 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Cohesive Are Community Search Results on Online Social Networks?: An Experimental Evaluation
May 01, 2025



Recently, numerous community search methods for large graphs have been proposed, at the core of which is defining and measuring cohesion. This paper experimentally evaluates the effectiveness of these community search algorithms w.r.t. cohesiveness in the context of online social networks. Social communities are formed and developed under the influence of group cohesion theory, which has been extensively studied in social psychology. However, current generic methods typically measure cohesiveness using structural or attribute-based approaches and overlook domain-specific concepts such as group cohesion. We introduce five novel psychology-informed cohesiveness measures, based on the concept of group cohesion from social psychology, and propose a novel framework called CHASE for evaluating eight representative community search algorithms w.r.t. these measures on online social networks. Our analysis reveals that there is no clear correlation between structural and psychological cohesiveness, and no algorithm effectively identifies psychologically cohesive communities in online social networks. This study provides new insights that could guide the development of future community search methods.
AUTOSHAPE: An Autoencoder-Shapelet Approach for Time Series Clustering
Aug 06, 2022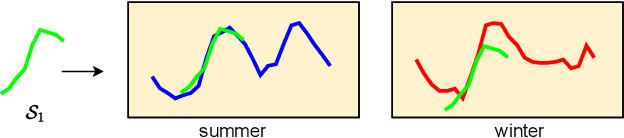
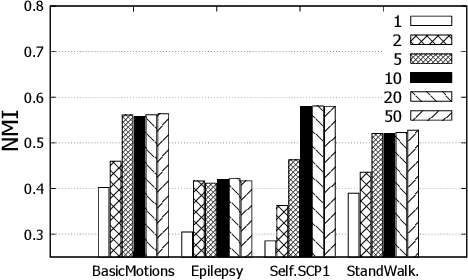
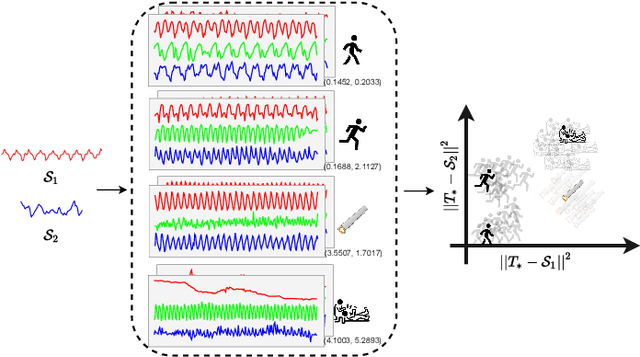

Time series shapelets are discriminative subsequences that have been recently found effective for time series clustering (TSC). The shapelets are convenient for interpreting the clusters. Thus, the main challenge for TSC is to discover high-quality variable-length shapelets to discriminate different clusters. In this paper, we propose a novel autoencoder-shapelet approach (AUTOSHAPE), which is the first study to take the advantage of both autoencoder and shapelet for determining shapelets in an unsupervised manner. An autoencoder is specially designed to learn high-quality shapelets. More specifically, for guiding the latent representation learning, we employ the latest self-supervised loss to learn the unified embeddings for variable-length shapelet candidates (time series subsequences) of different variables, and propose the diversity loss to select the discriminating embeddings in the unified space. We introduce the reconstruction loss to recover shapelets in the original time series space for clustering. Finally, we adopt Davies Bouldin index (DBI) to inform AUTOSHAPE of the clustering performance during learning. We present extensive experiments on AUTOSHAPE. To evaluate the clustering performance on univariate time series (UTS), we compare AUTOSHAPE with 15 representative methods using UCR archive datasets. To study the performance of multivariate time series (MTS), we evaluate AUTOSHAPE on 30 UEA archive datasets with 5 competitive methods. The results validate that AUTOSHAPE is the best among all the methods compared. We interpret clusters with shapelets, and can obtain interesting intuitions about clusters in three UTS case studies and one MTS case study, respectively.
DISCO: Influence Maximization Meets Network Embedding and Deep Learning
Jun 18, 2019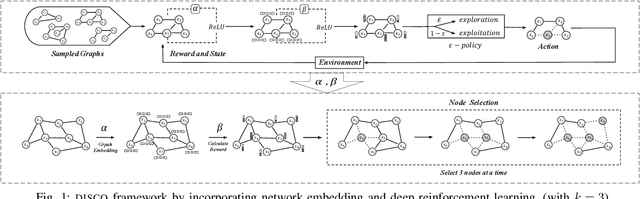
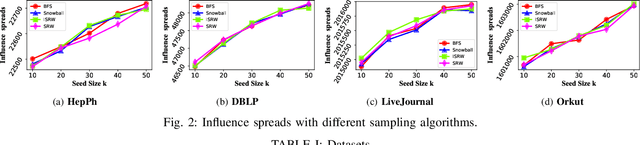
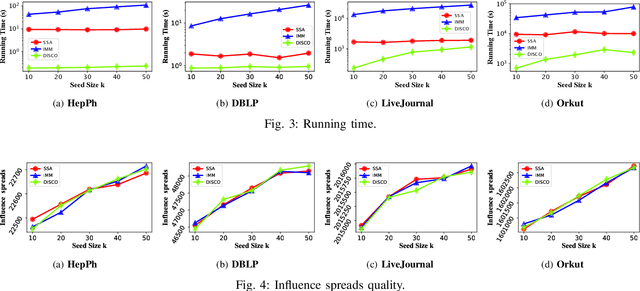
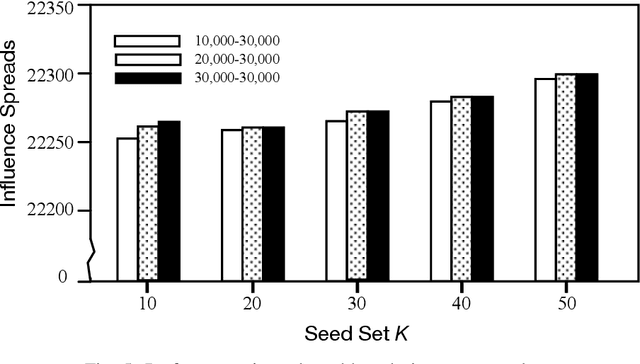
Since its introduction in 2003, the influence maximization (IM) problem has drawn significant research attention in the literature. The aim of IM is to select a set of k users who can influence the most individuals in the social network. The problem is proven to be NP-hard. A large number of approximate algorithms have been proposed to address this problem. The state-of-the-art algorithms estimate the expected influence of nodes based on sampled diffusion paths. As the number of required samples have been recently proven to be lower bounded by a particular threshold that presets tradeoff between the accuracy and efficiency, the result quality of these traditional solutions is hard to be further improved without sacrificing efficiency. In this paper, we present an orthogonal and novel paradigm to address the IM problem by leveraging deep learning models to estimate the expected influence. Specifically, we present a novel framework called DISCO that incorporates network embedding and deep reinforcement learning techniques to address this problem. Experimental study on real-world networks demonstrates that DISCO achieves the best performance w.r.t efficiency and influence spread quality compared to state-of-the-art classical solutions. Besides, we also show that the learning model exhibits good generality.