 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Guided Camera Motion Understanding in VideoLLMs
Mar 13, 2026Camera motion is a fundamental geometric signal that shapes visual perception and cinematic style, yet current video-capable vision-language models (VideoLLMs) rarely represent it explicitly and often fail on fine-grained motion primitives. We address this gap with a framework of $\textbf{benchmarking}$, $\textbf{diagnosis}$, and $\textbf{injection}$. We curate $\textbf{CameraMotionDataset}$, a large-scale synthetic dataset with explicit camera control, formulate camera motion as constraint-aware multi-label recognition, and construct a VQA benchmark--$\textbf{CameraMotionVQA}$. Across diverse off-the-shelf VideoLLMs, we observe substantial errors in recognizing camera motion primitives. Probing experiments on a Qwen2.5-VL vision encoder suggest that camera motion cues are weakly represented, especially in deeper ViT blocks, helping explain the observed failure modes. To bridge this gap without costly training or fine-tuning, we propose a lightweight, model-agnostic pipeline that extracts geometric camera cues from 3D foundation models (3DFMs), predicts constrained motion primitives with a temporal classifier, and injects them into downstream VideoLLM inference via structured prompting. Experiments demonstrate improved motion recognition and more camera-aware model responses, highlighting geometry-driven cue extraction and structured prompting as practical steps toward a camera-aware VideoLLM and VLA system. The dataset and benchmark is publicly available at https://hf.co/datasets/fengyee/camera-motion-dataset-and-benchmark.
AE-StyleGAN: Improved Training of Style-Based Auto-Encoders
Oct 17, 2021
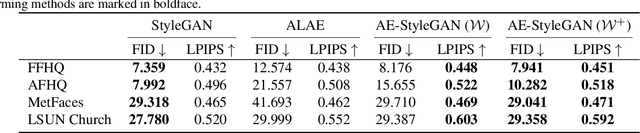

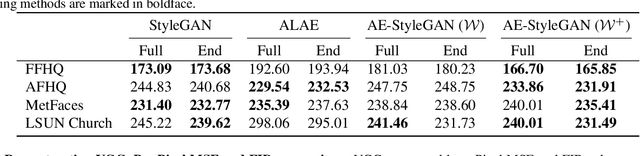
StyleGANs have shown impressive results on data generation and manipulation in recent years, thanks to its disentangled style latent space. A lot of efforts have been made in inverting a pretrained generator, where an encoder is trained ad hoc after the generator is trained in a two-stage fashion. In this paper, we focus on style-based generators asking a scientific question: Does forcing such a generator to reconstruct real data lead to more disentangled latent space and make the inversion process from image to latent space easy? We describe a new methodology to train a style-based autoencoder where the encoder and generator are optimized end-to-end. We show that our proposed model consistently outperforms baselines in terms of image inversion and generation quality. Supplementary, code, and pretrained models are available on the project website.