 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-domain Conversation Quality Evaluation via User Satisfaction Estimation
Nov 18, 2019
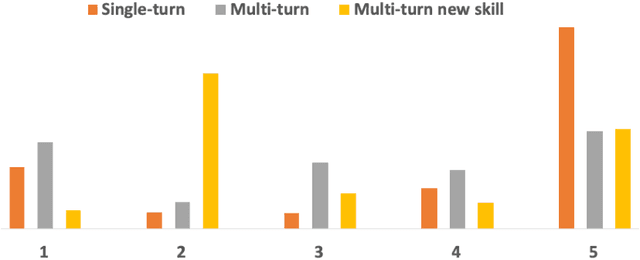
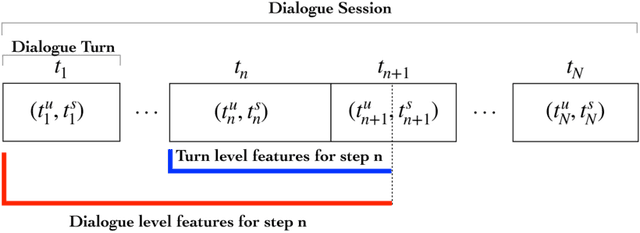
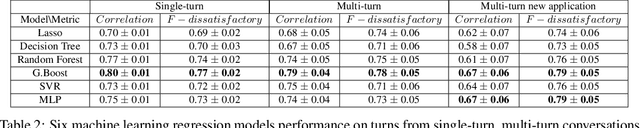
An automated metric to evaluate dialogue quality is vital for optimizing data driven dialogue management. The common approach of relying on explicit user feedback during a conversation is intrusive and sparse. Current models to estimate user satisfaction use limited feature sets and employ annotation schemes with limited generalizability to conversations spanning multiple domains. To address these gaps, we created a new Response Quality annotation scheme, introduced five new domain-independent feature sets and experimented with six machine learning models to estimate User Satisfaction at both turn and dialogue level. Response Quality ratings achieved significantly high correlation (0.76) with explicit turn-level user ratings. Using the new feature sets we introduced, Gradient Boosting Regression model achieved best (rating [1-5]) prediction performance on 26 seen (linear correlation ~0.79) and one new multi-turn domain (linear correlation 0.67). We observed a 16% relative improvement (68% -> 79%) in binary ("satisfactory/dissatisfactory") class prediction accuracy of a domain-independent dialogue-level satisfaction estimation model after including predicted turn-level satisfaction ratings as features.
Investigation of Error Simulation Techniques for Learning Dialog Policies for Conversational Error Recovery
Nov 08, 2019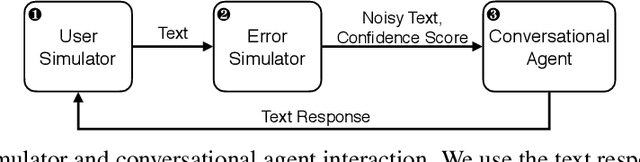

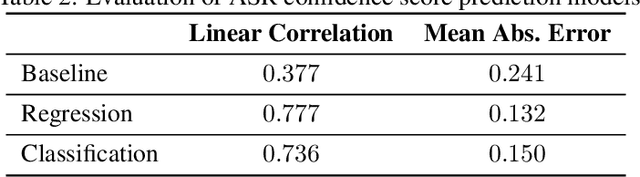
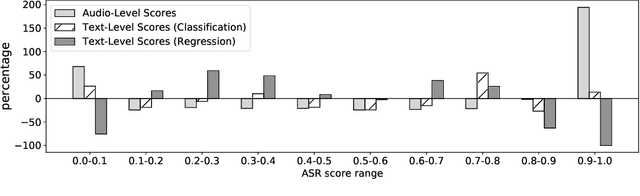
Training dialog policies for speech-based virtual assistants requires a plethora of conversational data. The data collection phase is often expensive and time consuming due to human involvement. To address this issue, a common solution is to build user simulators for data generation. For the successful deployment of the trained policies into real world domains, it is vital that the user simulator mimics realistic conditions. In particular, speech-based assistants are heavily affected by automatic speech recognition and language understanding errors, hence the user simulator should be able to simulate similar errors. In this paper, we review the existing error simulation methods that induce errors at audio, phoneme, text, or semantic level; and conduct detailed comparisons between the audio-level and text-level methods. In the process, we improve the existing text-level method by introducing confidence score prediction and out-of-vocabulary word mapping. We also explore the impact of audio-level and text-level methods on learning a simple clarification dialog policy to recover from errors to provide insight on future improvement for both approaches.
