 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Safety Training of LLMs Generalize to Semantically Related Natural Prompts?
Dec 04, 2024



Large Language Models (LLMs) are known to be susceptible to crafted adversarial attacks or jailbreaks that lead to the generation of objectionable content despite being aligned to human preferences using safety fine-tuning methods. While the large dimensionality of input token space makes it inevitable to find adversarial prompts that can jailbreak these models, we aim to evaluate whether safety fine-tuned LLMs are safe against natural prompts which are semantically related to toxic seed prompts that elicit safe responses after alignment. We surprisingly find that popular aligned LLMs such as GPT-4 can be compromised using naive prompts that are NOT even crafted with an objective of jailbreaking the model. Furthermore, we empirically show that given a seed prompt that elicits a toxic response from an unaligned model, one can systematically generate several semantically related natural prompts that can jailbreak aligned LLMs. Towards this, we propose a method of Response Guided Question Augmentation (ReG-QA) to evaluate the generalization of safety aligned LLMs to natural prompts, that first generates several toxic answers given a seed question using an unaligned LLM (Q to A), and further leverages an LLM to generate questions that are likely to produce these answers (A to Q). We interestingly find that safety fine-tuned LLMs such as GPT-4o are vulnerable to producing natural jailbreak questions from unsafe content (without denial) and can thus be used for the latter (A to Q) step. We obtain attack success rates that are comparable to/ better than leading adversarial attack methods on the JailbreakBench leaderboard, while being significantly more stable against defenses such as Smooth-LLM and Synonym Substitution, which are effective against existing all attacks on the leaderboard.
* Accepted at the Safe Generative AI Workshop @ NeurIPS 2024
Time-Reversal Provides Unsupervised Feedback to LLMs
Dec 03, 2024



Large Language Models (LLMs) are typically trained to predict in the forward direction of time. However, recent works have shown that prompting these models to look back and critique their own generations can produce useful feedback. Motivated by this, we explore the question of whether LLMs can be empowered to think (predict and score) backwards to provide unsupervised feedback that complements forward LLMs. Towards this, we introduce Time Reversed Language Models (TRLMs), which can score and generate queries when conditioned on responses, effectively functioning in the reverse direction of time. Further, to effectively infer in the response to query direction, we pre-train and fine-tune a language model (TRLM-Ba) in the reverse token order from scratch. We show empirically (and theoretically in a stylized setting) that time-reversed models can indeed complement forward model predictions when used to score the query given response for re-ranking multiple forward generations. We obtain up to 5\% improvement on the widely used AlpacaEval Leaderboard over the competent baseline of best-of-N re-ranking using self log-perplexity scores. We further show that TRLM scoring outperforms conventional forward scoring of response given query, resulting in significant gains in applications such as citation generation and passage retrieval. We next leverage the generative ability of TRLM to augment or provide unsupervised feedback to input safety filters of LLMs, demonstrating a drastic reduction in false negative rate with negligible impact on false positive rates against several attacks published on the popular JailbreakBench leaderboard.
ProFeAT: Projected Feature Adversarial Training for Self-Supervised Learning of Robust Representations
Jun 09, 2024



