 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation with Progressive Adaptation of Subspaces
Sep 01, 2020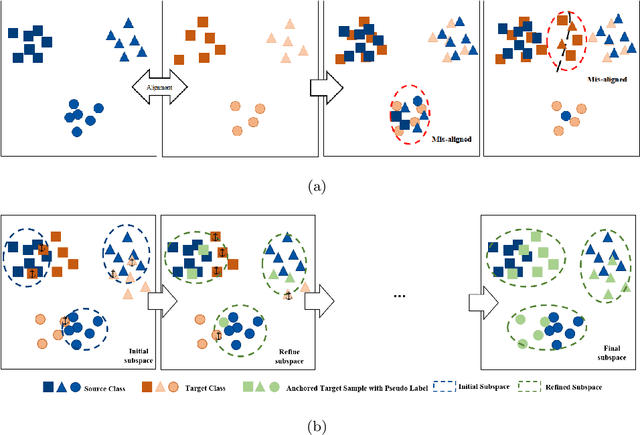
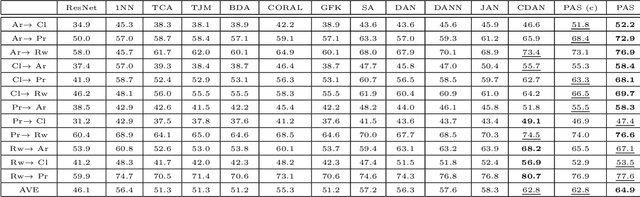
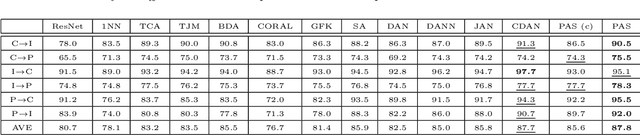
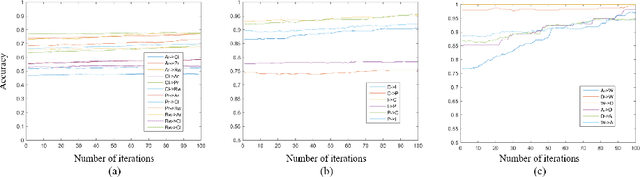
Unsupervised Domain Adaptation (UDA) aims to classify unlabeled target domain by transferring knowledge from labeled source domain with domain shift. Most of the existing UDA methods try to mitigate the adverse impact induced by the shift via reducing domain discrepancy. However, such approaches easily suffer a notorious mode collapse issue due to the lack of labels in target domain. Naturally, one of the effective ways to mitigate this issue is to reliably estimate the pseudo labels for target domain, which itself is hard. To overcome this, we propose a novel UDA method named Progressive Adaptation of Subspaces approach (PAS) in which we utilize such an intuition that appears much reasonable to gradually obtain reliable pseudo labels. Speci fically, we progressively and steadily refine the shared subspaces as bridge of knowledge transfer by adaptively anchoring/selecting and leveraging those target samples with reliable pseudo labels. Subsequently, the refined subspaces can in turn provide more reliable pseudo-labels of the target domain, making the mode collapse highly mitigated. Our thorough evaluation demonstrates that PAS is not only effective for common UDA, but also outperforms the state-of-the arts for more challenging Partial Domain Adaptation (PDA) situation, where the source label set subsumes the target one.