Domain-Independent turn-level Dialogue Quality Evaluation via User Satisfaction Estimation
Aug 19, 2019
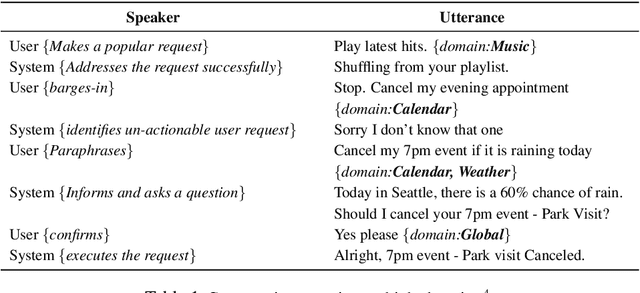
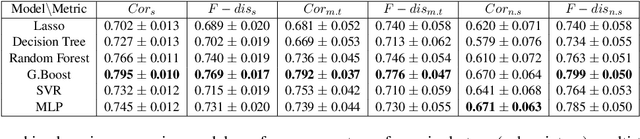
An automated metric to evaluate dialogue quality is vital for optimizing data driven dialogue management. The common approach of relying on explicit user feedback during a conversation is intrusive and sparse. Current models to estimate user satisfaction use limited feature sets and rely on annotation schemes with low inter-rater reliability, limiting generalizability to conversations spanning multiple domains. To address these gaps, we created a new Response Quality annotation scheme, based on which we developed turn-level User Satisfaction metric. We introduced five new domain-independent feature sets and experimented with six machine learning models to estimate the new satisfaction metric. Using Response Quality annotation scheme, across randomly sampled single and multi-turn conversations from 26 domains, we achieved high inter-annotator agreement (Spearman's rho 0.94). The Response Quality labels were highly correlated (0.76) with explicit turn-level user ratings. Gradient boosting regression achieved best correlation of ~0.79 between predicted and annotated user satisfaction labels. Multi Layer Perceptron and Gradient Boosting regression models generalized to an unseen domain better (linear correlation 0.67) than other models. Finally, our ablation study verified that our novel features significantly improved model performance.
Compression of Acoustic Event Detection Models With Quantized Distillation
Jul 01, 2019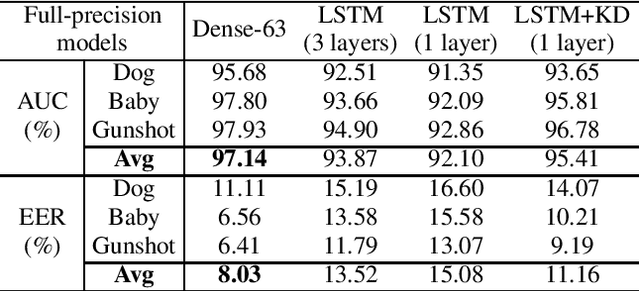

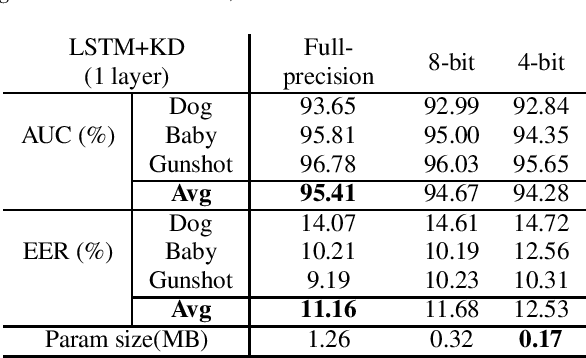
Acoustic Event Detection (AED), aiming at detecting categories of events based on audio signals, has found application in many intelligent systems. Recently deep neural network significantly advances this field and reduces detection errors to a large scale. However how to efficiently execute deep models in AED has received much less attention. Meanwhile state-of-the-art AED models are based on large deep models, which are computational demanding and challenging to deploy on devices with constrained computational resources. In this paper, we present a simple yet effective compression approach which jointly leverages knowledge distillation and quantization to compress larger network (teacher model) into compact network (student model). Experimental results show proposed technique not only lowers error rate of original compact network by 15% through distillation but also further reduces its model size to a large extent (2% of teacher, 12% of full-precision student) through quantization.
