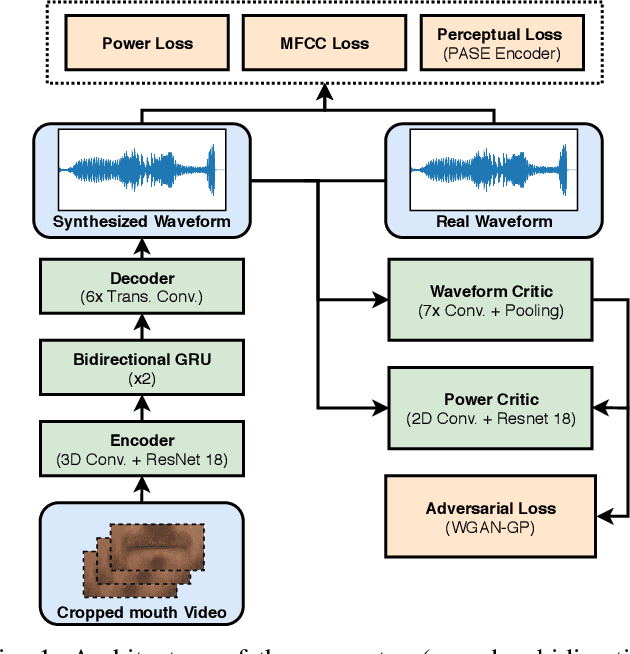
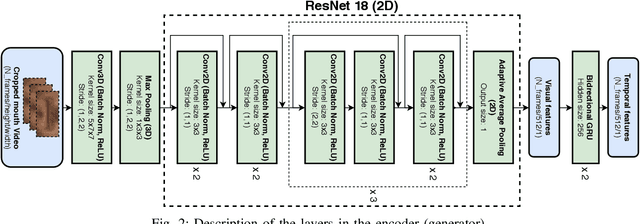
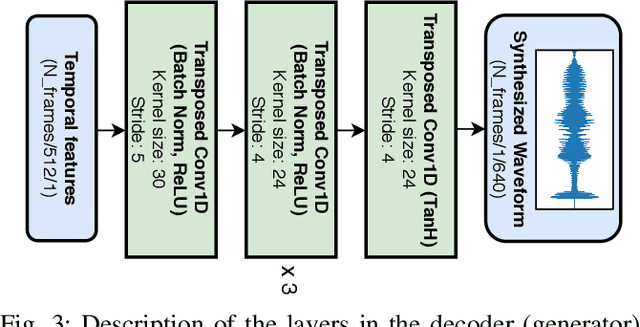
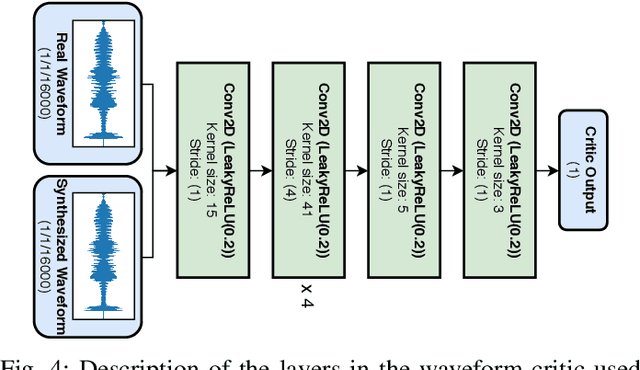
Video-to-speech is the process of reconstructing the audio speech from a video of a spoken utterance. Previous approaches to this task have relied on a two-step process where an intermediate representation is inferred from the video, and is then decoded into waveform audio using a vocoder or a waveform reconstruction algorithm. In this work, we propose a new end-to-end video-to-speech model based on Generative Adversarial Networks (GANs) which translates spoken video to waveform end-to-end without using any intermediate representation or separate waveform synthesis algorithm. Our model consists of an encoder-decoder architecture that receives raw video as input and generates speech, which is then fed to a waveform critic and a power critic. The use of an adversarial loss based on these two critics enables the direct synthesis of raw audio waveform and ensures its realism. In addition, the use of our three comparative losses helps establish direct correspondence between the generated audio and the input video. We show that this model is able to reconstruct speech with remarkable realism for constrained datasets such as GRID, and that it is the first end-to-end model to produce intelligible speech for LRW (Lip Reading in the Wild), featuring hundreds of speakers recorded entirely `in the wild'. We evaluate the generated samples in two different scenarios -- seen and unseen speakers -- using four objective metrics which measure the quality and intelligibility of artificial speech. We demonstrate that the proposed approach outperforms all previous works in most metrics on GRID and LRW.