Accelerated Stochastic Gradient-free and Projection-free Methods
Aug 10, 2020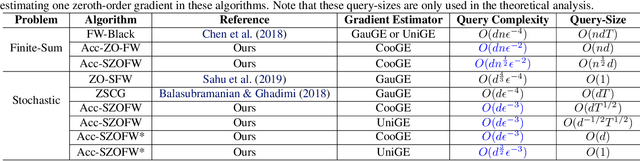
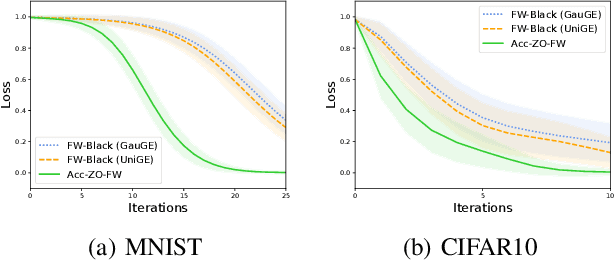
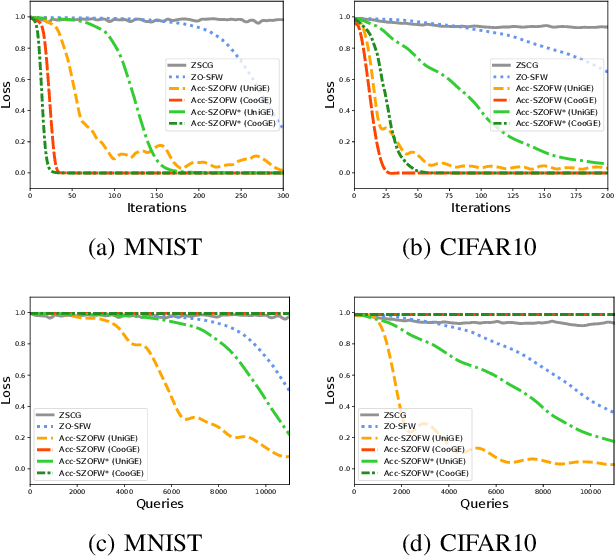
In the paper, we propose a class of accelerated stochastic gradient-free and projection-free (a.k.a., zeroth-order Frank-Wolfe) methods to solve the constrained stochastic and finite-sum nonconvex optimization. Specifically, we propose an accelerated stochastic zeroth-order Frank-Wolfe (Acc-SZOFW) method based on the variance reduced technique of SPIDER/SpiderBoost and a novel momentum accelerated technique. Moreover, under some mild conditions, we prove that the Acc-SZOFW has the function query complexity of $O(d\sqrt{n}\epsilon^{-2})$ for finding an $\epsilon$-stationary point in the finite-sum problem, which improves the exiting best result by a factor of $O(\sqrt{n}\epsilon^{-2})$, and has the function query complexity of $O(d\epsilon^{-3})$ in the stochastic problem, which improves the exiting best result by a factor of $O(\epsilon^{-1})$. To relax the large batches required in the Acc-SZOFW, we further propose a novel accelerated stochastic zeroth-order Frank-Wolfe (Acc-SZOFW*) based on a new variance reduced technique of STORM, which still reaches the function query complexity of $O(d\epsilon^{-3})$ in the stochastic problem without relying on any large batches. In particular, we present an accelerated framework of the Frank-Wolfe methods based on the proposed momentum accelerated technique. The extensive experimental results on black-box adversarial attack and robust black-box classification demonstrate the efficiency of our algorithms.
Faster Stochastic Alternating Direction Method of Multipliers for Nonconvex Optimization
Aug 10, 2020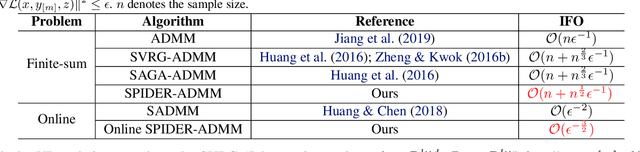
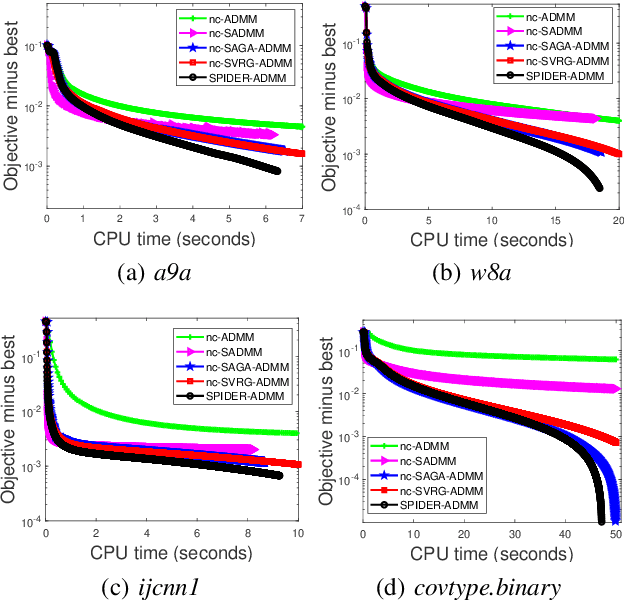