The need for abundant labelled data in supervised Adversarial Training (AT) has prompted the use of Self-Supervised Learning (SSL) techniques with AT. However, the direct application of existing SSL methods to adversarial training has been sub-optimal due to the increased training complexity of combining SSL with AT. A recent approach, DeACL, mitigates this by utilizing supervision from a standard SSL teacher in a distillation setting, to mimic supervised AT. However, we find that there is still a large performance gap when compared to supervised adversarial training, specifically on larger models. In this work, investigate the key reason for this gap and propose Projected Feature Adversarial Training (ProFeAT) to bridge the same. We show that the sub-optimal distillation performance is a result of mismatch in training objectives of the teacher and student, and propose to use a projection head at the student, that allows it to leverage weak supervision from the teacher while also being able to learn adversarially robust representations that are distinct from the teacher. We further propose appropriate attack and defense losses at the feature and projector, alongside a combination of weak and strong augmentations for the teacher and student respectively, to improve the training data diversity without increasing the training complexity. Through extensive experiments on several benchmark datasets and models, we demonstrate significant improvements in both clean and robust accuracy when compared to existing SSL-AT methods, setting a new state-of-the-art. We further report on-par/ improved performance when compared to TRADES, a popular supervised-AT method.
Distilling from Vision-Language Models for Improved OOD Generalization in Vision Tasks
Oct 12, 2023Vision-Language Models (VLMs) such as CLIP are trained on large amounts of image-text pairs, resulting in remarkable generalization across several data distributions. The prohibitively expensive training and data collection/curation costs of these models make them valuable Intellectual Property (IP) for organizations. This motivates a vendor-client paradigm, where a vendor trains a large-scale VLM and grants only input-output access to clients on a pay-per-query basis in a black-box setting. The client aims to minimize inference cost by distilling the VLM to a student model using the limited available task-specific data, and further deploying this student model in the downstream application. While naive distillation largely improves the In-Domain (ID) accuracy of the student, it fails to transfer the superior out-of-distribution (OOD) generalization of the VLM teacher using the limited available labeled images. To mitigate this, we propose Vision-Language to Vision-Align, Distill, Predict (VL2V-ADiP), which first aligns the vision and language modalities of the teacher model with the vision modality of a pre-trained student model, and further distills the aligned VLM embeddings to the student. This maximally retains the pre-trained features of the student, while also incorporating the rich representations of the VLM image encoder and the superior generalization of the text embeddings. The proposed approach achieves state-of-the-art results on the standard Domain Generalization benchmarks in a black-box teacher setting, and also when weights of the VLM are accessible.
Boosting Adversarial Robustness using Feature Level Stochastic Smoothing
Jun 10, 2023


Advances in adversarial defenses have led to a significant improvement in the robustness of Deep Neural Networks. However, the robust accuracy of present state-ofthe-art defenses is far from the requirements in critical applications such as robotics and autonomous navigation systems. Further, in practical use cases, network prediction alone might not suffice, and assignment of a confidence value for the prediction can prove crucial. In this work, we propose a generic method for introducing stochasticity in the network predictions, and utilize this for smoothing decision boundaries and rejecting low confidence predictions, thereby boosting the robustness on accepted samples. The proposed Feature Level Stochastic Smoothing based classification also results in a boost in robustness without rejection over existing adversarial training methods. Finally, we combine the proposed method with adversarial detection methods, to achieve the benefits of both approaches.
Certified Adversarial Robustness Within Multiple Perturbation Bounds
Apr 20, 2023



Randomized smoothing (RS) is a well known certified defense against adversarial attacks, which creates a smoothed classifier by predicting the most likely class under random noise perturbations of inputs during inference. While initial work focused on robustness to $\ell_2$ norm perturbations using noise sampled from a Gaussian distribution, subsequent works have shown that different noise distributions can result in robustness to other $\ell_p$ norm bounds as well. In general, a specific noise distribution is optimal for defending against a given $\ell_p$ norm based attack. In this work, we aim to improve the certified adversarial robustness against multiple perturbation bounds simultaneously. Towards this, we firstly present a novel \textit{certification scheme}, that effectively combines the certificates obtained using different noise distributions to obtain optimal results against multiple perturbation bounds. We further propose a novel \textit{training noise distribution} along with a \textit{regularized training scheme} to improve the certification within both $\ell_1$ and $\ell_2$ perturbation norms simultaneously. Contrary to prior works, we compare the certified robustness of different training algorithms across the same natural (clean) accuracy, rather than across fixed noise levels used for training and certification. We also empirically invalidate the argument that training and certifying the classifier with the same amount of noise gives the best results. The proposed approach achieves improvements on the ACR (Average Certified Radius) metric across both $\ell_1$ and $\ell_2$ perturbation bounds.
DART: Diversify-Aggregate-Repeat Training Improves Generalization of Neural Networks
Feb 28, 2023



