 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiving Deep: Forecasting Sea Surface Temperatures and Anomalies
Jan 10, 2025This overview paper details the findings from the Diving Deep: Forecasting Sea Surface Temperatures and Anomalies Challenge at the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2024. The challenge focused on the data-driven predictability of global sea surface temperatures (SSTs), a key factor in climate forecasting, ecosystem management, fisheries management, and climate change monitoring. The challenge involved forecasting SST anomalies (SSTAs) three months in advance using historical data and included a special task of predicting SSTAs nine months ahead for the Baltic Sea. Participants utilized various machine learning approaches to tackle the task, leveraging data from ERA5. This paper discusses the methodologies employed, the results obtained, and the lessons learned, offering insights into the future of climate-related predictive modeling.
Volvo Discovery Challenge at ECML-PKDD 2024
Sep 17, 2024



This paper presents an overview of the Volvo Discovery Challenge, held during the ECML-PKDD 2024 conference. The challenge's goal was to predict the failure risk of an anonymized component in Volvo trucks using a newly published dataset. The test data included observations from two generations (gen1 and gen2) of the component, while the training data was provided only for gen1. The challenge attracted 52 data scientists from around the world who submitted a total of 791 entries. We provide a brief description of the problem definition, challenge setup, and statistics about the submissions. In the section on winning methodologies, the first, second, and third-place winners of the competition briefly describe their proposed methods and provide GitHub links to their implemented code. The shared code can be interesting as an advanced methodology for researchers in the predictive maintenance domain. The competition was hosted on the Codabench platform.
Transformers with Stochastic Competition for Tabular Data Modelling
Jul 18, 2024Despite the prevalence and significance of tabular data across numerous industries and fields, it has been relatively underexplored in the realm of deep learning. Even today, neural networks are often overshadowed by techniques such as gradient boosted decision trees (GBDT). However, recent models are beginning to close this gap, outperforming GBDT in various setups and garnering increased attention in the field. Inspired by this development, we introduce a novel stochastic deep learning model specifically designed for tabular data. The foundation of this model is a Transformer-based architecture, carefully adapted to cater to the unique properties of tabular data through strategic architectural modifications and leveraging two forms of stochastic competition. First, we employ stochastic "Local Winner Takes All" units to promote generalization capacity through stochasticity and sparsity. Second, we introduce a novel embedding layer that selects among alternative linear embedding layers through a mechanism of stochastic competition. The effectiveness of the model is validated on a variety of widely-used, publicly available datasets. We demonstrate that, through the incorporation of these elements, our model yields high performance and marks a significant advancement in the application of deep learning to tabular data.
A New Dataset for End-to-End Sign Language Translation: The Greek Elementary School Dataset
Oct 07, 2023



Automatic Sign Language Translation (SLT) is a research avenue of great societal impact. End-to-End SLT facilitates the interaction of Hard-of-Hearing (HoH) with hearing people, thus improving their social life and opportunities for participation in social life. However, research within this frame of reference is still in its infancy, and current resources are particularly limited. Existing SLT methods are either of low translation ability or are trained and evaluated on datasets of restricted vocabulary and questionable real-world value. A characteristic example is Phoenix2014T benchmark dataset, which only covers weather forecasts in German Sign Language. To address this shortage of resources, we introduce a newly constructed collection of 29653 Greek Sign Language video-translation pairs which is based on the official syllabus of Greek Elementary School. Our dataset covers a wide range of subjects. We use this novel dataset to train recent state-of-the-art Transformer-based methods widely used in SLT research. Our results demonstrate the potential of our introduced dataset to advance SLT research by offering a favourable balance between usability and real-world value.
* ICCVW2023 - ACVR
Stochastic Transformer Networks with Linear Competing Units: Application to end-to-end SL Translation
Oct 01, 2021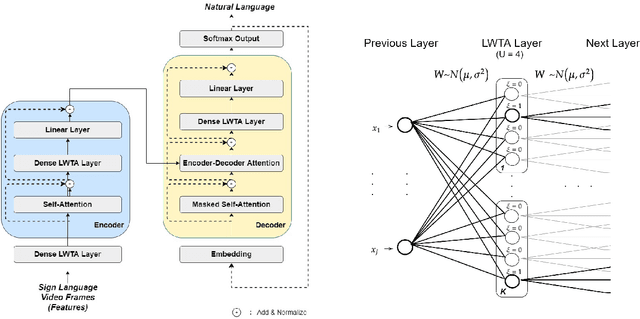
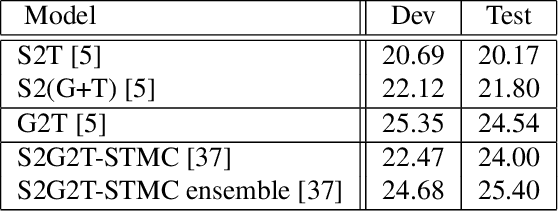


