 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrill-down: Interactive Retrieval of Complex Scenes using Natural Language Queries
Nov 10, 2019

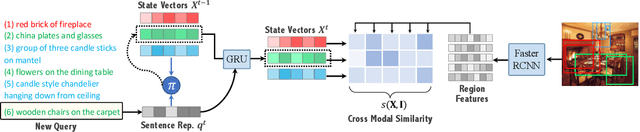
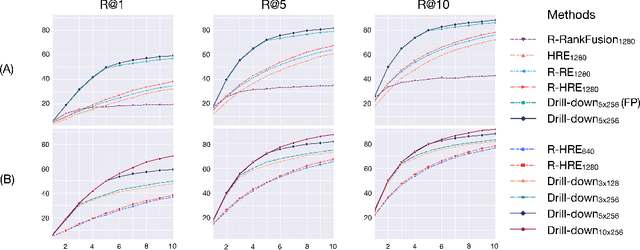
This paper explores the task of interactive image retrieval using natural language queries, where a user progressively provides input queries to refine a set of retrieval results. Moreover, our work explores this problem in the context of complex image scenes containing multiple objects. We propose Drill-down, an effective framework for encoding multiple queries with an efficient compact state representation that significantly extends current methods for single-round image retrieval. We show that using multiple rounds of natural language queries as input can be surprisingly effective to find arbitrarily specific images of complex scenes. Furthermore, we find that existing image datasets with textual captions can provide a surprisingly effective form of weak supervision for this task. We compare our method with existing sequential encoding and embedding networks, demonstrating superior performance on two proposed benchmarks: automatic image retrieval on a simulated scenario that uses region captions as queries, and interactive image retrieval using real queries from human evaluators.
Discrete Residual Flow for Probabilistic Pedestrian Behavior Prediction
Oct 17, 2019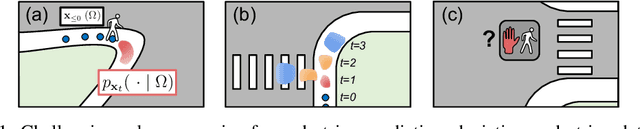
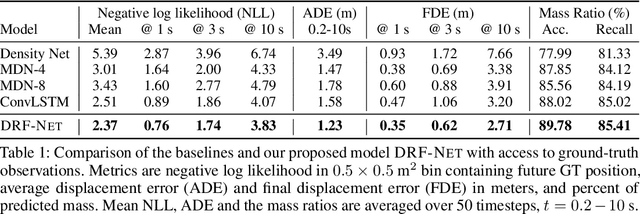
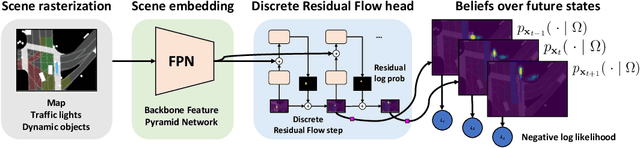
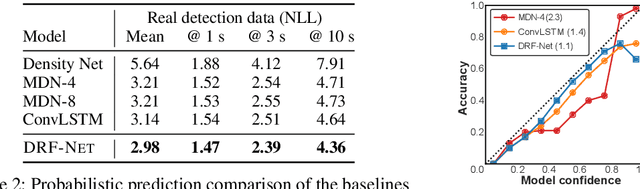
Self-driving vehicles plan around both static and dynamic objects, applying predictive models of behavior to estimate future locations of the objects in the environment. However, future behavior is inherently uncertain, and models of motion that produce deterministic outputs are limited to short timescales. Particularly difficult is the prediction of human behavior. In this work, we propose the discrete residual flow network (DRF-Net), a convolutional neural network for human motion prediction that captures the uncertainty inherent in long-range motion forecasting. In particular, our learned network effectively captures multimodal posteriors over future human motion by predicting and updating a discretized distribution over spatial locations. We compare our model against several strong competitors and show that our model outperforms all baselines.