Compression of Acoustic Event Detection Models with Low-rank Matrix Factorization and Quantization Training
May 02, 2019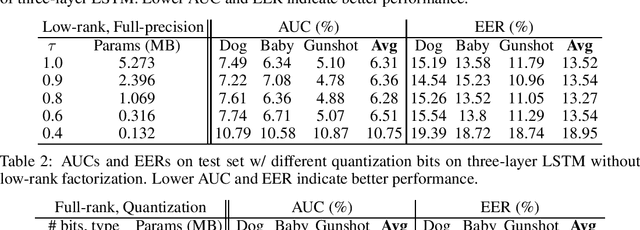
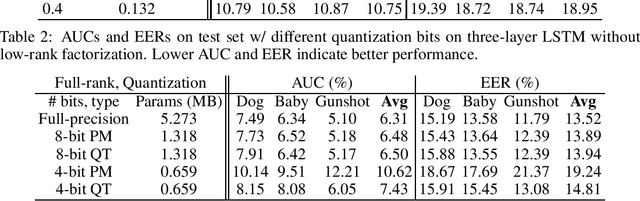
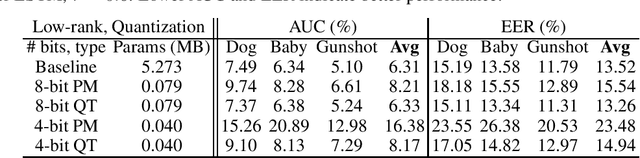
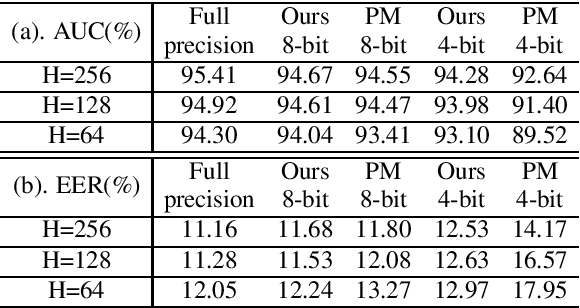
In this paper, we present a compression approach based on the combination of low-rank matrix factorization and quantization training, to reduce complexity for neural network based acoustic event detection (AED) models. Our experimental results show this combined compression approach is very effective. For a three-layer long short-term memory (LSTM) based AED model, the original model size can be reduced to 1% with negligible loss of accuracy. Our approach enables the feasibility of deploying AED for resource-constraint applications.
Semi-supervised Acoustic Event Detection based on tri-training
Apr 29, 2019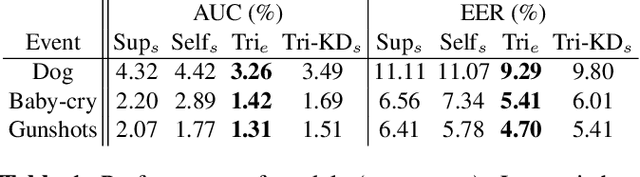
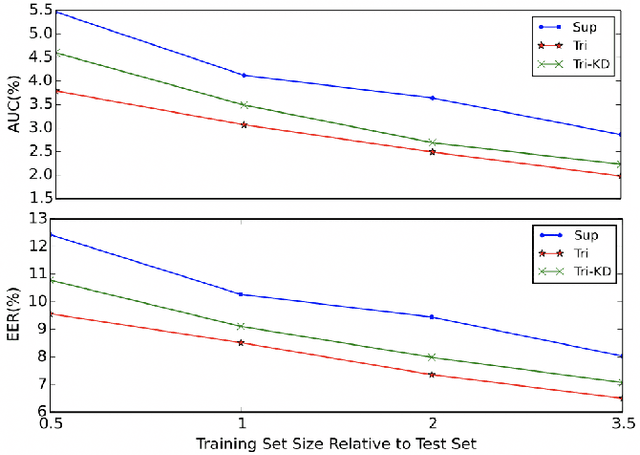
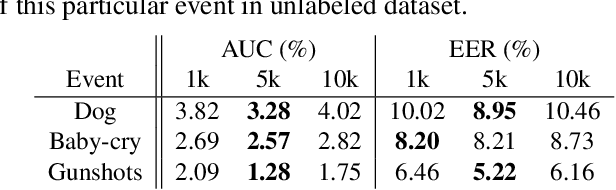
This paper presents our work of training acoustic event detection (AED) models using unlabeled dataset. Recent acoustic event detectors are based on large-scale neural networks, which are typically trained with huge amounts of labeled data. Labels for acoustic events are expensive to obtain, and relevant acoustic event audios can be limited, especially for rare events. In this paper we leverage an Internet-scale unlabeled dataset with potential domain shift to improve the detection of acoustic events. Based on the classic tri-training approach, our proposed method shows accuracy improvement over both the supervised training baseline, and semisupervised self-training set-up, in all pre-defined acoustic event detection tasks. As our approach relies on ensemble models, we further show the improvements can be distilled to a single model via knowledge distillation, with the resulting single student model maintaining high accuracy of teacher ensemble models.
