 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Gradient-free and Likelihood-free Prompt Tuning
Apr 30, 2023



Due to privacy or commercial constraints, large pre-trained language models (PLMs) are often offered as black-box APIs. Fine-tuning such models to downstream tasks is challenging because one can neither access the model's internal representations nor propagate gradients through it. This paper addresses these challenges by developing techniques for adapting PLMs with only API access. Building on recent work on soft prompt tuning, we develop methods to tune the soft prompts without requiring gradient computation. Further, we develop extensions that in addition to not requiring gradients also do not need to access any internal representation of the PLM beyond the input embeddings. Moreover, instead of learning a single prompt, our methods learn a distribution over prompts allowing us to quantify predictive uncertainty. Ours is the first work to consider uncertainty in prompts when only having API access to the PLM. Finally, through extensive experiments, we carefully vet the proposed methods and find them competitive with (and sometimes even improving on) gradient-based approaches with full access to the PLM.
Post-hoc Uncertainty Learning using a Dirichlet Meta-Model
Dec 14, 2022



It is known that neural networks have the problem of being over-confident when directly using the output label distribution to generate uncertainty measures. Existing methods mainly resolve this issue by retraining the entire model to impose the uncertainty quantification capability so that the learned model can achieve desired performance in accuracy and uncertainty prediction simultaneously. However, training the model from scratch is computationally expensive and may not be feasible in many situations. In this work, we consider a more practical post-hoc uncertainty learning setting, where a well-trained base model is given, and we focus on the uncertainty quantification task at the second stage of training. We propose a novel Bayesian meta-model to augment pre-trained models with better uncertainty quantification abilities, which is effective and computationally efficient. Our proposed method requires no additional training data and is flexible enough to quantify different uncertainties and easily adapt to different application settings, including out-of-domain data detection, misclassification detection, and trustworthy transfer learning. We demonstrate our proposed meta-model approach's flexibility and superior empirical performance on these applications over multiple representative image classification benchmarks.
Fair Infinitesimal Jackknife: Mitigating the Influence of Biased Training Data Points Without Refitting
Dec 13, 2022



In consequential decision-making applications, mitigating unwanted biases in machine learning models that yield systematic disadvantage to members of groups delineated by sensitive attributes such as race and gender is one key intervention to strive for equity. Focusing on demographic parity and equality of opportunity, in this paper we propose an algorithm that improves the fairness of a pre-trained classifier by simply dropping carefully selected training data points. We select instances based on their influence on the fairness metric of interest, computed using an infinitesimal jackknife-based approach. The dropping of training points is done in principle, but in practice does not require the model to be refit. Crucially, we find that such an intervention does not substantially reduce the predictive performance of the model but drastically improves the fairness metric. Through careful experiments, we evaluate the effectiveness of the proposed approach on diverse tasks and find that it consistently improves upon existing alternatives.
Are you using test log-likelihood correctly?
Dec 01, 2022



Test log-likelihood is commonly used to compare different models of the same data and different approximate inference algorithms for fitting the same probabilistic model. We present simple examples demonstrating how comparisons based on test log-likelihood can contradict comparisons according to other objectives. Specifically, our examples show that (i) conclusions about forecast accuracy based on test log-likelihood comparisons may not agree with conclusions based on other distributional quantities like means; and (ii) that approximate Bayesian inference algorithms that attain higher test log-likelihoods need not also yield more accurate posterior approximations.
Post-hoc loss-calibration for Bayesian neural networks
Jun 13, 2021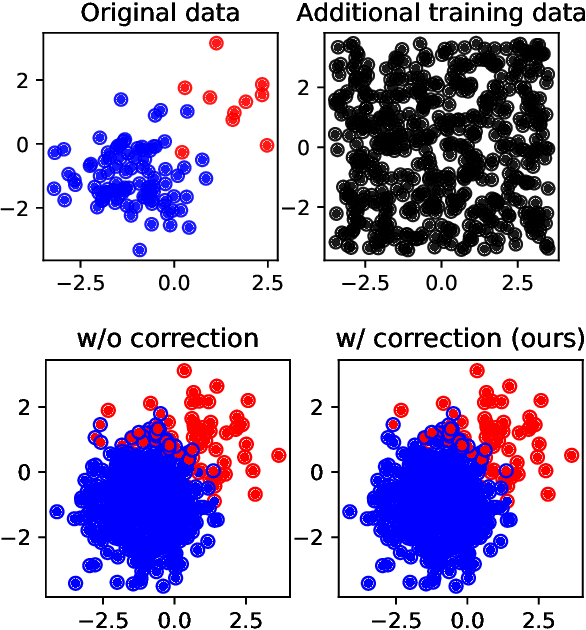
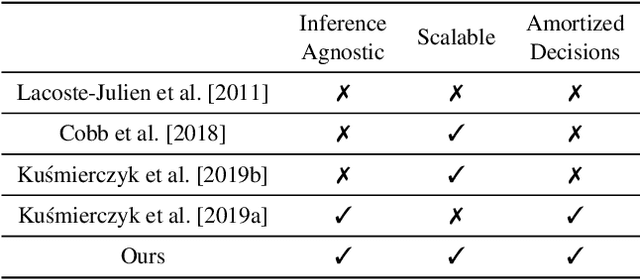
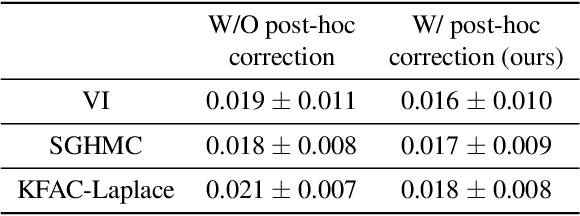