DINO: A Conditional Energy-Based GAN for Domain Translation
Feb 18, 2021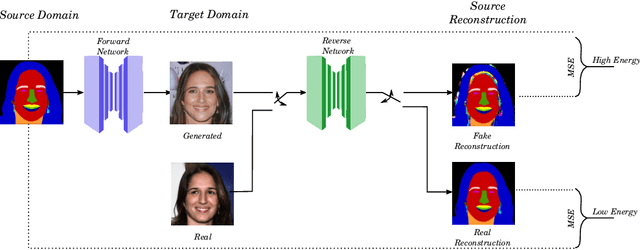

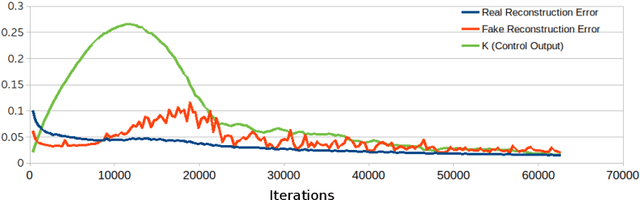
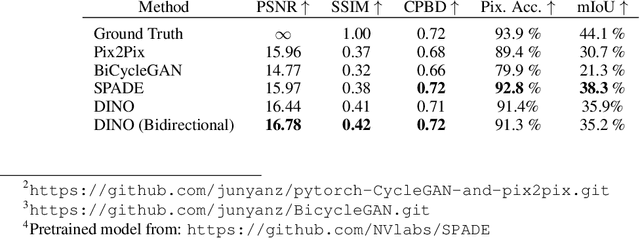
Domain translation is the process of transforming data from one domain to another while preserving the common semantics. Some of the most popular domain translation systems are based on conditional generative adversarial networks, which use source domain data to drive the generator and as an input to the discriminator. However, this approach does not enforce the preservation of shared semantics since the conditional input can often be ignored by the discriminator. We propose an alternative method for conditioning and present a new framework, where two networks are simultaneously trained, in a supervised manner, to perform domain translation in opposite directions. Our method is not only better at capturing the shared information between two domains but is more generic and can be applied to a broader range of problems. The proposed framework performs well even in challenging cross-modal translations, such as video-driven speech reconstruction, for which other systems struggle to maintain correspondence.
End-to-end Audio-visual Speech Recognition with Conformers
Feb 12, 2021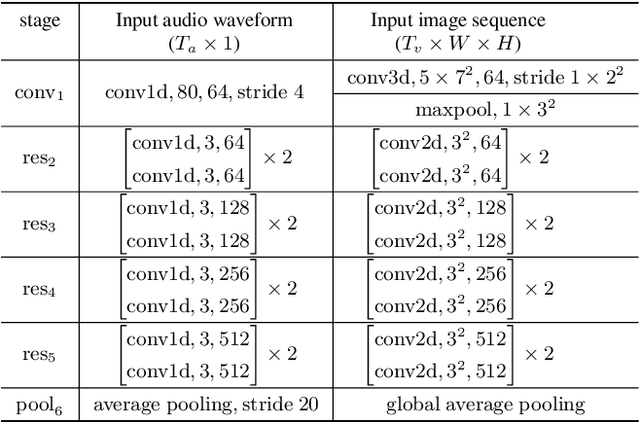
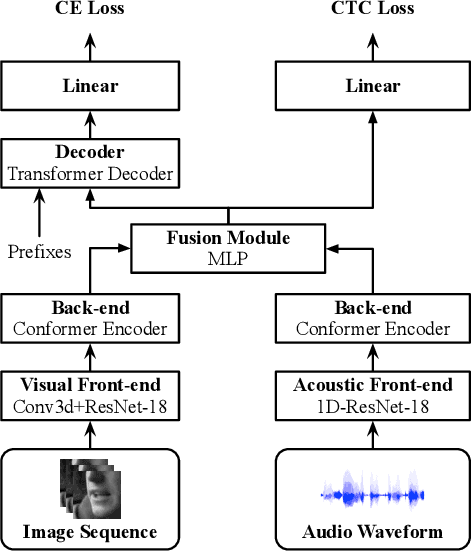

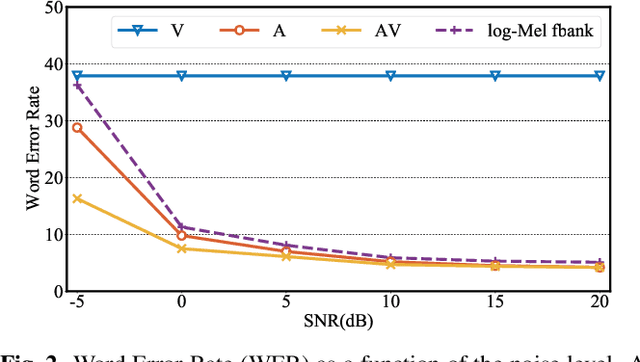
In this work, we present a hybrid CTC/Attention model based on a ResNet-18 and Convolution-augmented transformer (Conformer), that can be trained in an end-to-end manner. In particular, the audio and visual encoders learn to extract features directly from raw pixels and audio waveforms, respectively, which are then fed to conformers and then fusion takes place via a Multi-Layer Perceptron (MLP). The model learns to recognise characters using a combination of CTC and an attention mechanism. We show that end-to-end training, instead of using pre-computed visual features which is common in the literature, the use of a conformer, instead of a recurrent network, and the use of a transformer-based language model, significantly improve the performance of our model. We present results on the largest publicly available datasets for sentence-level speech recognition, Lip Reading Sentences 2 (LRS2) and Lip Reading Sentences 3 (LRS3), respectively. The results show that our proposed models raise the state-of-the-art performance by a large margin in audio-only, visual-only, and audio-visual experiments.