Chat-crowd: A Dialog-based Platform for Visual Layout Composition
Dec 12, 2018

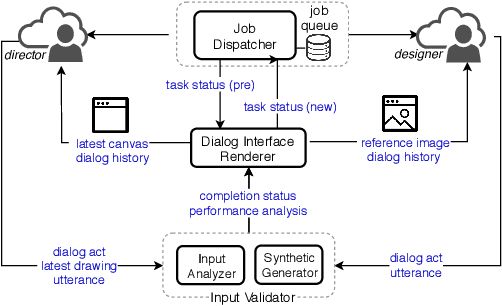
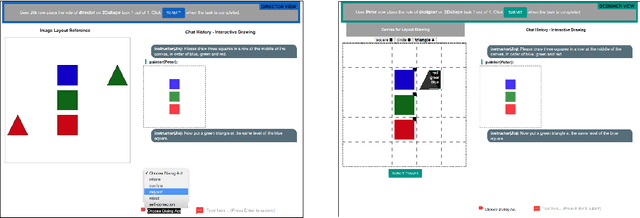
In this paper we introduce Chat-crowd, an interactive environment for visual layout composition via conversational interactions. Chat-crowd supports multiple agents with two conversational roles: agents who play the role of a designer are in charge of placing objects in an editable canvas according to instructions or commands issued by agents with a director role. The system can be integrated with crowdsourcing platforms for both synchronous and asynchronous data collection and is equipped with comprehensive quality controls on the performance of both types of agents. We expect that this system will be useful to build multimodal goal-oriented dialog tasks that require spatial and geometric reasoning.
Text2Scene: Generating Abstract Scenes from Textual Descriptions
Sep 04, 2018
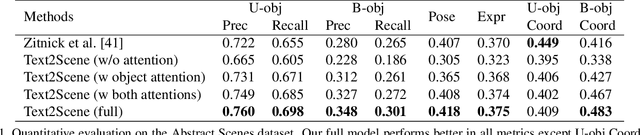
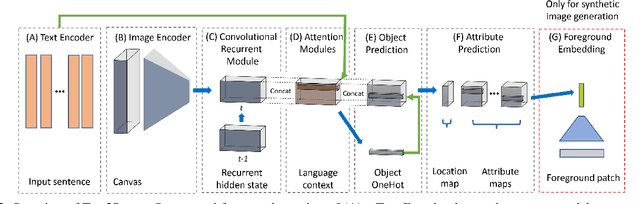

In this paper, we propose an end-to-end model that learns to interpret natural language describing a scene to generate an abstract pictorial representation. The pictorial representations generated by our model comprise the spatial distribution and attributes of the objects in the described scene. Our model uses a sequence-to-sequence network with a double attentive mechanism and introduces a regularization strategy. These scene representations can be sampled from our model similarly as in language-generation models. We show that the proposed model, initially designed to handle the generation of cartoon-like pictorial representations in the Abstract Scenes Dataset, can also handle, under minimal modifications, the generation of semantic layouts corresponding to real images in the COCO dataset. Human evaluations using a visual entailment task show that pictorial representations generated with our full model can entail at least one out of three input visual descriptions 94% of the times, and at least two out of three 62% of the times for each image.
