 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeNet: A Light Weight Model for Low Bitrate Image Compression
Dec 18, 2025



Reducing computational complexity remains a critical challenge for the widespread adoption of learning-based image compression techniques. In this work, we propose TreeNet, a novel low-complexity image compression model that leverages a binary tree-structured encoder-decoder architecture to achieve efficient representation and reconstruction. We employ attentional feature fusion mechanism to effectively integrate features from multiple branches. We evaluate TreeNet on three widely used benchmark datasets and compare its performance against competing methods including JPEG AI, a recent standard in learning-based image compression. At low bitrates, TreeNet achieves an average improvement of 4.83% in BD-rate over JPEG AI, while reducing model complexity by 87.82%. Furthermore, we conduct extensive ablation studies to investigate the influence of various latent representations within TreeNet, offering deeper insights into the factors contributing to reconstruction.
A Study on the Effect of Color Spaces in Learned Image Compression
Jun 19, 2024



In this work, we present a comparison between color spaces namely YUV, LAB, RGB and their effect on learned image compression. For this we use the structure and color based learned image codec (SLIC) from our prior work, which consists of two branches - one for the luminance component (Y or L) and another for chrominance components (UV or AB). However, for the RGB variant we input all 3 channels in a single branch, similar to most learned image codecs operating in RGB. The models are trained for multiple bitrate configurations in each color space. We report the findings from our experiments by evaluating them on various datasets and compare the results to state-of-the-art image codecs. The YUV model performs better than the LAB variant in terms of MS-SSIM with a Bj{\o}ntegaard delta bitrate (BD-BR) gain of 7.5\% using VTM intra-coding mode as the baseline. Whereas the LAB variant has a better performance than YUV model in terms of CIEDE2000 having a BD-BR gain of 8\%. Overall, the RGB variant of SLIC achieves the best performance with a BD-BR gain of 13.14\% in terms of MS-SSIM and a gain of 17.96\% in CIEDE2000 at the cost of a higher model complexity.
Efficient Learned Wavelet Image and Video Coding
May 21, 2024



Learned wavelet image and video coding approaches provide an explainable framework with a latent space corresponding to a wavelet decomposition. The wavelet image coder iWave++ achieves state-of-the-art performance and has been employed for various compression tasks, including lossy as well as lossless image, video, and medical data compression. However, the approaches suffer from slow decoding speed due to the autoregressive context model used in iWave++. In this paper, we show how a parallelized context model can be integrated into the iWave++ framework. Our experimental results demonstrate a speedup factor of over 350 and 240 for image and video compression, respectively. At the same time, the rate-distortion performance in terms of Bj{\o}ntegaard delta bitrate is slightly worse by 1.5\% for image coding and 1\% for video coding. In addition, we analyze the learned wavelet decomposition by visualizing its subband impulse responses.
SLIC: A Learned Image Codec Using Structure and Color
Jan 30, 2024



We propose the structure and color based learned image codec (SLIC) in which the task of compression is split into that of luminance and chrominance. The deep learning model is built with a novel multi-scale architecture for Y and UV channels in the encoder, where the features from various stages are combined to obtain the latent representation. An autoregressive context model is employed for backward adaptation and a hyperprior block for forward adaptation. Various experiments are carried out to study and analyze the performance of the proposed model, and to compare it with other image codecs. We also illustrate the advantages of our method through the visualization of channel impulse responses, latent channels and various ablation studies. The model achieves Bj{\o}ntegaard delta bitrate gains of 7.5% and 4.66% in terms of MS-SSIM and CIEDE2000 metrics with respect to other state-of-the-art reference codecs.
Color Learning for Image Compression
Jun 30, 2023