Lips Don't Lie: A Generalisable and Robust Approach to Face Forgery Detection
Dec 14, 2020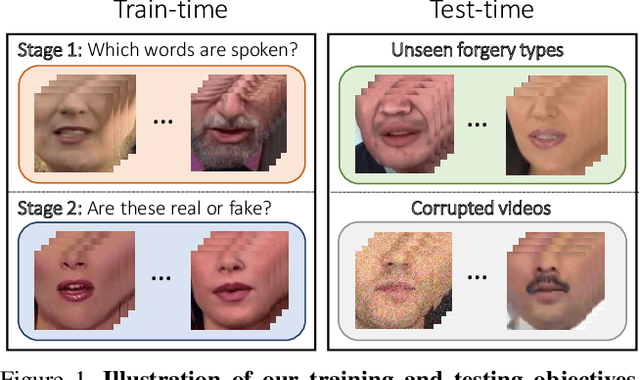
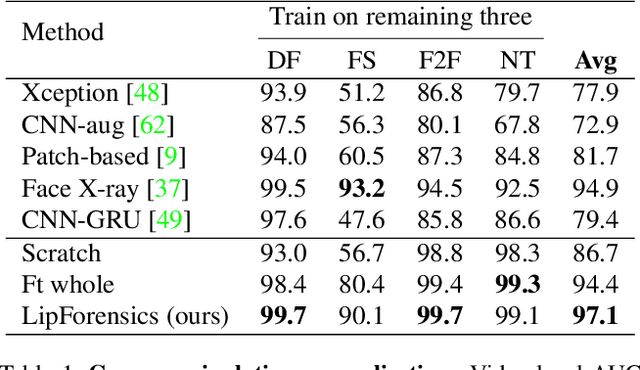
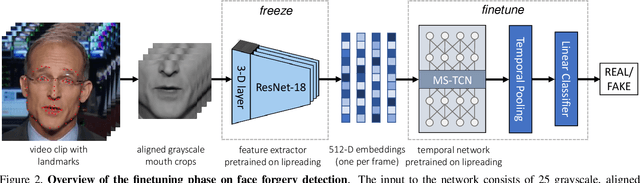
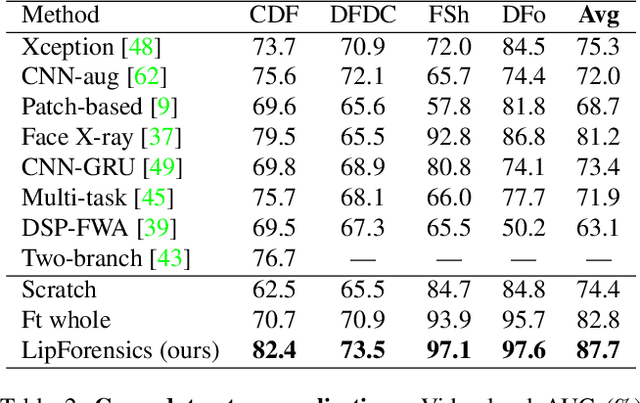
Although current deep learning-based face forgery detectors achieve impressive performance in constrained scenarios, they are vulnerable to samples created by unseen manipulation methods. Some recent works show improvements in generalisation but rely on cues that are easily corrupted by common post-processing operations such as compression. In this paper, we propose LipForensics, a detection approach capable of both generalising to novel manipulations and withstanding various distortions. LipForensics targets high-level semantic irregularities in mouth movements, which are common in many generated videos. It consists in first pretraining a spatio-temporal network to perform visual speech recognition (lipreading), thus learning rich internal representations related to natural mouth motion. A temporal network is subsequently finetuned on fixed mouth embeddings of real and forged data in order to detect fake videos based on mouth movements without overfitting to low-level, manipulation-specific artefacts. Extensive experiments show that this simple approach significantly surpasses the state-of-the-art in terms of generalisation to unseen manipulations and robustness to perturbations, as well as shed light on the factors responsible for its performance.