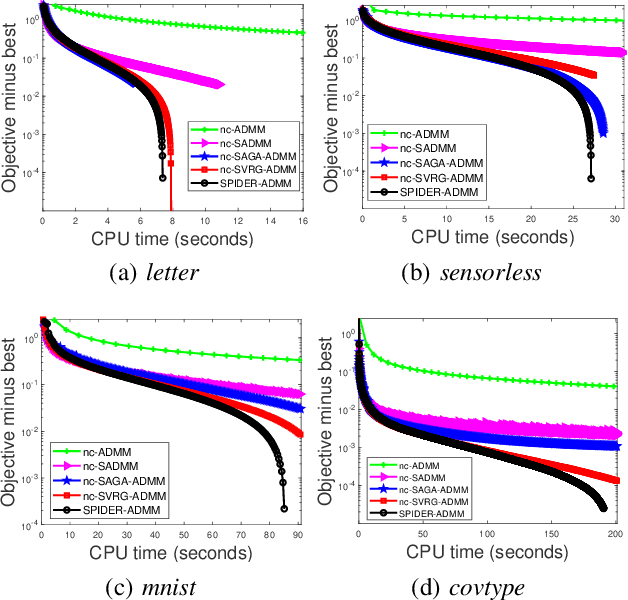
In this paper, we propose a faster stochastic alternating direction method of multipliers (ADMM) for nonconvex optimization by using a new stochastic path-integrated differential estimator (SPIDER), called as SPIDER-ADMM. Moreover, we prove that the SPIDER-ADMM achieves a record-breaking incremental first-order oracle (IFO) complexity of $\mathcal{O}(n+n^{1/2}\epsilon^{-1})$ for finding an $\epsilon$-approximate stationary point, which improves the deterministic ADMM by a factor $\mathcal{O}(n^{1/2})$, where $n$ denotes the sample size. As one of major contribution of this paper, we provide a new theoretical analysis framework for nonconvex stochastic ADMM methods with providing the optimal IFO complexity. Based on this new analysis framework, we study the unsolved optimal IFO complexity of the existing non-convex SVRG-ADMM and SAGA-ADMM methods, and prove they have the optimal IFO complexity of $\mathcal{O}(n+n^{2/3}\epsilon^{-1})$. Thus, the SPIDER-ADMM improves the existing stochastic ADMM methods by a factor of $\mathcal{O}(n^{1/6})$. Moreover, we extend SPIDER-ADMM to the online setting, and propose a faster online SPIDER-ADMM. Our theoretical analysis shows that the online SPIDER-ADMM has the IFO complexity of $\mathcal{O}(\epsilon^{-\frac{3}{2}})$, which improves the existing best results by a factor of $\mathcal{O}(\epsilon^{-\frac{1}{2}})$. Finally, the experimental results on benchmark datasets validate that the proposed algorithms have faster convergence rate than the existing ADMM algorithms for nonconvex optimization.
A Concise yet Effective model for Non-Aligned Incomplete Multi-view and Missing Multi-label Learning
May 03, 2020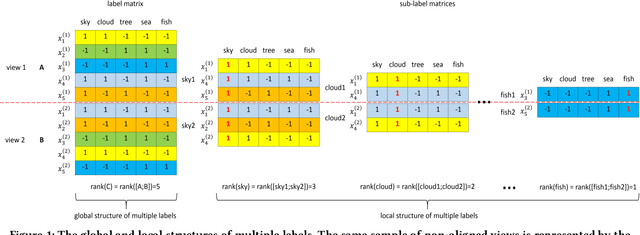
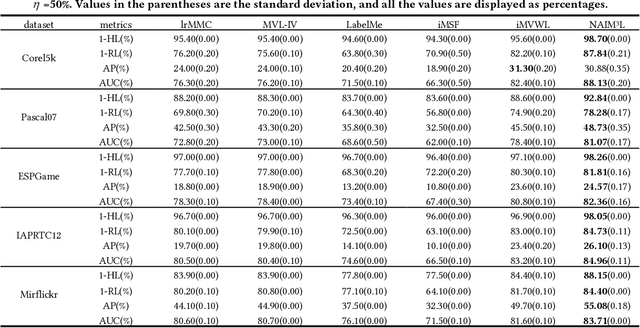