Bayesian decision theory provides an elegant framework for acting optimally under uncertainty when tractable posterior distributions are available. Modern Bayesian models, however, typically involve intractable posteriors that are approximated with, potentially crude, surrogates. This difficulty has engendered loss-calibrated techniques that aim to learn posterior approximations that favor high-utility decisions. In this paper, focusing on Bayesian neural networks, we develop methods for correcting approximate posterior predictive distributions encouraging them to prefer high-utility decisions. In contrast to previous work, our approach is agnostic to the choice of the approximate inference algorithm, allows for efficient test time decision making through amortization, and empirically produces higher quality decisions. We demonstrate the effectiveness of our approach through controlled experiments spanning a diversity of tasks and datasets.
Measuring the sensitivity of Gaussian processes to kernel choice
Jun 11, 2021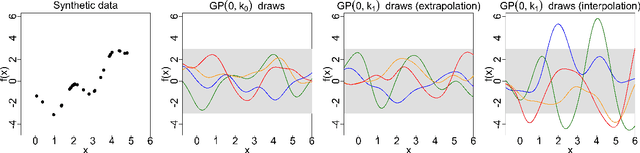
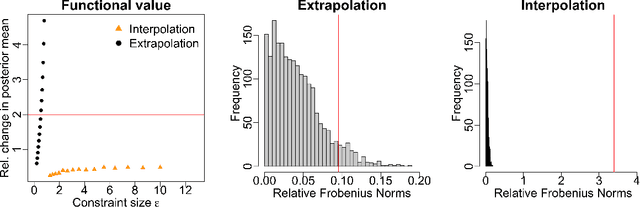
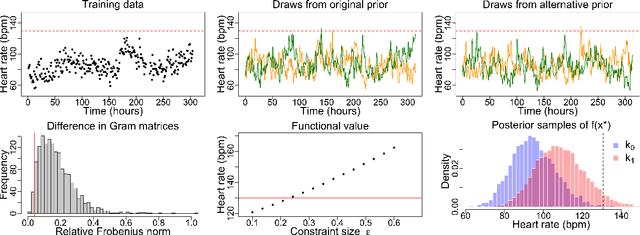
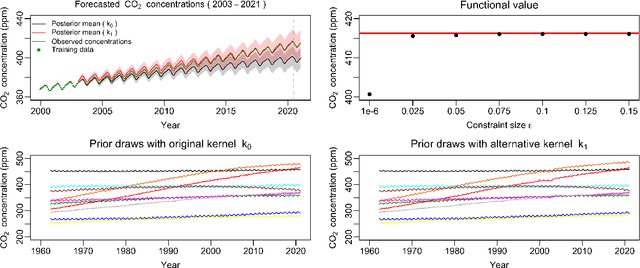
Gaussian processes (GPs) are used to make medical and scientific decisions, including in cardiac care and monitoring of carbon dioxide emissions. But the choice of GP kernel is often somewhat arbitrary. In particular, uncountably many kernels typically align with qualitative prior knowledge (e.g. function smoothness or stationarity). But in practice, data analysts choose among a handful of convenient standard kernels (e.g. squared exponential). In the present work, we ask: Would decisions made with a GP differ under other, qualitatively interchangeable kernels? We show how to formulate this sensitivity analysis as a constrained optimization problem over a finite-dimensional space. We can then use standard optimizers to identify substantive changes in relevant decisions made with a GP. We demonstrate in both synthetic and real-world examples that decisions made with a GP can exhibit substantial sensitivity to kernel choice, even when prior draws are qualitatively interchangeable to a user.
Uncertainty Quantification 360: A Holistic Toolkit for Quantifying and Communicating the Uncertainty of AI
Jun 04, 2021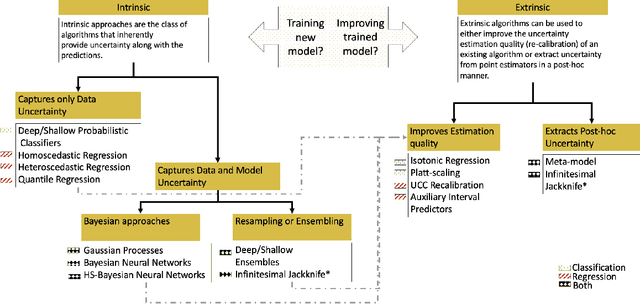
In this paper, we describe an open source Python toolkit named Uncertainty Quantification 360 (UQ360) for the uncertainty quantification of AI models. The goal of this toolkit is twofold: first, to provide a broad range of capabilities to streamline as well as foster the common practices of quantifying, evaluating, improving, and communicating uncertainty in the AI application development lifecycle; second, to encourage further exploration of UQ's connections to other pillars of trustworthy AI such as fairness and transparency through the dissemination of latest research and education materials. Beyond the Python package (\url{https://github.com/IBM/UQ360}), we have developed an interactive experience (\url{http://uq360.mybluemix.net}) and guidance materials as educational tools to aid researchers and developers in producing and communicating high-quality uncertainties in an effective manner.
Uncertainty Characteristics Curves: A Systematic Assessment of Prediction Intervals
Jun 01, 2021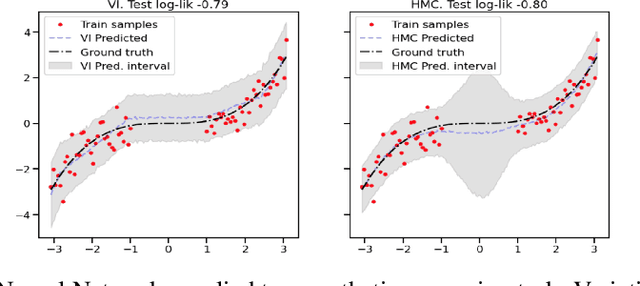
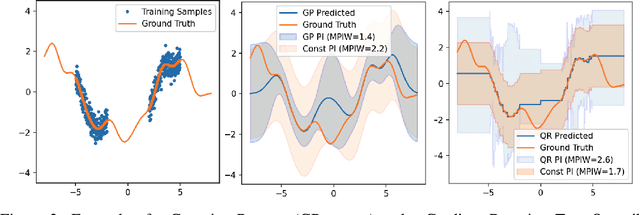