Domain Adversarial Neural Networks for Dysarthric Speech Recognition
Oct 07, 2020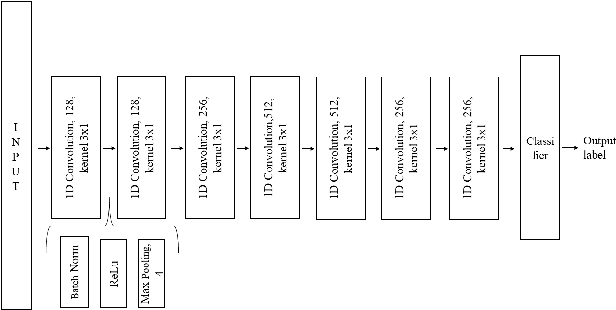
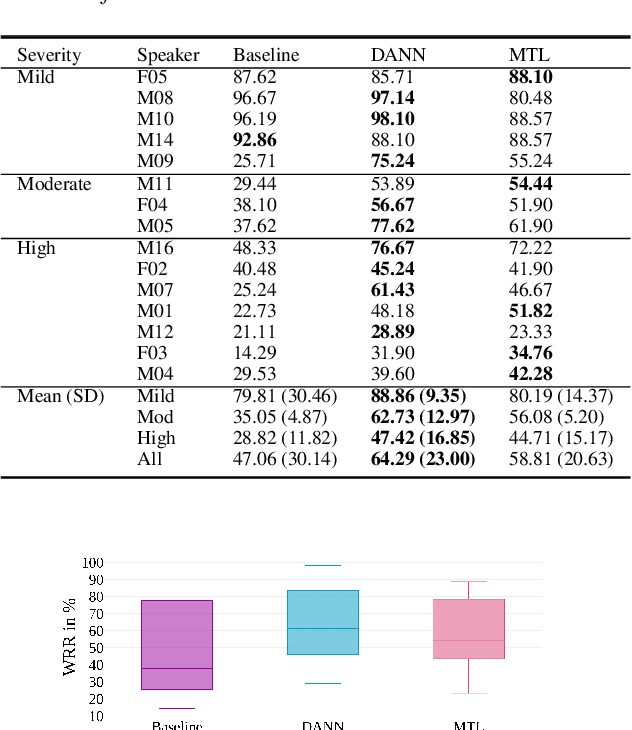
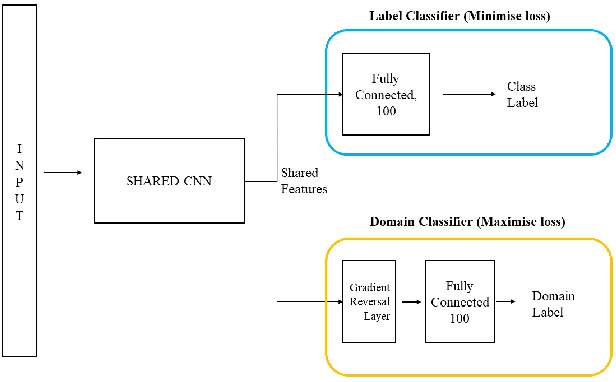
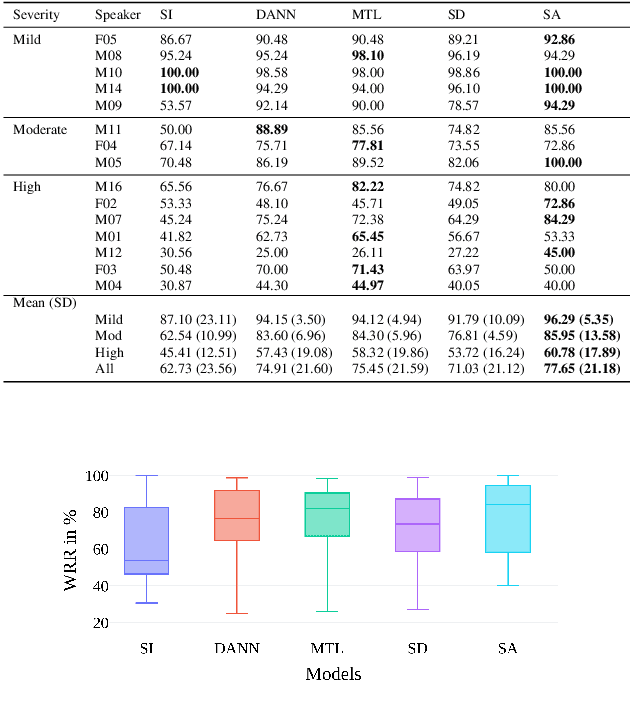
Speech recognition systems have improved dramatically over the last few years, however, their performance is significantly degraded for the cases of accented or impaired speech. This work explores domain adversarial neural networks (DANN) for speaker-independent speech recognition on the UAS dataset of dysarthric speech. The classification task on 10 spoken digits is performed using an end-to-end CNN taking raw audio as input. The results are compared to a speaker-adaptive (SA) model as well as speaker-dependent (SD) and multi-task learning models (MTL). The experiments conducted in this paper show that DANN achieves an absolute recognition rate of 74.91% and outperforms the baseline by 12.18%. Additionally, the DANN model achieves comparable results to the SA model's recognition rate of 77.65%. We also observe that when labelled dysarthric speech data is available DANN and MTL perform similarly, but when they are not DANN performs better than MTL.
