 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Pervasive Distributed Agentic Generative AI -- A State of The Art
Jun 16, 2025The rapid advancement of intelligent agents and Large Language Models (LLMs) is reshaping the pervasive computing field. Their ability to perceive, reason, and act through natural language understanding enables autonomous problem-solving in complex pervasive environments, including the management of heterogeneous sensors, devices, and data. This survey outlines the architectural components of LLM agents (profiling, memory, planning, and action) and examines their deployment and evaluation across various scenarios. Than it reviews computational and infrastructural advancements (cloud to edge) in pervasive computing and how AI is moving in this field. It highlights state-of-the-art agent deployment strategies and applications, including local and distributed execution on resource-constrained devices. This survey identifies key challenges of these agents in pervasive computing such as architectural, energetic and privacy limitations. It finally proposes what we called "Agent as a Tool", a conceptual framework for pervasive agentic AI, emphasizing context awareness, modularity, security, efficiency and effectiveness.
RP-DNN: A Tweet level propagation context based deep neural networks for early rumor detection in Social Media
Mar 02, 2020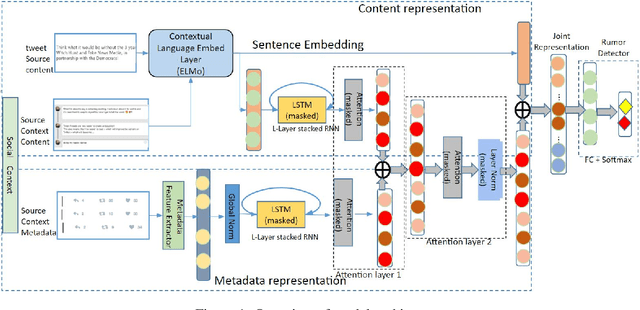

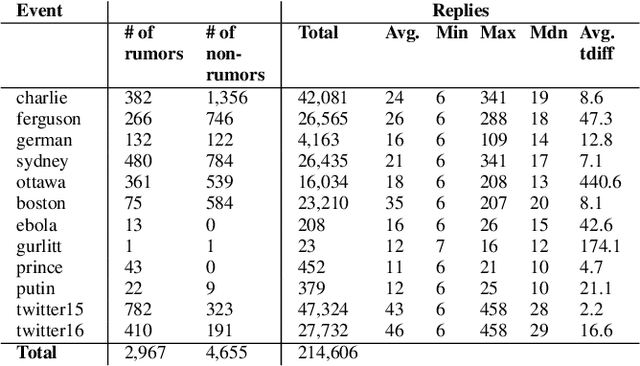
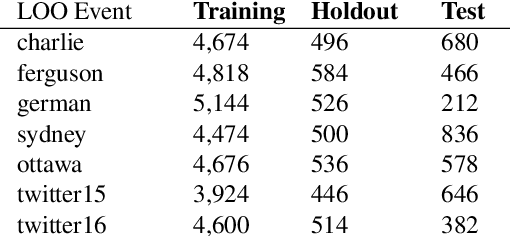
Early rumor detection (ERD) on social media platform is very challenging when limited, incomplete and noisy information is available. Most of the existing methods have largely worked on event-level detection that requires the collection of posts relevant to a specific event and relied only on user-generated content. They are not appropriate to detect rumor sources in the very early stages, before an event unfolds and becomes widespread. In this paper, we address the task of ERD at the message level. We present a novel hybrid neural network architecture, which combines a task-specific character-based bidirectional language model and stacked Long Short-Term Memory (LSTM) networks to represent textual contents and social-temporal contexts of input source tweets, for modelling propagation patterns of rumors in the early stages of their development. We apply multi-layered attention models to jointly learn attentive context embeddings over multiple context inputs. Our experiments employ a stringent leave-one-out cross-validation (LOO-CV) evaluation setup on seven publicly available real-life rumor event data sets. Our models achieve state-of-the-art(SoA) performance for detecting unseen rumors on large augmented data which covers more than 12 events and 2,967 rumors. An ablation study is conducted to understand the relative contribution of each component of our proposed model.
Neural Language Model Based Training Data Augmentation for Weakly Supervised Early Rumor Detection
Jul 16, 2019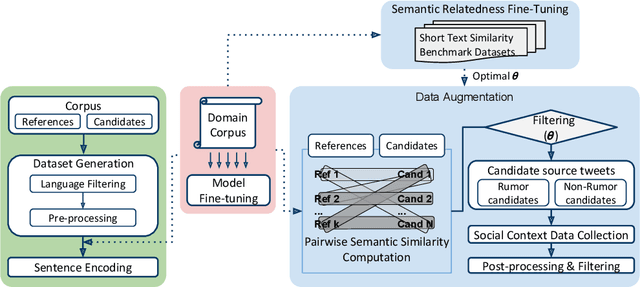
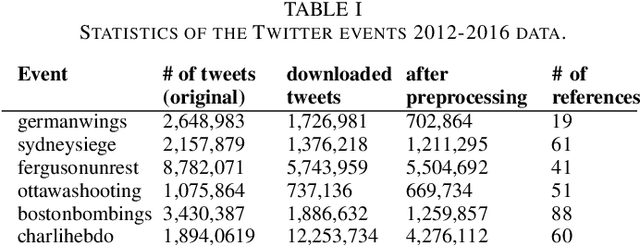
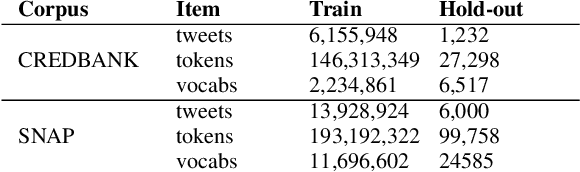