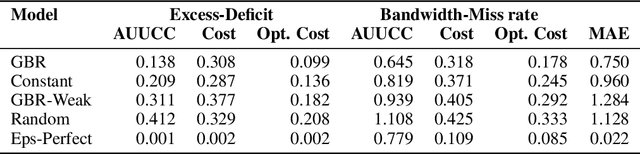
Accurate quantification of model uncertainty has long been recognized as a fundamental requirement for trusted AI. In regression tasks, uncertainty is typically quantified using prediction intervals calibrated to a specific operating point, making evaluation and comparison across different studies difficult. Our work leverages: (1) the concept of operating characteristics curves and (2) the notion of a gain over a simple reference, to derive a novel operating point agnostic assessment methodology for prediction intervals. The paper describes the corresponding algorithm, provides a theoretical analysis, and demonstrates its utility in multiple scenarios. We argue that the proposed method addresses the current need for comprehensive assessment of prediction intervals and thus represents a valuable addition to the uncertainty quantification toolbox.
EVA: Generating Longitudinal Electronic Health Records Using Conditional Variational Autoencoders
Dec 18, 2020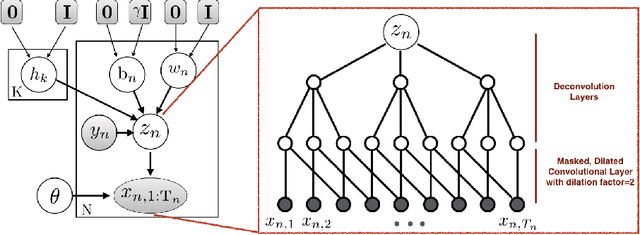
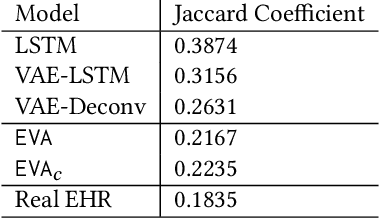
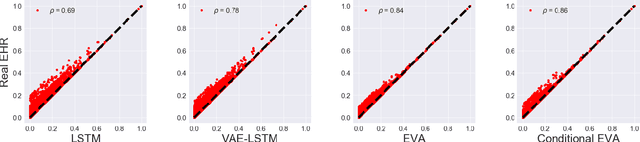