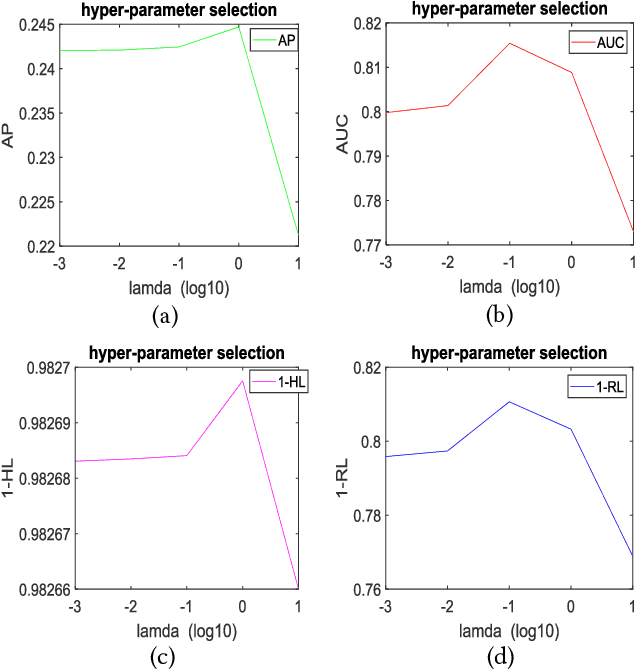
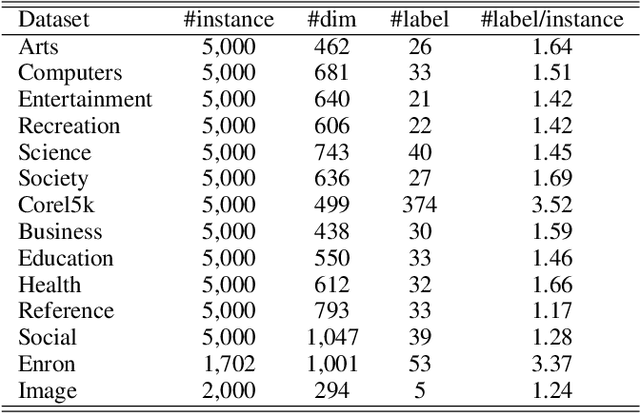
In real-world applications, learning from data with multi-view and multi-label inevitably confronts with three challenges: missing labels, incomplete views, and non-aligned views. Existing methods mainly concern the first two and commonly need multiple assumptions in attacking them, making even state-of-the-arts also involve at least two explicit hyper-parameters in their objectives such that model selection is quite difficult. More toughly, these will encounter a failure in dealing with the third challenge, let alone address the three challenges jointly. In this paper, our goal is to meet all of them by presenting a concise yet effective model with only one hyper-parameter in modeling under the least assumption. To make our model more discriminative, we exploit not only the consensus of multiple views but also the global and local structures among multiple labels. More specifically, we introduce an indicator matrix to tackle the first two challenges in a regression manner while align the same individual label and all labels of different views in a common label space to battle the third challenge. During our alignment, we characterize specially the global and the local structures of multiple labels with high-rank and low-rank, respectively. Consequently, the regularization terms involved in modeling are integrated by a single hyper-parameter. Even without view-alignment, it is still confirmed that our method achieves better performance on five real datasets compared to state-of-the-arts.
A Centroid Auto-Fused Hierarchical Fuzzy c-Means Clustering
Apr 27, 2020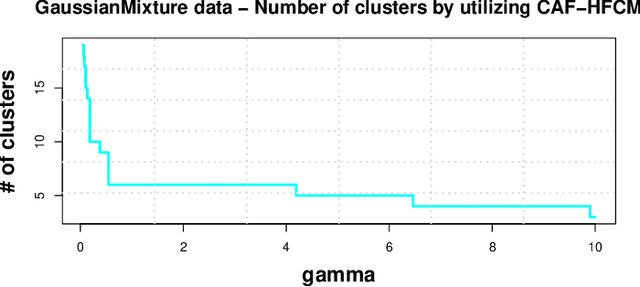
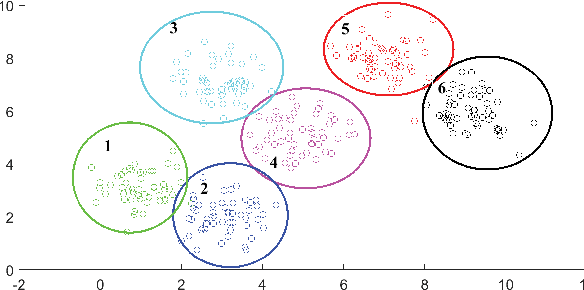
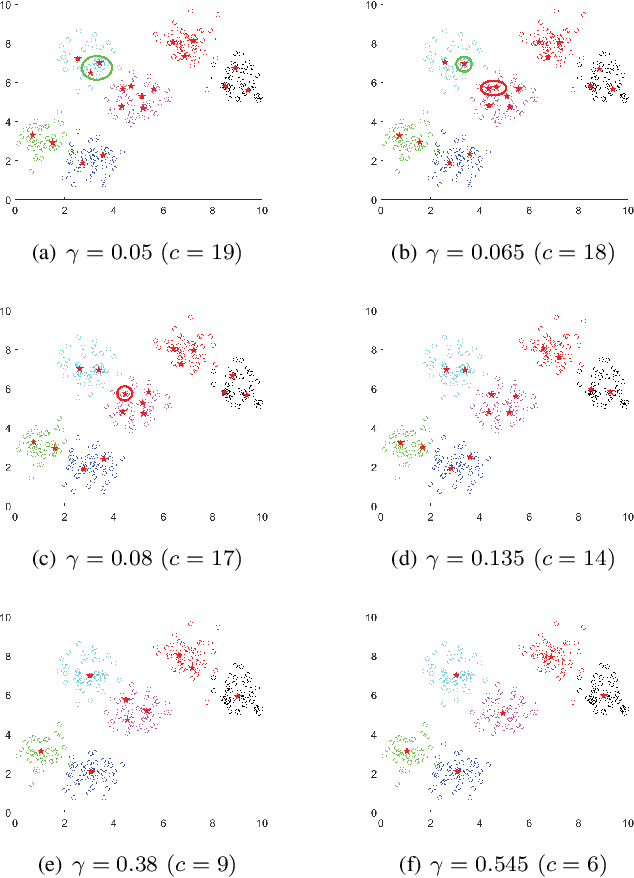
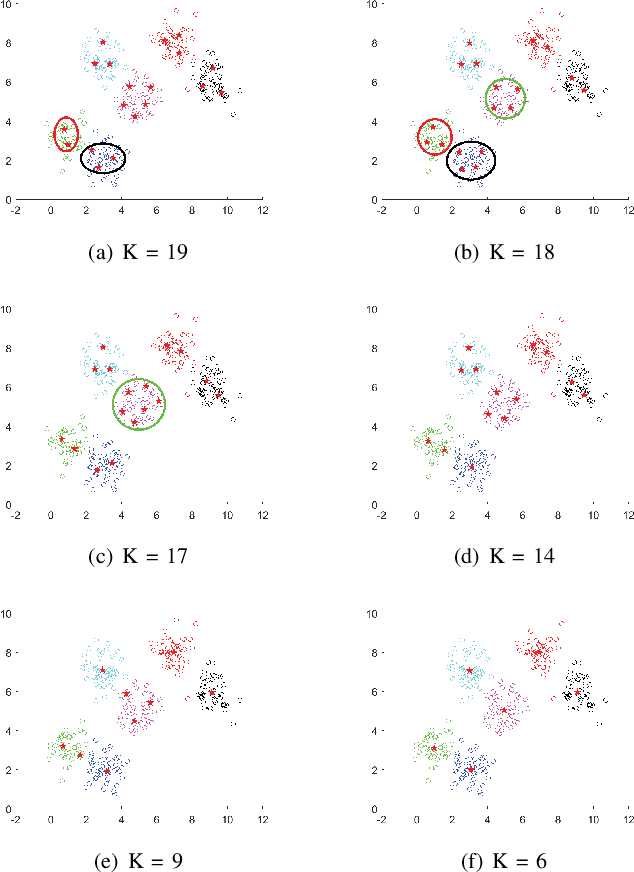