Deep learning based image compression has gained a lot of momentum in recent times. To enable a method that is suitable for image compression and subsequently extended to video compression, we propose a novel deep learning model architecture, where the task of image compression is divided into two sub-tasks, learning structural information from luminance channel and color from chrominance channels. The model has two separate branches to process the luminance and chrominance components. The color difference metric CIEDE2000 is employed in the loss function to optimize the model for color fidelity. We demonstrate the benefits of our approach and compare the performance to other codecs. Additionally, the visualization and analysis of latent channel impulse response is performed.
Compressive Online Robust Principal Component Analysis with Optical Flow for Video Foreground-Background Separation
Oct 25, 2017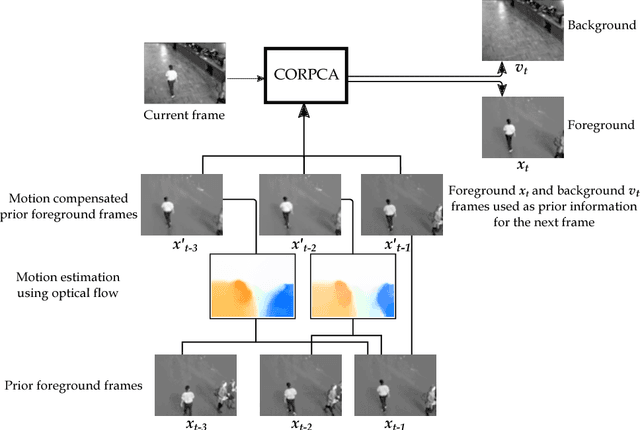
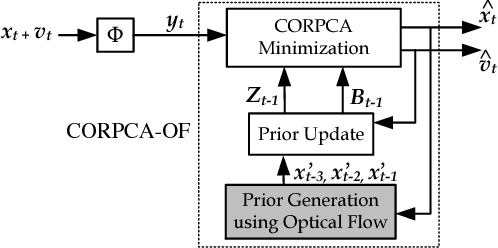
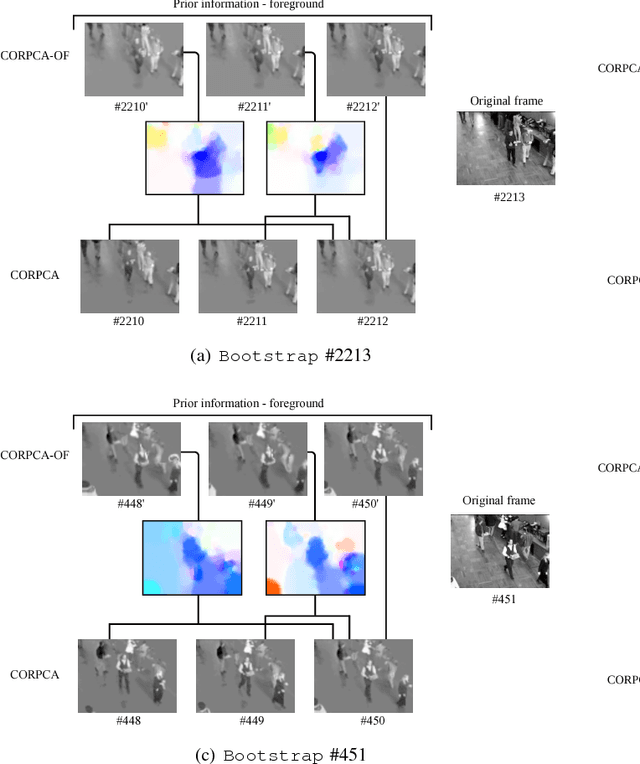

In the context of online Robust Principle Component Analysis (RPCA) for the video foreground-background separation, we propose a compressive online RPCA with optical flow that separates recursively a sequence of frames into sparse (foreground) and low-rank (background) components. Our method considers a small set of measurements taken per data vector (frame), which is different from conventional batch RPCA, processing all the data directly. The proposed method also incorporates multiple prior information, namely previous foreground and background frames, to improve the separation and then updates the prior information for the next frame. Moreover, the foreground prior frames are improved by estimating motions between the previous foreground frames using optical flow and compensating the motions to achieve higher quality foreground prior. The proposed method is applied to online video foreground and background separation from compressive measurements. The visual and quantitative results show that our method outperforms the existing methods.