Parsing Coordination for Spoken Language Understanding
Oct 26, 2018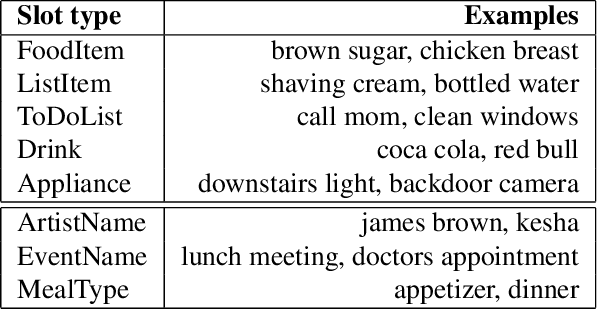
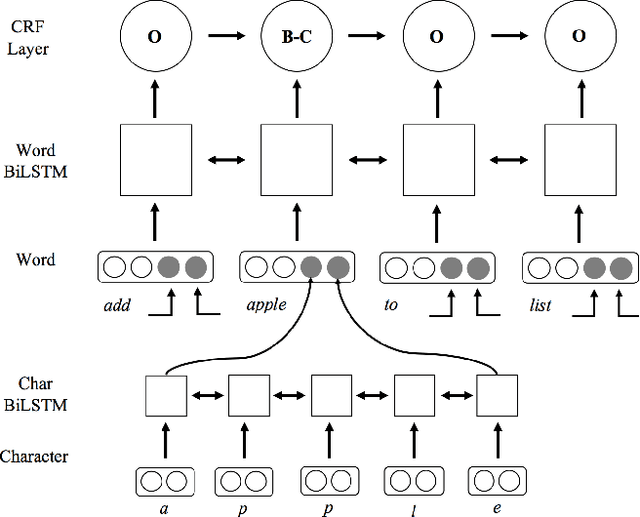

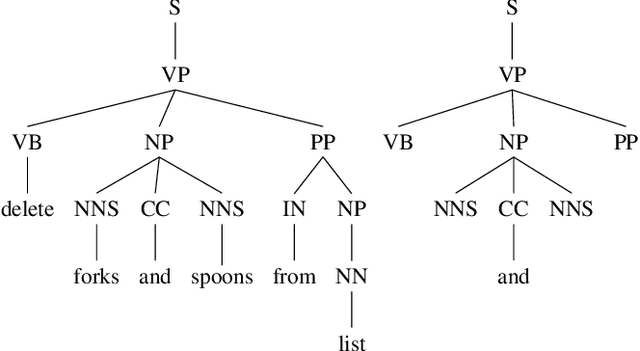
Typical spoken language understanding systems provide narrow semantic parses using a domain-specific ontology. The parses contain intents and slots that are directly consumed by downstream domain applications. In this work we discuss expanding such systems to handle compound entities and intents by introducing a domain-agnostic shallow parser that handles linguistic coordination. We show that our model for parsing coordination learns domain-independent and slot-independent features and is able to segment conjunct boundaries of many different phrasal categories. We also show that using adversarial training can be effective for improving generalization across different slot types for coordination parsing.