Like k-means and Gaussian Mixture Model (GMM), fuzzy c-means (FCM) with soft partition has also become a popular clustering algorithm and still is extensively studied. However, these algorithms and their variants still suffer from some difficulties such as determination of the optimal number of clusters which is a key factor for clustering quality. A common approach for overcoming this difficulty is to use the trial-and-validation strategy, i.e., traversing every integer from large number like $\sqrt{n}$ to 2 until finding the optimal number corresponding to the peak value of some cluster validity index. But it is scarcely possible to naturally construct an adaptively agglomerative hierarchical cluster structure as using the trial-and-validation strategy. Even possible, existing different validity indices also lead to different number of clusters. To effectively mitigate the problems while motivated by convex clustering, in this paper we present a Centroid Auto-Fused Hierarchical Fuzzy c-means method (CAF-HFCM) whose optimization procedure can automatically agglomerate to form a cluster hierarchy, more importantly, yielding an optimal number of clusters without resorting to any validity index. Although a recently-proposed robust-learning fuzzy c-means (RL-FCM) can also automatically obtain the best number of clusters without the help of any validity index, so-involved 3 hyper-parameters need to adjust expensively, conversely, our CAF-HFCM involves just 1 hyper-parameter which makes the corresponding adjustment is relatively easier and more operational. Further, as an additional benefit from our optimization objective, the CAF-HFCM effectively reduces the sensitivity to the initialization of clustering performance. Moreover, our proposed CAF-HFCM method is able to be straightforwardly extended to various variants of FCM.