Lip-reading with Densely Connected Temporal Convolutional Networks
Sep 29, 2020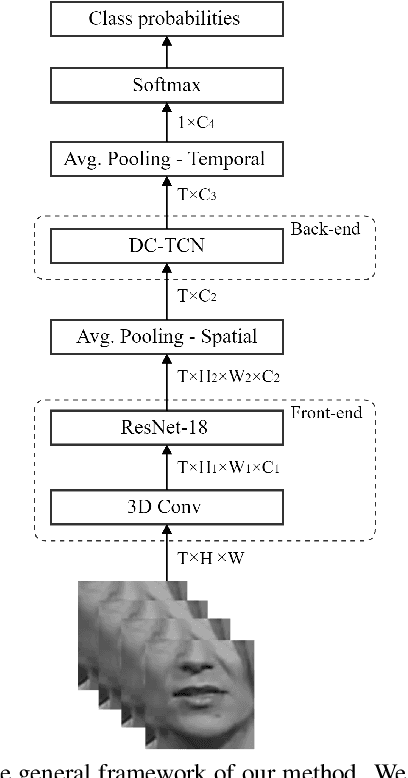
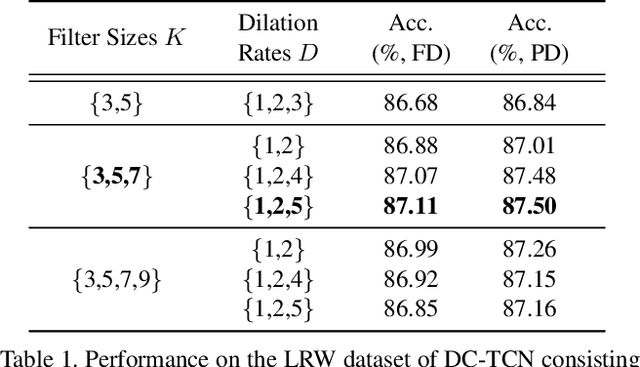
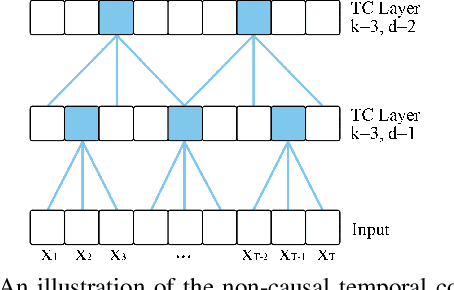
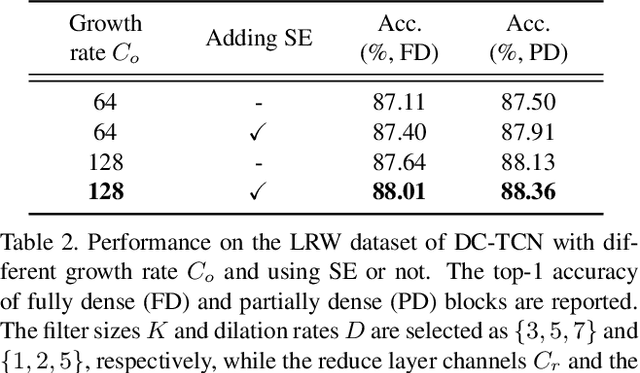
In this work, we present the Densely Connected Temporal Convolutional Network (DC-TCN) for lip-reading of isolated words. Although Temporal Convolutional Networks (TCN) have recently demonstrated great potential in many vision tasks, its receptive fields are not dense enough to model the complex temporal dynamics in lip-reading scenarios. To address this problem, we introduce dense connections into the network to capture more robust temporal features. Moreover, our approach utilises the Squeeze-and-Excitation block, a light-weight attention mechanism, to further enhance the model's classification power. Without bells and whistles, our DC-TCN method has achieved 88.36% accuracy on the Lip Reading in the Wild (LRW) dataset and 43.65% on the LRW-1000 dataset, which has surpassed all the baseline methods and is the new state-of-the-art on both datasets.