Active Learning for New Domains in Natural Language Understanding
Oct 03, 2018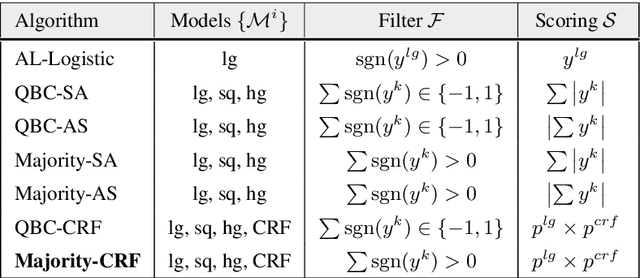
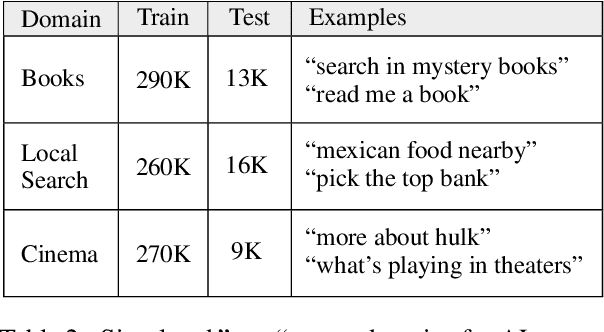
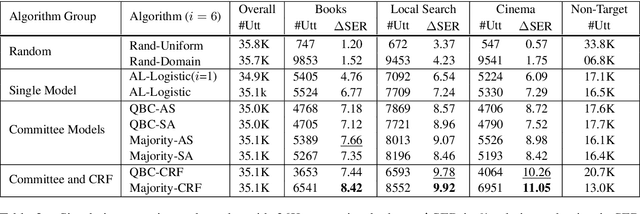
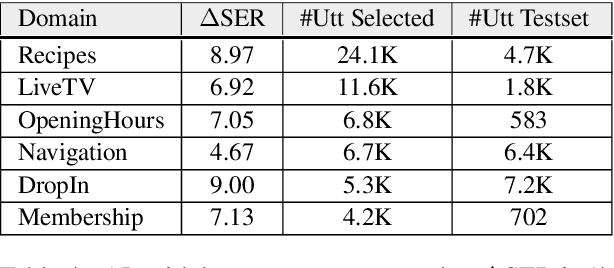
We explore active learning (AL) utterance selection for improving the accuracy of new underrepresented domains in a natural language understanding (NLU) system. Moreover, we propose an AL algorithm called Majority-CRF that uses an ensemble of classification and sequence labeling models to guide utterance selection for annotation. Experiments with three domains show that Majority-CRF achieves 6.6%-9% relative error rate reduction compared to random sampling with the same annotation budget, and statistically significant improvements compared to other AL approaches. Additionally, case studies with human-in-the-loop AL on six new domains show 4.6%-9% improvement on an existing NLU system.
A Re-ranker Scheme for Integrating Large Scale NLU models
Sep 25, 2018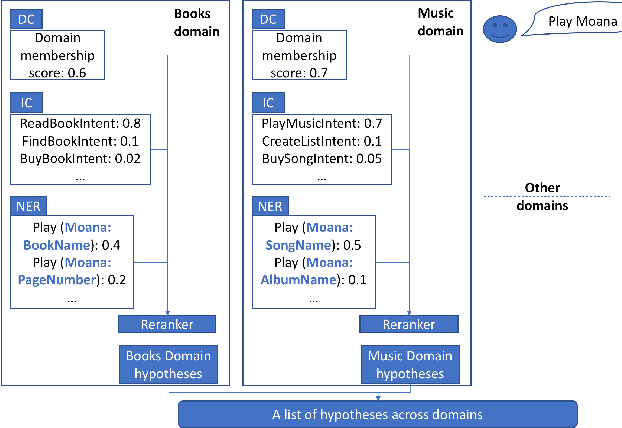
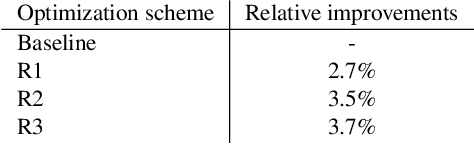


Large scale Natural Language Understanding (NLU) systems are typically trained on large quantities of data, requiring a fast and scalable training strategy. A typical design for NLU systems consists of domain-level NLU modules (domain classifier, intent classifier and named entity recognizer). Hypotheses (NLU interpretations consisting of various intent+slot combinations) from these domain specific modules are typically aggregated with another downstream component. The re-ranker integrates outputs from domain-level recognizers, returning a scored list of cross domain hypotheses. An ideal re-ranker will exhibit the following two properties: (a) it should prefer the most relevant hypothesis for the given input as the top hypothesis and, (b) the interpretation scores corresponding to each hypothesis produced by the re-ranker should be calibrated. Calibration allows the final NLU interpretation score to be comparable across domains. We propose a novel re-ranker strategy that addresses these aspects, while also maintaining domain specific modularity. We design optimization loss functions for such a modularized re-ranker and present results on decreasing the top hypothesis error rate as well as maintaining the model calibration. We also experiment with an extension involving training the domain specific re-rankers on datasets curated independently by each domain to allow further asynchronization. %The proposed re-ranker design showcases the following: (i) improved NLU performance over an unweighted aggregation strategy, (ii) cross-domain calibrated performance and, (iii) support for use cases involving training each re-ranker on datasets curated by each domain independently.