A Subpixel Registration Algorithm for Low PSNR Images
Mar 31, 2018
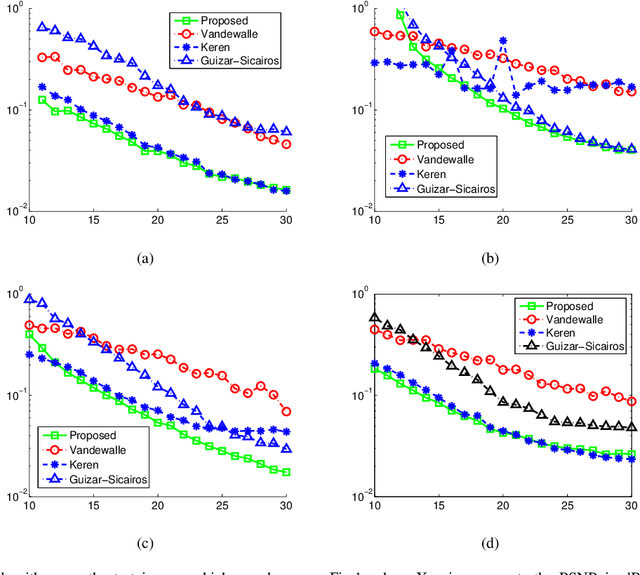
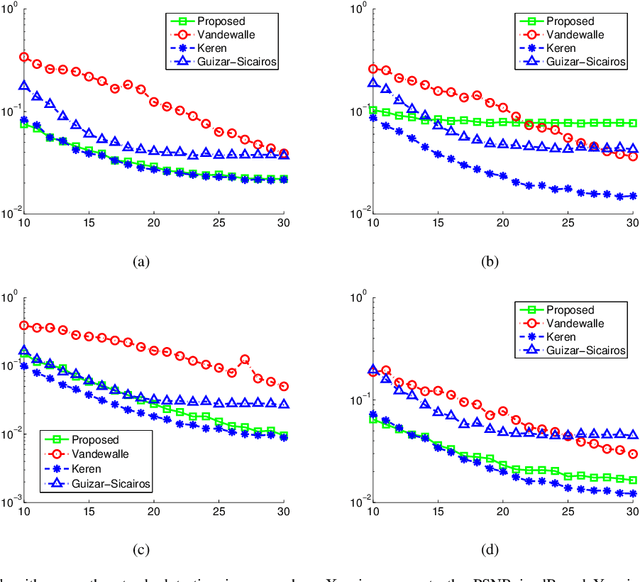
This paper presents a fast algorithm for obtaining high-accuracy subpixel translation of low PSNR images. Instead of locating the maximum point on the upsampled images or fitting the peak of correlation surface, the proposed algorithm is based on the measurement of centroid on the cross correlation surface by Modified Moment method. Synthetic images, real solar images and standard testing images with white Gaussian noise added were tested, and the results show that the accuracies of our algorithm are comparable with other subpixel registration techniques and the processing speed is higher. The drawback is also discussed at the end of this paper.
A Unified Implicit Dialog Framework for Conversational Search
Feb 12, 2018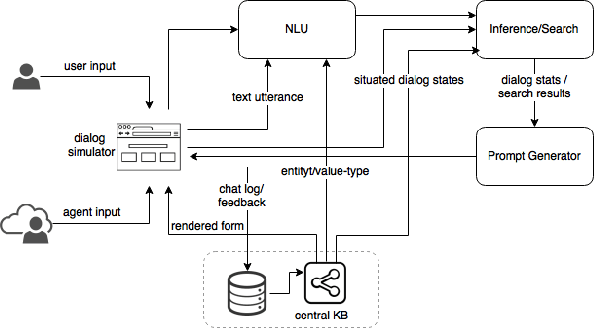
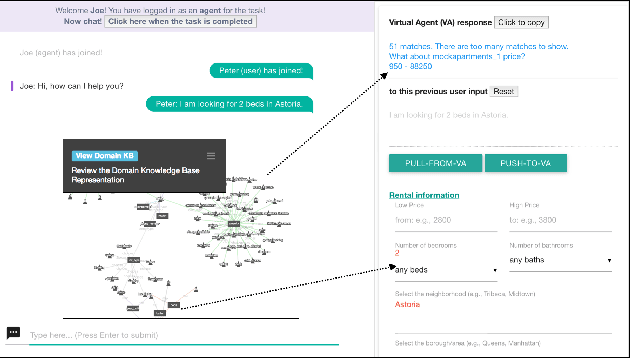
We propose a unified Implicit Dialog framework for goal-oriented, information seeking tasks of Conversational Search applications. It aims to enable dialog interactions with domain data without replying on explicitly encoded the rules but utilizing the underlying data representation to build the components required for dialog interaction, which we refer as Implicit Dialog in this work. The proposed framework consists of a pipeline of End-to-End trainable modules. A centralized knowledge representation is used to semantically ground multiple dialog modules. An associated set of tools are integrated with the framework to gather end users' input for continuous improvement of the system. The goal is to facilitate development of conversational systems by identifying the components and the data that can be adapted and reused across many end-user applications. We demonstrate our approach by creating conversational agents for several independent domains.