Towards practical lipreading with distilled and efficient models
Jul 13, 2020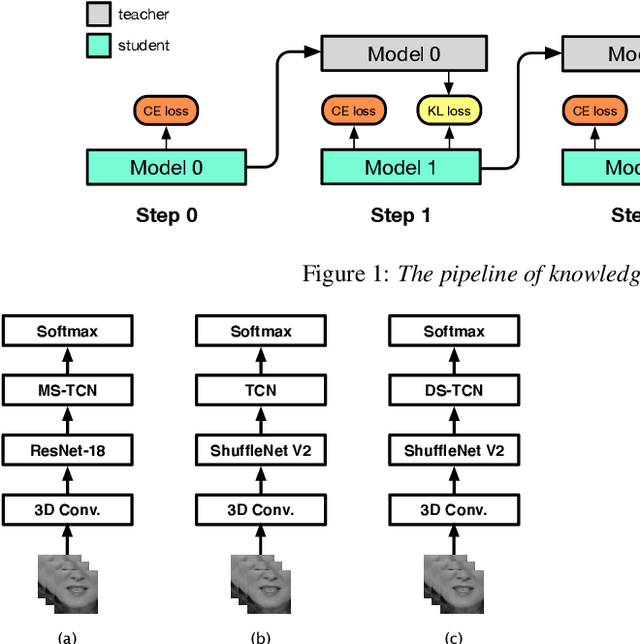
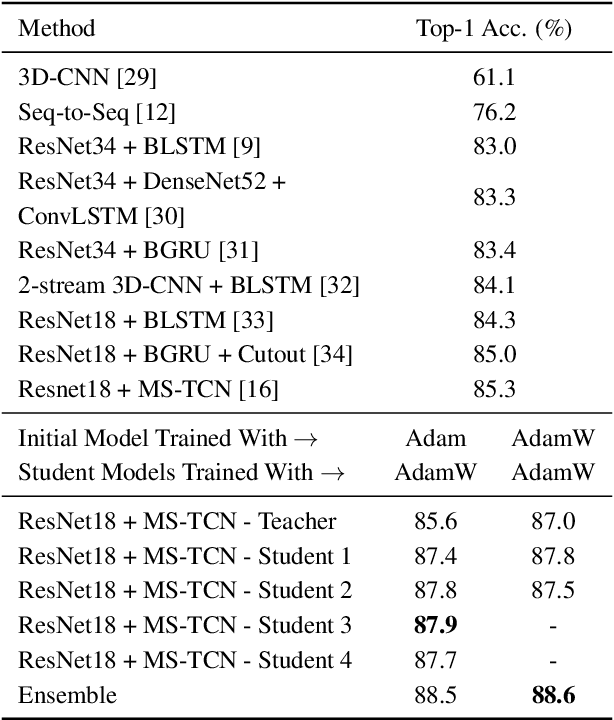
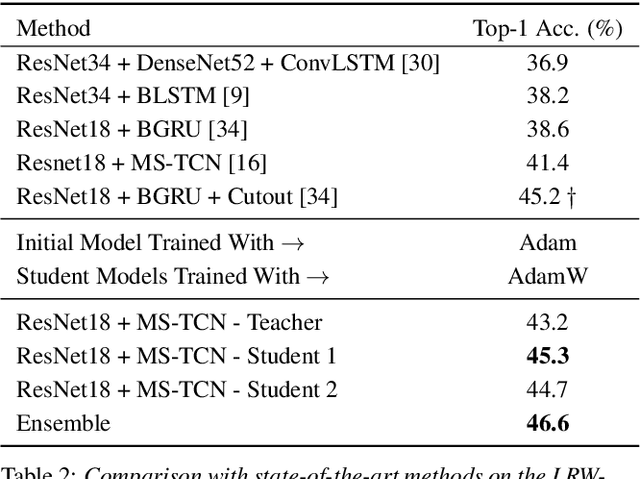
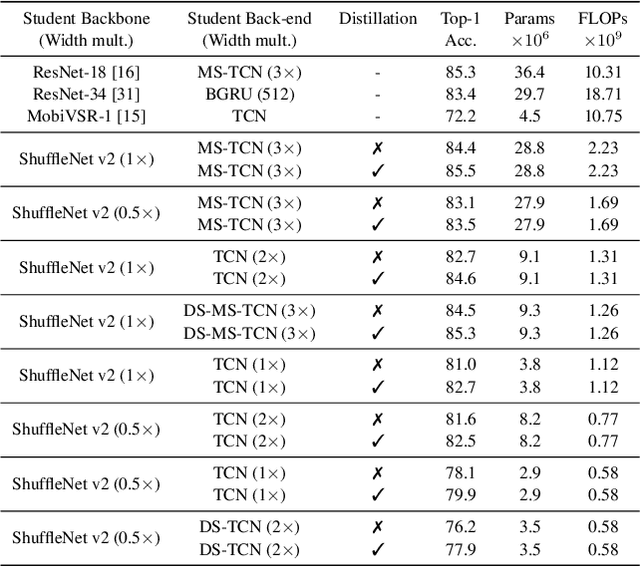
Lipreading has witnessed a lot of progress due to the resurgence of neural networks. Recent work has placed emphasis on aspects such as improving performance by finding the optimal architecture or improving generalization. However, there is still a significant gap between the current methodologies and the requirements for an effective deployment of lipreading in practical scenarios. In this work, we propose a series of innovations that significantly bridge that gap: first, we raise the state-of-the-art performance by a wide margin on LRW and LRW-1000 to 88.6% and 46.6%, respectively, through careful optimization. Secondly, we propose a series of architectural changes, including a novel depthwise-separable TCN head, that slashes the computational cost to a fraction of the (already quite efficient) original model. Thirdly, we show that knowledge distillation is a very effective tool for recovering performance of the lightweight models. This results in a range of models with different accuracy-efficiency trade-offs. However, our most promising lightweight models are on par with the current state-of-the-art while showing a reduction of 8 and 4x in terms of computational cost and number of parameters, respectively, which we hope will enable the deployment of lipreading models in practical applications.