Generalization of neural networks is crucial for deploying them safely in the real world. Common training strategies to improve generalization involve the use of data augmentations, ensembling and model averaging. In this work, we first establish a surprisingly simple but strong benchmark for generalization which utilizes diverse augmentations within a training minibatch, and show that this can learn a more balanced distribution of features. Further, we propose Diversify-Aggregate-Repeat Training (DART) strategy that first trains diverse models using different augmentations (or domains) to explore the loss basin, and further Aggregates their weights to combine their expertise and obtain improved generalization. We find that Repeating the step of Aggregation throughout training improves the overall optimization trajectory and also ensures that the individual models have a sufficiently low loss barrier to obtain improved generalization on combining them. We shed light on our approach by casting it in the framework proposed by Shen et al. and theoretically show that it indeed generalizes better. In addition to improvements in In- Domain generalization, we demonstrate SOTA performance on the Domain Generalization benchmarks in the popular DomainBed framework as well. Our method is generic and can easily be integrated with several base training algorithms to achieve performance gains.
Efficient and Effective Augmentation Strategy for Adversarial Training
Oct 27, 2022Adversarial training of Deep Neural Networks is known to be significantly more data-hungry when compared to standard training. Furthermore, complex data augmentations such as AutoAugment, which have led to substantial gains in standard training of image classifiers, have not been successful with Adversarial Training. We first explain this contrasting behavior by viewing augmentation during training as a problem of domain generalization, and further propose Diverse Augmentation-based Joint Adversarial Training (DAJAT) to use data augmentations effectively in adversarial training. We aim to handle the conflicting goals of enhancing the diversity of the training dataset and training with data that is close to the test distribution by using a combination of simple and complex augmentations with separate batch normalization layers during training. We further utilize the popular Jensen-Shannon divergence loss to encourage the joint learning of the diverse augmentations, thereby allowing simple augmentations to guide the learning of complex ones. Lastly, to improve the computational efficiency of the proposed method, we propose and utilize a two-step defense, Ascending Constraint Adversarial Training (ACAT), that uses an increasing epsilon schedule and weight-space smoothing to prevent gradient masking. The proposed method DAJAT achieves substantially better robustness-accuracy trade-off when compared to existing methods on the RobustBench Leaderboard on ResNet-18 and WideResNet-34-10. The code for implementing DAJAT is available here: https://github.com/val-iisc/DAJAT.
Towards Efficient and Effective Self-Supervised Learning of Visual Representations
Oct 18, 2022