Global Expanding, Local Shrinking: Discriminant Multi-label Learning with Missing Labels
Apr 08, 2020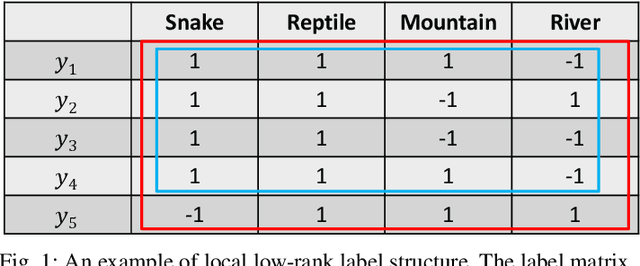
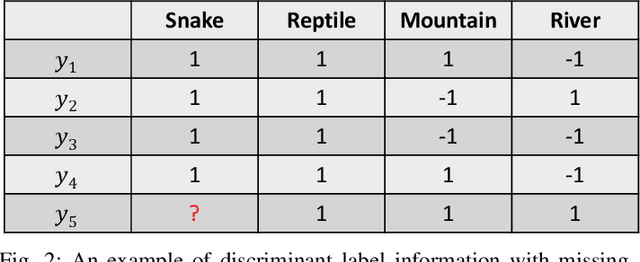
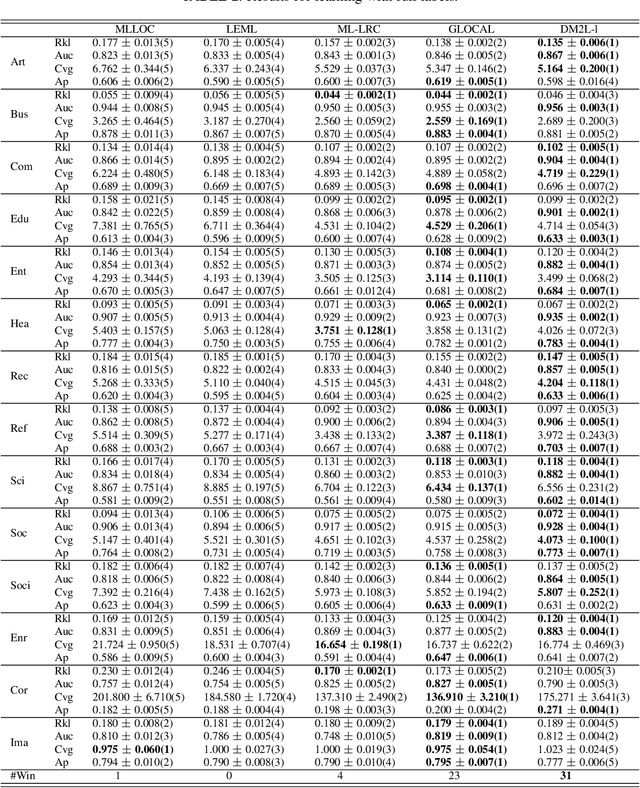
In multi-label learning, the issue of missing labels brings a major challenge. Many methods attempt to recovery missing labels by exploiting low-rank structure of label matrix. However, these methods just utilize global low-rank label structure, ignore both local low-rank label structures and label discriminant information to some extent, leaving room for further performance improvement. In this paper, we develop a simple yet effective discriminant multi-label learning (DM2L) method for multi-label learning with missing labels. Specifically, we impose the low-rank structures on all the predictions of instances from the same labels (local shrinking of rank), and a maximally separated structure (high-rank structure) on the predictions of instances from different labels (global expanding of rank). In this way, these imposed low-rank structures can help modeling both local and global low-rank label structures, while the imposed high-rank structure can help providing more underlying discriminability. Our subsequent theoretical analysis also supports these intuitions. In addition, we provide a nonlinear extension via using kernel trick to enhance DM2L and establish a concave-convex objective to learn these models. Compared to the other methods, our method involves the fewest assumptions and only one hyper-parameter. Even so, extensive experiments show that our method still outperforms the state-of-the-art methods.