Learning Speech Representations from Raw Audio by Joint Audiovisual Self-Supervision
Jul 08, 2020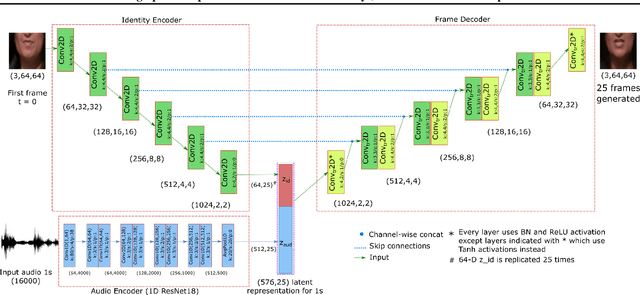
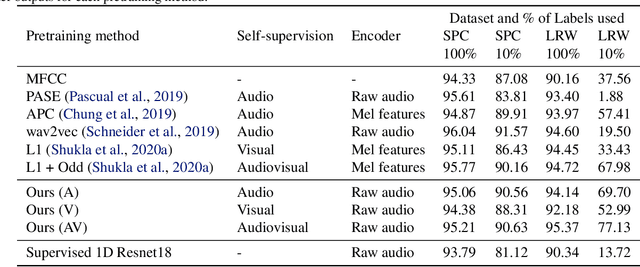
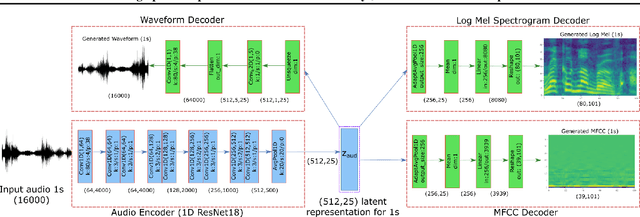
The intuitive interaction between the audio and visual modalities is valuable for cross-modal self-supervised learning. This concept has been demonstrated for generic audiovisual tasks like video action recognition and acoustic scene classification. However, self-supervision remains under-explored for audiovisual speech. We propose a method to learn self-supervised speech representations from the raw audio waveform. We train a raw audio encoder by combining audio-only self-supervision (by predicting informative audio attributes) with visual self-supervision (by generating talking faces from audio). The visual pretext task drives the audio representations to capture information related to lip movements. This enriches the audio encoder with visual information and the encoder can be used for evaluation without the visual modality. Our method attains competitive performance with respect to existing self-supervised audio features on established isolated word classification benchmarks, and significantly outperforms other methods at learning from fewer labels. Notably, our method also outperforms fully supervised training, thus providing a strong initialization for speech related tasks. Our results demonstrate the potential of multimodal self-supervision in audiovisual speech for learning good audio representations.
Does Visual Self-Supervision Improve Learning of Speech Representations?
May 04, 2020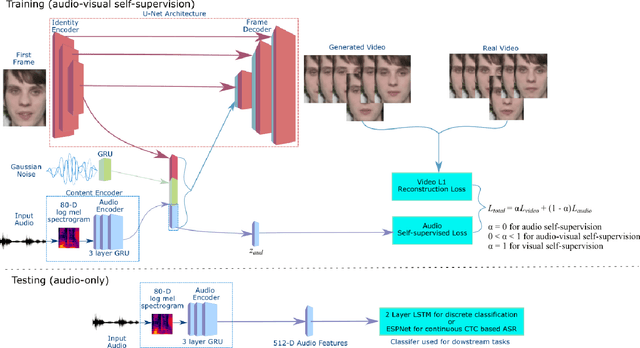
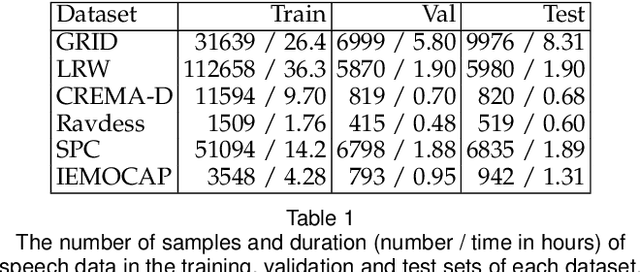
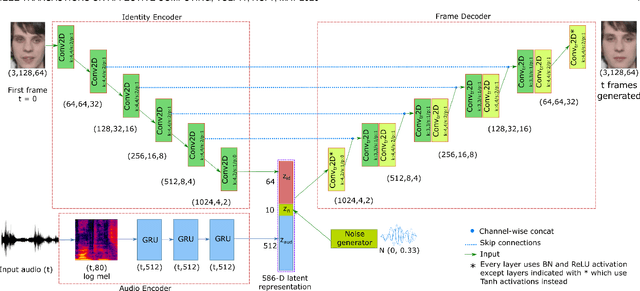
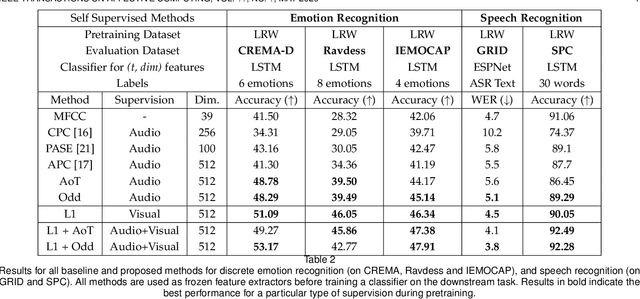
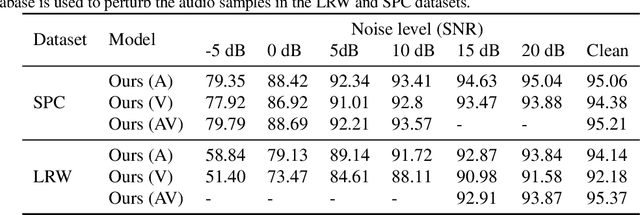
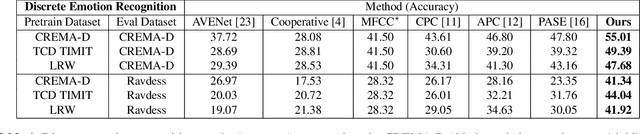
Self-supervised learning has attracted plenty of recent research interest. However, most works are typically unimodal and there has been limited work that studies the interaction between audio and visual modalities for self-supervised learning. This work (1) investigates visual self-supervision via face reconstruction to guide the learning of audio representations; (2) proposes two audio-only self-supervision