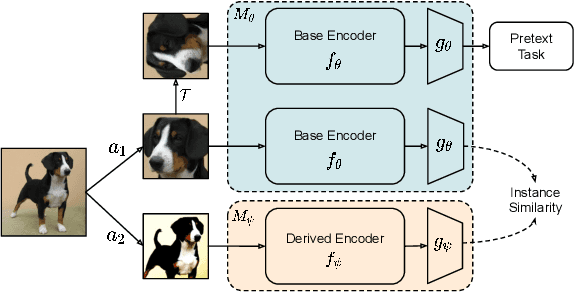
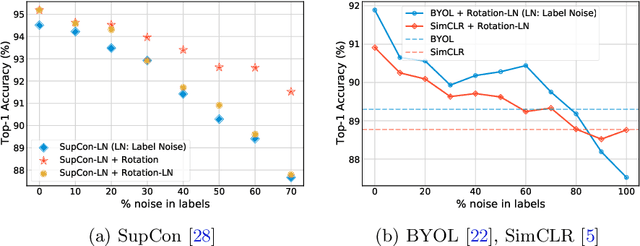
Self-supervision has emerged as a propitious method for visual representation learning after the recent paradigm shift from handcrafted pretext tasks to instance-similarity based approaches. Most state-of-the-art methods enforce similarity between various augmentations of a given image, while some methods additionally use contrastive approaches to explicitly ensure diverse representations. While these approaches have indeed shown promising direction, they require a significantly larger number of training iterations when compared to the supervised counterparts. In this work, we explore reasons for the slow convergence of these methods, and further propose to strengthen them using well-posed auxiliary tasks that converge significantly faster, and are also useful for representation learning. The proposed method utilizes the task of rotation prediction to improve the efficiency of existing state-of-the-art methods. We demonstrate significant gains in performance using the proposed method on multiple datasets, specifically for lower training epochs.
Scaling Adversarial Training to Large Perturbation Bounds
Oct 18, 2022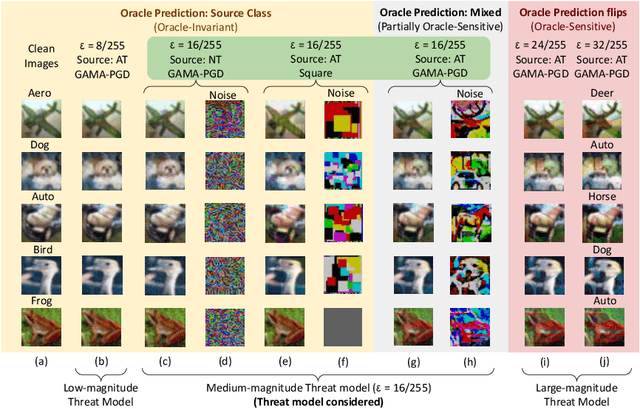
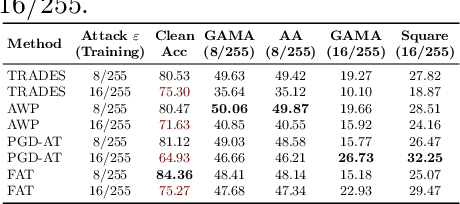
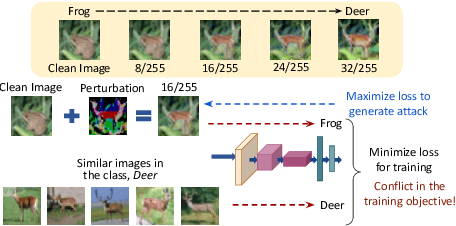
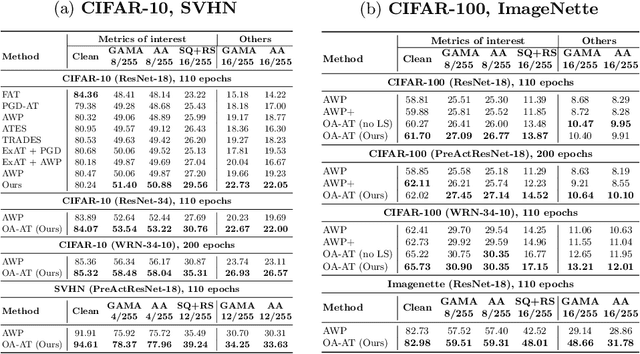
The vulnerability of Deep Neural Networks to Adversarial Attacks has fuelled research towards building robust models. While most Adversarial Training algorithms aim at defending attacks constrained within low magnitude Lp norm bounds, real-world adversaries are not limited by such constraints. In this work, we aim to achieve adversarial robustness within larger bounds, against perturbations that may be perceptible, but do not change human (or Oracle) prediction. The presence of images that flip Oracle predictions and those that do not makes this a challenging setting for adversarial robustness. We discuss the ideal goals of an adversarial defense algorithm beyond perceptual limits, and further highlight the shortcomings of naively extending existing training algorithms to higher perturbation bounds. In order to overcome these shortcomings, we propose a novel defense, Oracle-Aligned Adversarial Training (OA-AT), to align the predictions of the network with that of an Oracle during adversarial training. The proposed approach achieves state-of-the-art performance at large epsilon bounds (such as an L-inf bound of 16/255 on CIFAR-10) while outperforming existing defenses (AWP, TRADES, PGD-AT) at standard bounds (8/255) as well.