Unsupervised Domain Adaptation Through Transferring both the Source-Knowledge and Target-Relatedness Simultaneously
Mar 24, 2020



Unsupervised domain adaptation (UDA) is an emerging research topic in the field of machine learning and pattern recognition, which aims to help the learning of unlabeled target domain by transferring knowledge from the source domain. To perform UDA, a variety of methods have been proposed, most of which concentrate on the scenario of single source and single target domain (1S1T). However, in real applications, usually single source domain with multiple target domains are involved (1SmT), which cannot be handled directly by those 1S1T models. Unfortunately, although a few related works on 1SmT UDA have been proposed, nearly none of them model the source domain knowledge and leverage the target-relatedness jointly. To overcome these shortcomings, we herein propose a more general 1SmT UDA model through transferring both the Source-Knowledge and Target-Relatedness, UDA-SKTR for short. In this way, not only the supervision knowledge from the source domain, but also the potential relatedness among the target domains are simultaneously modeled for exploitation in the process of 1SmT UDA. In addition, we construct an alternating optimization algorithm to solve the variables of the proposed model with convergence guarantee. Finally, through extensive experiments on both benchmark and real datasets, we validate the effectiveness and superiority of the proposed method.
A Multi-view Perspective of Self-supervised Learning
Feb 22, 2020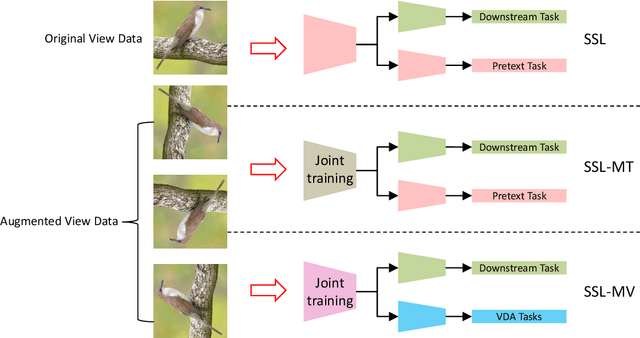
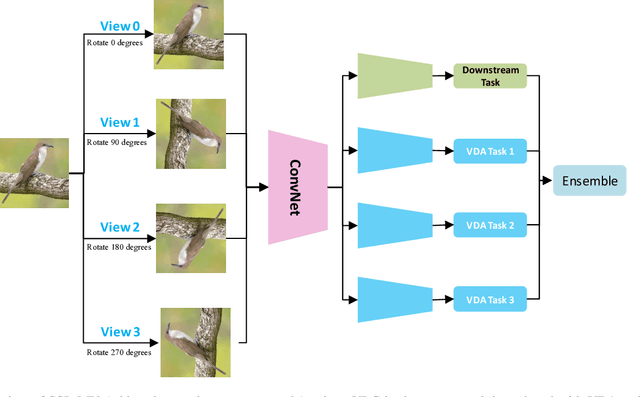
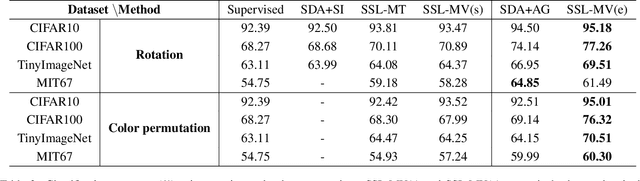
As a newly emerging unsupervised learning paradigm, self-supervised learning (SSL) recently gained widespread attention, which usually introduces a pretext task without manual annotation of data. With its help, SSL effectively learns the feature representation beneficial for downstream tasks. Thus the pretext task plays a key role. However, the study of its design, especially its essence currently is still open. In this paper, we borrow a multi-view perspective to decouple a class of popular pretext tasks into a combination of view data augmentation (VDA) and view label classification (VLC), where we attempt to explore the essence of such pretext task while providing some insights into its design. Specifically, a simple multi-view learning framework is specially designed (SSL-MV), which assists the feature learning of downstream tasks (original view) through the same tasks on the augmented views. SSL-MV focuses on VDA while abandons VLC, empirically uncovering that it is VDA rather than generally considered VLC that dominates the performance of such SSL. Additionally, thanks to replacing VLC with VDA tasks, SSL-MV also enables an integrated inference combining the predictions from the augmented views, further improving the performance. Experiments on several benchmark datasets demonstrate its advantages.