approaches for speech representation learning; (3) shows that a multi-task combination of the proposed visual and audio self-supervision is beneficial for learning richer features that are more robust in noisy conditions; (4) shows that self-supervised pretraining leads to a superior weight initialization, which is especially useful to prevent overfitting and lead to faster model convergence on smaller sized datasets. We evaluate our audio representations for emotion and speech recognition, achieving state of the art performance for both problems. Our results demonstrate the potential of visual self-supervision for audio feature learning and suggest that joint visual and audio self-supervision leads to more informative speech representations.
Visually Guided Self Supervised Learning of Speech Representations
Feb 20, 2020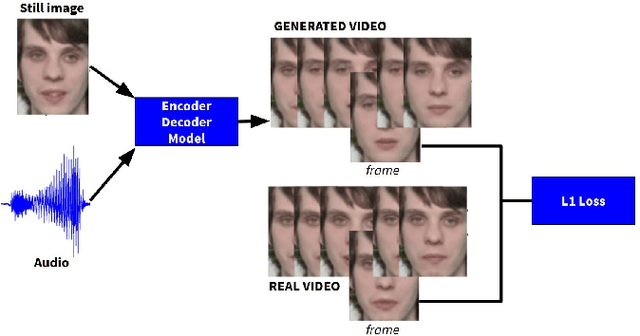
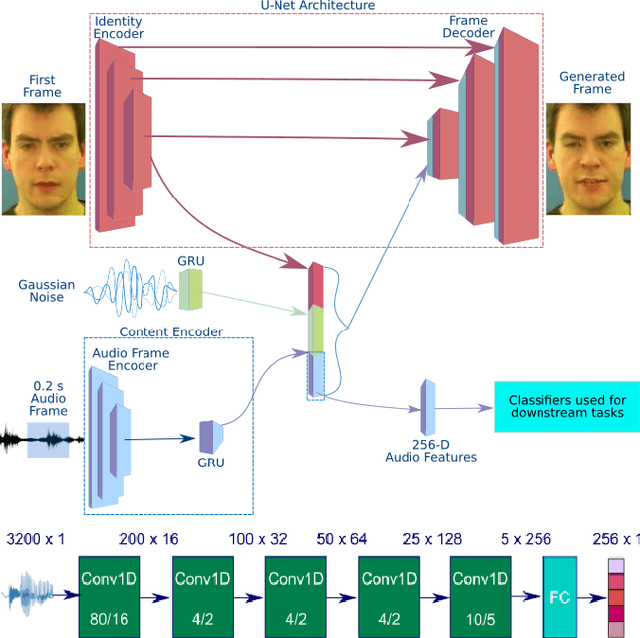
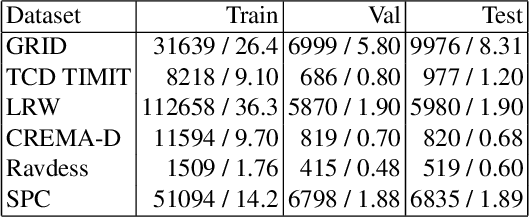
Self supervised representation learning has recently attracted a lot of research interest for both the audio and visual modalities. However, most works typically focus on a particular modality or feature alone and there has been very limited work that studies the interaction between the two modalities for learning self supervised representations. We propose a framework for learning audio representations guided by the visual modality in the context of audiovisual speech. We employ a generative audio-to-video training scheme in which we animate a still image corresponding to a given audio clip and optimize the generated video to be as close as possible to the real video of the speech segment. Through this process, the audio encoder network learns useful speech representations that we evaluate on emotion recognition and speech recognition. We achieve state of the art results for emotion recognition and competitive results for speech recognition. This demonstrates the potential of visual supervision for learning audio representations as a novel way for self-supervised learning which has not been explored in the past. The proposed unsupervised audio features can leverage a virtually unlimited amount of training data of unlabelled audiovisual speech and have a large number of potentially promising applications.