 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Aligned Incomplete Multi-view Clustering
Mar 07, 2019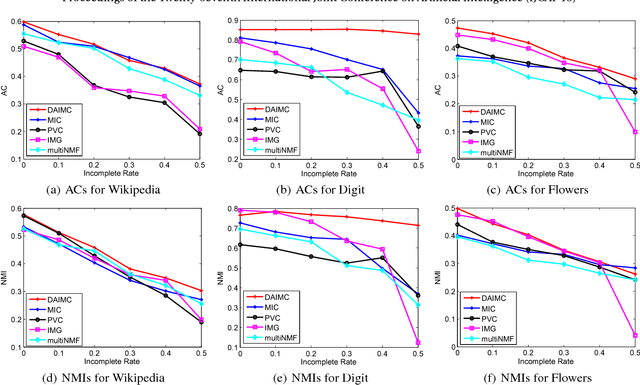
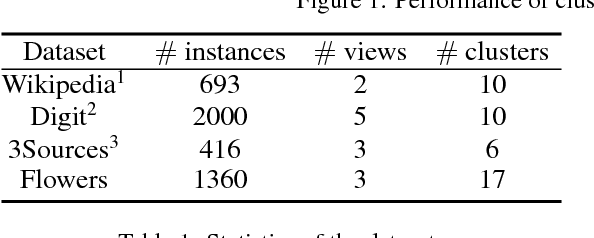
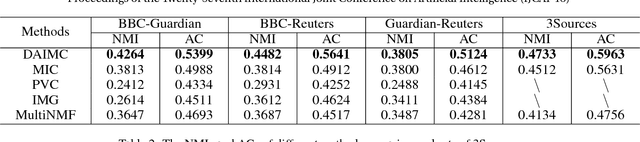
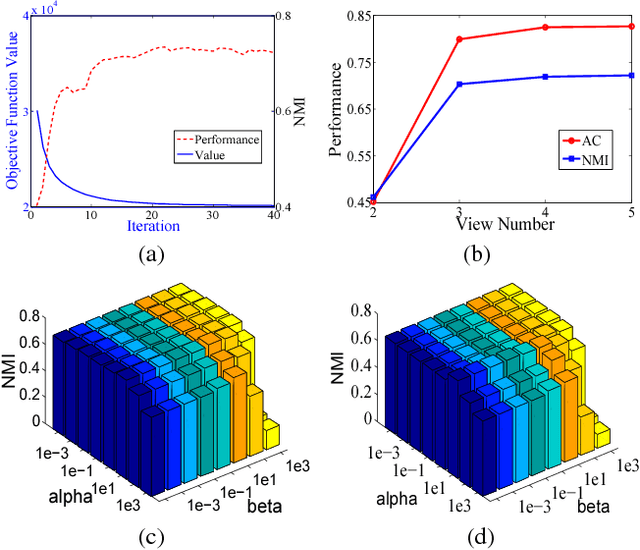
Nowadays, multi-view clustering has attracted more and more attention. To date, almost all the previous studies assume that views are complete. However, in reality, it is often the case that each view may contain some missing instances. Such incompleteness makes it impossible to directly use traditional multi-view clustering methods. In this paper, we propose a Doubly Aligned Incomplete Multi-view Clustering algorithm (DAIMC) based on weighted semi-nonnegative matrix factorization (semi-NMF). Specifically, on the one hand, DAIMC utilizes the given instance alignment information to learn a common latent feature matrix for all the views. On the other hand, DAIMC establishes a consensus basis matrix with the help of $L_{2,1}$-Norm regularized regression for reducing the influence of missing instances. Consequently, compared with existing methods, besides inheriting the strength of semi-NMF with ability to handle negative entries, DAIMC has two unique advantages: 1) solving the incomplete view problem by introducing a respective weight matrix for each view, making it able to easily adapt to the case with more than two views; 2) reducing the influence of view incompleteness on clustering by enforcing the basis matrices of individual views being aligned with the help of regression. Experiments on four real-world datasets demonstrate its advantages.