Automating sign language translation (SLT) is a challenging real world application. Despite its societal importance, though, research progress in the field remains rather poor. Crucially, existing methods that yield viable performance necessitate the availability of laborious to obtain gloss sequence groundtruth. In this paper, we attenuate this need, by introducing an end-to-end SLT model that does not entail explicit use of glosses; the model only needs text groundtruth. This is in stark contrast to existing end-to-end models that use gloss sequence groundtruth, either in the form of a modality that is recognized at an intermediate model stage, or in the form of a parallel output process, jointly trained with the SLT model. Our approach constitutes a Transformer network with a novel type of layers that combines: (i) local winner-takes-all (LWTA) layers with stochastic winner sampling, instead of conventional ReLU layers, (ii) stochastic weights with posterior distributions estimated via variational inference, and (iii) a weight compression technique at inference time that exploits estimated posterior variance to perform massive, almost lossless compression. We demonstrate that our approach can reach the currently best reported BLEU-4 score on the PHOENIX 2014T benchmark, but without making use of glosses for model training, and with a memory footprint reduced by more than 70%.
Variational Bayesian Sequence-to-Sequence Networks for Memory-Efficient Sign Language Translation
Feb 11, 2021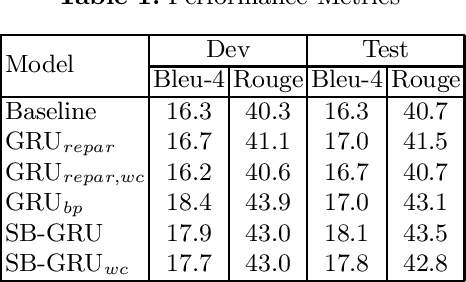
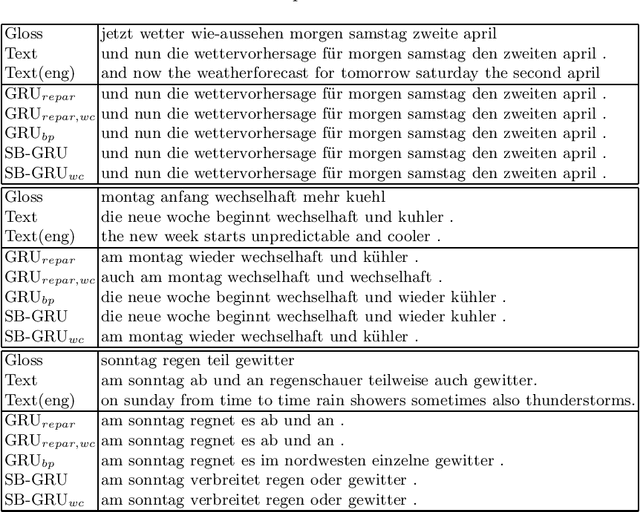
Memory-efficient continuous Sign Language Translation is a significant challenge for the development of assisted technologies with real-time applicability for the deaf. In this work, we introduce a paradigm of designing recurrent deep networks whereby the output of the recurrent layer is derived from appropriate arguments from nonparametric statistics. A novel variational Bayesian sequence-to-sequence network architecture is proposed that consists of a) a full Gaussian posterior distribution for data-driven memory compression and b) a nonparametric Indian Buffet Process prior for regularization applied on the Gated Recurrent Unit non-gate weights. We dub our approach Stick-Breaking Recurrent network and show that it can achieve a substantial weight compression without diminishing modeling performance.