The scarcity and class imbalance of training data are known issues in current rumor detection tasks. We propose a straight-forward and general-purpose data augmentation technique which is beneficial to early rumor detection relying on event propagation patterns. The key idea is to exploit massive unlabeled event data sets on social media to augment limited labeled rumor source tweets. This work is based on rumor spreading patterns revealed by recent rumor studies and semantic relatedness between labeled and unlabeled data. A state-of-the-art neural language model (NLM) and large credibility-focused Twitter corpora are employed to learn context-sensitive representations of rumor tweets. Six different real-world events based on three publicly available rumor datasets are employed in our experiments to provide a comparative evaluation of the effectiveness of the method. The results show that our method can expand the size of an existing rumor data set nearly by 200% and corresponding social context (i.e., conversational threads) by 100% with reasonable quality. Preliminary experiments with a state-of-the-art deep learning-based rumor detection model show that augmented data can alleviate over-fitting and class imbalance caused by limited train data and can help to train complex neural networks (NNs). With augmented data, the performance of rumor detection can be improved by 12.1% in terms of F-score. Our experiments also indicate that augmented training data can help to generalize rumor detection models on unseen rumors.
* 8 pages
SemRe-Rank: Improving Automatic Term Extraction By Incorporating Semantic Relatedness With Personalised PageRank
Mar 28, 2018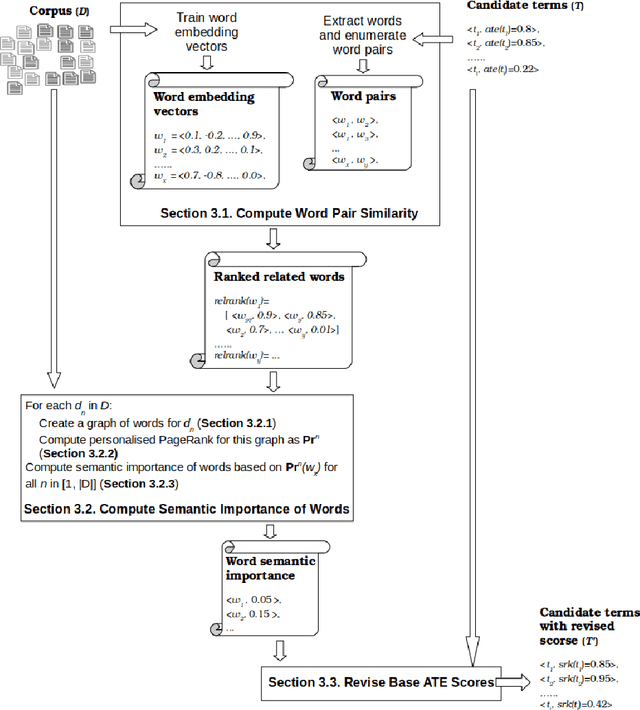
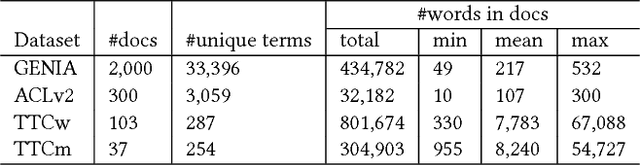

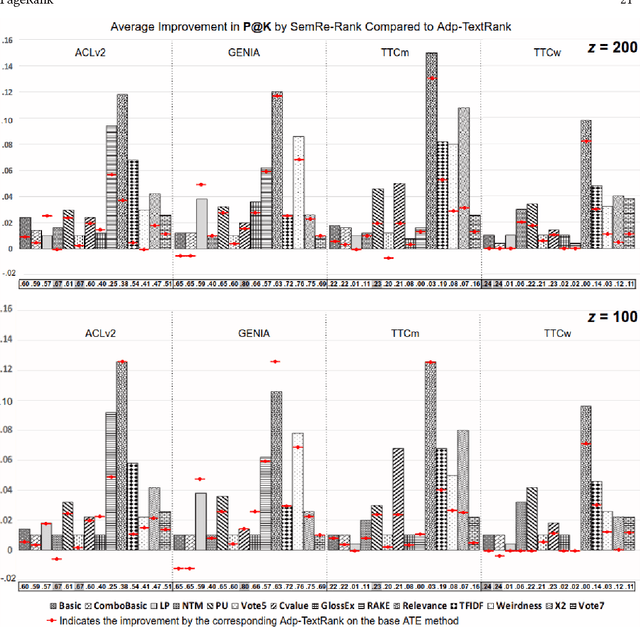
Automatic Term Extraction deals with the extraction of terminology from a domain specific corpus, and has long been an established research area in data and knowledge acquisition. ATE remains a challenging task as it is known that there is no existing ATE methods that can consistently outperform others in any domain. This work adopts a refreshed perspective to this problem: instead of searching for such a 'one-size-fit-all' solution that may never exist, we propose to develop generic methods to 'enhance' existing ATE methods. We introduce SemRe-Rank, the first method based on this principle, to incorporate semantic relatedness - an often overlooked venue - into an existing ATE method to further improve its performance. SemRe-Rank incorporates word embeddings into a personalised PageRank process to compute 'semantic importance' scores for candidate terms from a graph of semantically related words (nodes), which are then used to revise the scores of candidate terms computed by a base ATE algorithm. Extensively evaluated with 13 state-of-the-art base ATE methods on four datasets of diverse nature, it is shown to have achieved widespread improvement over all base methods and across all datasets, with up to 15 percentage points when measured by the Precision in the top ranked K candidate terms (the average for a set of K's), or up to 28 percentage points in F1 measured at a K that equals to the expected real terms in the candidates (F1 in short). Compared to an alternative approach built on the well-known TextRank algorithm, SemRe-Rank can potentially outperform by up to 8 points in Precision at top K, or up to 17 points in F1.