One-Pass Incomplete Multi-view Clustering
Mar 02, 2019
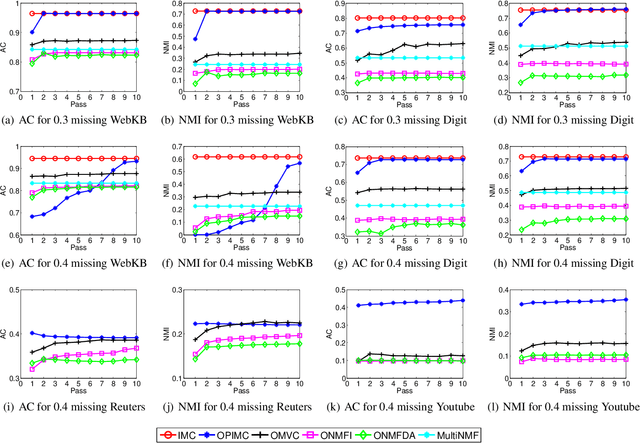
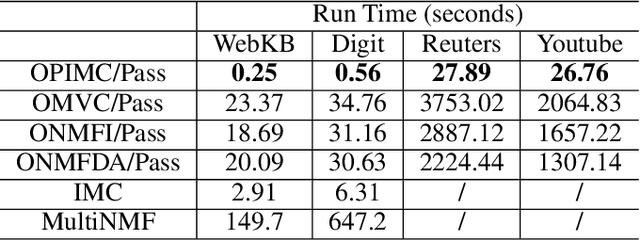
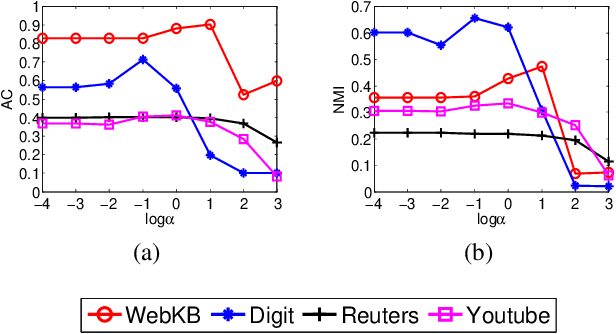
Real data are often with multiple modalities or from multiple heterogeneous sources, thus forming so-called multi-view data, which receives more and more attentions in machine learning. Multi-view clustering (MVC) becomes its important paradigm. In real-world applications, some views often suffer from instances missing. Clustering on such multi-view datasets is called incomplete multi-view clustering (IMC) and quite challenging. To date, though many approaches have been developed, most of them are offline and have high computational and memory costs especially for large scale datasets. To address this problem, in this paper, we propose an One-Pass Incomplete Multi-view Clustering framework (OPIMC). With the help of regularized matrix factorization and weighted matrix factorization, OPIMC can relatively easily deal with such problem. Different from the existing and sole online IMC method, OPIMC can directly get clustering results and effectively determine the termination of iteration process by introducing two global statistics. Finally, extensive experiments conducted on four real datasets demonstrate the efficiency and effectiveness of the proposed OPIMC method.