Device-directed Utterance Detection
Aug 07, 2018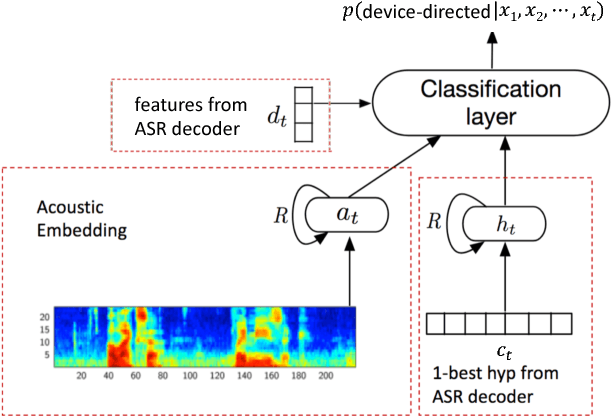
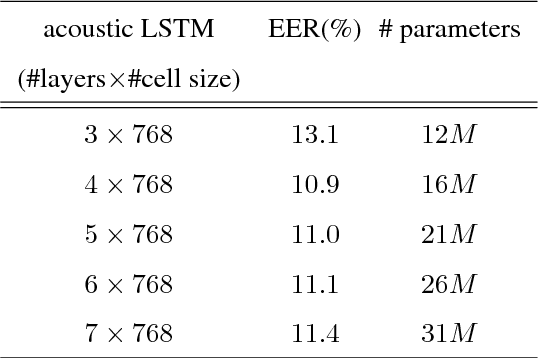
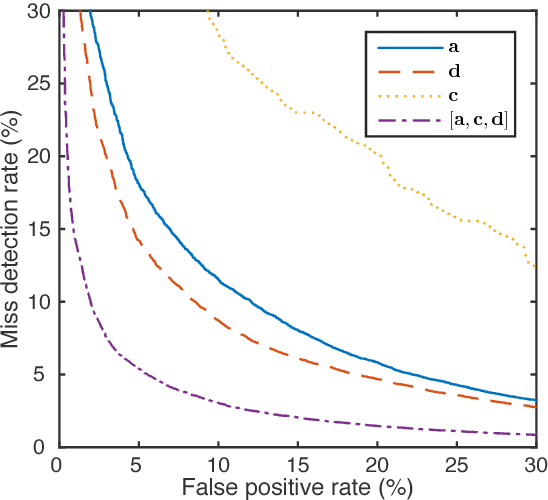
In this work, we propose a classifier for distinguishing device-directed queries from background speech in the context of interactions with voice assistants. Applications include rejection of false wake-ups or unintended interactions as well as enabling wake-word free follow-up queries. Consider the example interaction: $"Computer,~play~music", "Computer,~reduce~the~volume"$. In this interaction, the user needs to repeat the wake-word ($Computer$) for the second query. To allow for more natural interactions, the device could immediately re-enter listening state after the first query (without wake-word repetition) and accept or reject a potential follow-up as device-directed or background speech. The proposed model consists of two long short-term memory (LSTM) neural networks trained on acoustic features and automatic speech recognition (ASR) 1-best hypotheses, respectively. A feed-forward deep neural network (DNN) is then trained to combine the acoustic and 1-best embeddings, derived from the LSTMs, with features from the ASR decoder. Experimental results show that ASR decoder, acoustic embeddings, and 1-best embeddings yield an equal-error-rate (EER) of $9.3~\%$, $10.9~\%$ and $20.1~\%$, respectively. Combination of the features resulted in a $44~\%$ relative improvement and a final EER of $5.2~\%$.