Visual and Semantic Prototypes-Jointly Guided CNN for Generalized Zero-shot Learning
Aug 14, 2019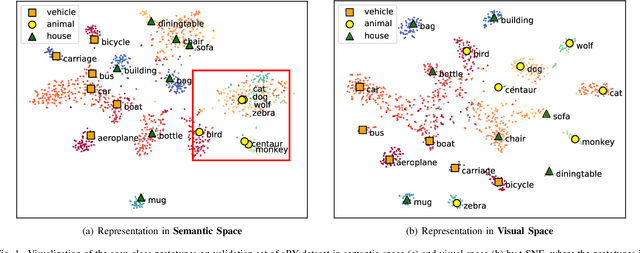
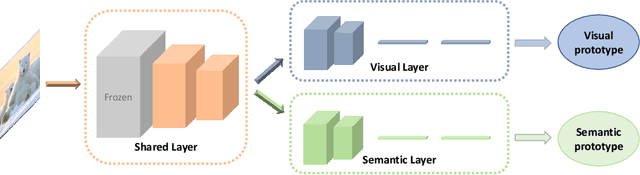


In the process of exploring the world, the curiosity constantly drives humans to cognize new things. Supposing you are a zoologist, for a presented animal image, you can recognize it immediately if you know its class. Otherwise, you would more likely attempt to cognize it by exploiting the side-information (e.g., semantic information, etc.) you have accumulated. Inspired by this, this paper decomposes the generalized zero-shot learning (G-ZSL) task into an open set recognition (OSR) task and a zero-shot learning (ZSL) task, where OSR recognizes seen classes (if we have seen (or known) them) and rejects unseen classes (if we have never seen (or known) them before), while ZSL identifies the unseen classes rejected by the former. Simultaneously, without violating OSR's assumptions (only known class knowledge is available in training), we also first attempt to explore a new generalized open set recognition (G-OSR) by introducing the accumulated side-information from known classes to OSR. For G-ZSL, such a decomposition effectively solves the class overfitting problem with easily misclassifying unseen classes as seen classes. The problem is ubiquitous in most existing G-ZSL methods. On the other hand, for G-OSR, introducing such semantic information of known classes not only improves the recognition performance but also endows OSR with the cognitive ability of unknown classes. Specifically, a visual and semantic prototypes-jointly guided convolutional neural network (VSG-CNN) is proposed to fulfill these two tasks (G-ZSL and G-OSR) in a unified end-to-end learning framework. Extensive experiments on benchmark datasets demonstrate the advantages of our learning framework.
Zeroth-Order Stochastic Alternating Direction Method of Multipliers for Nonconvex Nonsmooth Optimization
May 29, 2019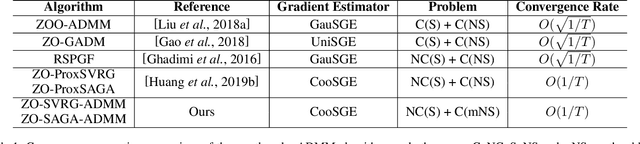
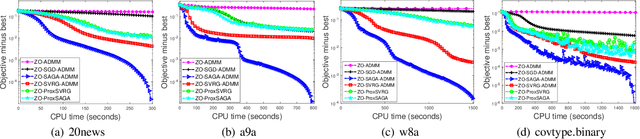
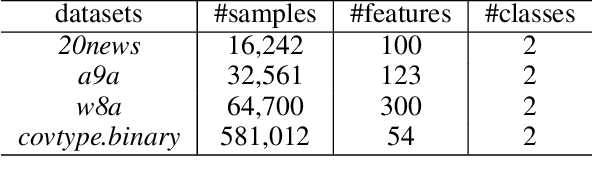

Alternating direction method of multipliers (ADMM) is a popular optimization tool for the composite and constrained problems in machine learning. However, in many machine learning problems such as black-box attacks and bandit feedback, ADMM could fail because the explicit gradients of these problems are difficult or infeasible to obtain. Zeroth-order (gradient-free) methods can effectively solve these problems due to that the objective function values are only required in the optimization. Recently, though there exist a few zeroth-order ADMM methods, they build on the convexity of objective function. Clearly, these existing zeroth-order methods are limited in many applications. In the paper, thus, we propose a class of fast zeroth-order stochastic ADMM methods (i.e., ZO-SVRG-ADMM and ZO-SAGA-ADMM) for solving nonconvex problems with multiple nonsmooth penalties, based on the coordinate smoothing gradient estimator. Moreover, we prove that both the ZO-SVRG-ADMM and ZO-SAGA-ADMM have convergence rate of $O(1/T)$, where $T$ denotes the number of iterations. In particular, our methods not only reach the best convergence rate $O(1/T)$ for the nonconvex optimization, but also are able to effectively solve many complex machine learning problems with multiple regularized penalties and constraints. Finally, we conduct the experiments of black-box binary classification and structured adversarial attack on black-box deep neural network to validate the efficiency of our algorithms.