Multi-target Unsupervised Domain Adaptation without Exactly Shared Categories
Sep 17, 2018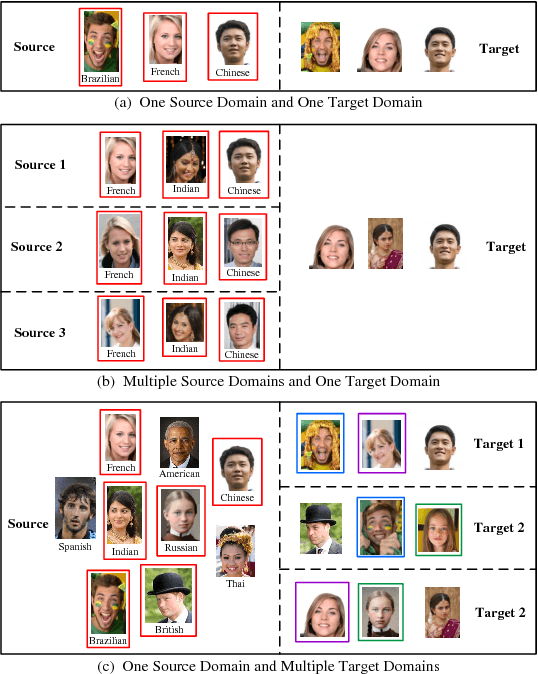
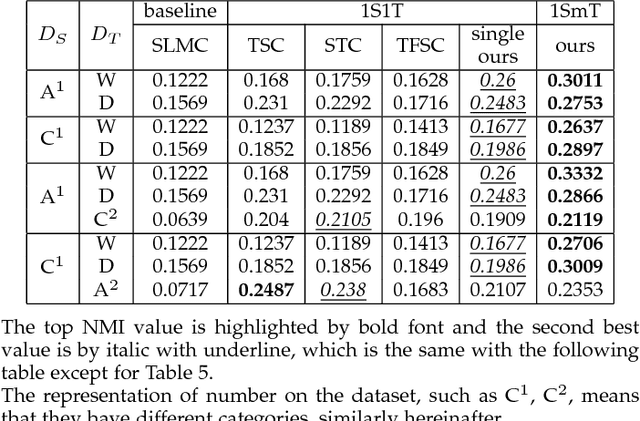
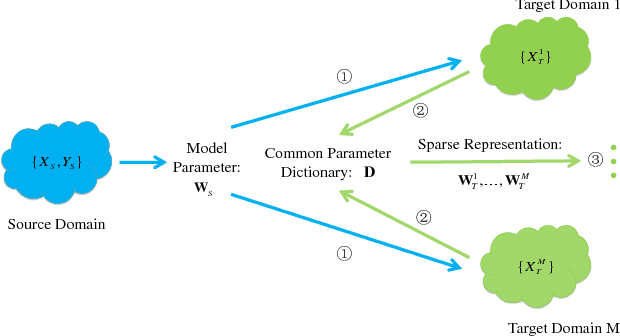
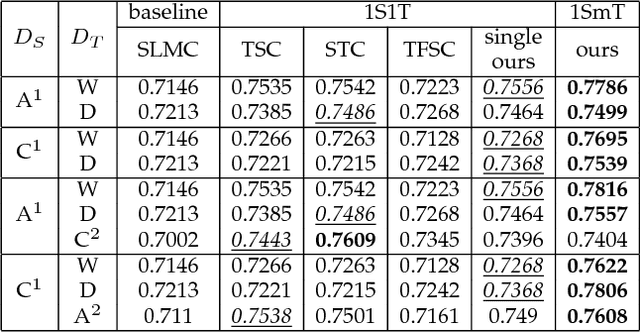
Unsupervised domain adaptation (UDA) aims to learn the unlabeled target domain by transferring the knowledge of the labeled source domain. To date, most of the existing works focus on the scenario of one source domain and one target domain (1S1T), and just a few works concern the scenario of multiple source domains and one target domain (mS1T). While, to the best of our knowledge, almost no work concerns the scenario of one source domain and multiple target domains (1SmT), in which these unlabeled target domains may not necessarily share the same categories, therefore, contrasting to mS1T, 1SmT is more challenging. Accordingly, for such a new UDA scenario, we propose a UDA framework through the model parameter adaptation (PA-1SmT). A key ingredient of PA-1SmT is to transfer knowledge through adaptive learning of a common model parameter dictionary, which is completely different from existing popular methods for UDA, such as subspace alignment, distribution matching etc., and can also be directly used for DA of privacy protection due to the fact that the knowledge is transferred just via the model parameters rather than data itself. Finally, our experimental results on three domain adaptation benchmark datasets demonstrate the superiority of our framework.