Researchers require timely access to real-world longitudinal electronic health records (EHR) to develop, test, validate, and implement machine learning solutions that improve the quality and efficiency of healthcare. In contrast, health systems value deeply patient privacy and data security. De-identified EHRs do not adequately address the needs of health systems, as de-identified data are susceptible to re-identification and its volume is also limited. Synthetic EHRs offer a potential solution. In this paper, we propose EHR Variational Autoencoder (EVA) for synthesizing sequences of discrete EHR encounters (e.g., clinical visits) and encounter features (e.g., diagnoses, medications, procedures). We illustrate that EVA can produce realistic EHR sequences, account for individual differences among patients, and can be conditioned on specific disease conditions, thus enabling disease-specific studies. We design efficient, accurate inference algorithms by combining stochastic gradient Markov Chain Monte Carlo with amortized variational inference. We assess the utility of the methods on large real-world EHR repositories containing over 250, 000 patients. Our experiments, which include user studies with knowledgeable clinicians, indicate the generated EHR sequences are realistic. We confirmed the performance of predictive models trained on the synthetic data are similar with those trained on real EHRs. Additionally, our findings indicate that augmenting real data with synthetic EHRs results in the best predictive performance - improving the best baseline by as much as 8% in top-20 recall.
Model Fusion with Kullback--Leibler Divergence
Jul 13, 2020

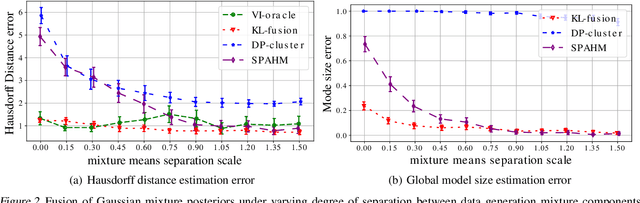
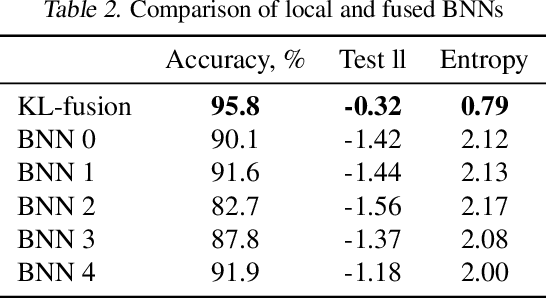
We propose a method to fuse posterior distributions learned from heterogeneous datasets. Our algorithm relies on a mean field assumption for both the fused model and the individual dataset posteriors and proceeds using a simple assign-and-average approach. The components of the dataset posteriors are assigned to the proposed global model components by solving a regularized variant of the assignment problem. The global components are then updated based on these assignments by their mean under a KL divergence. For exponential family variational distributions, our formulation leads to an efficient non-parametric algorithm for computing the fused model. Our algorithm is easy to describe and implement, efficient, and competitive with state-of-the-art on motion capture analysis, topic modeling, and federated learning of Bayesian neural networks.