 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Decoding with Wasserstein-Regularized Truncation and Mass Penalties for Large Language Models
Feb 10, 2026Large language models (LLMs) must balance diversity and creativity against logical coherence in open-ended generation. Existing truncation-based samplers are effective but largely heuristic, relying mainly on probability mass and entropy while ignoring semantic geometry of the token space. We present Top-W, a geometry-aware truncation rule that uses Wasserstein distance-defined over token-embedding geometry-to keep the cropped distribution close to the original, while explicitly balancing retained probability mass against the entropy of the kept set. Our theory yields a simple closed-form structure for the fixed-potential subset update: depending on the mass-entropy trade-off, the optimal crop either collapses to a single token or takes the form of a one-dimensional prefix that can be found efficiently with a linear scan. We implement Top-W using efficient geometry-based potentials (nearest-set or k-NN) and pair it with an alternating decoding routine that keeps the standard truncation-and-sampling interface unchanged. Extensive experiments on four benchmarks (GSM8K, GPQA, AlpacaEval, and MT-Bench) across three instruction-tuned models show that Top-W consistently outperforms prior state-of-the-art decoding approaches achieving up to 33.7% improvement. Moreover, we find that Top-W not only improves accuracy-focused performance, but also boosts creativity under judge-based open-ended evaluation.
Learning Contraction Policies from Offline Data
Dec 11, 2021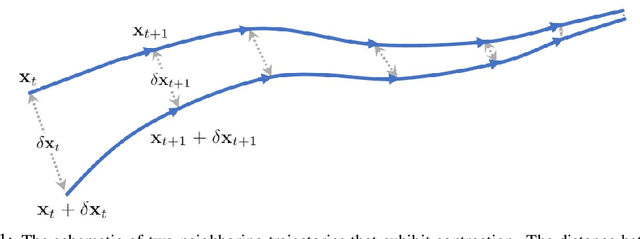

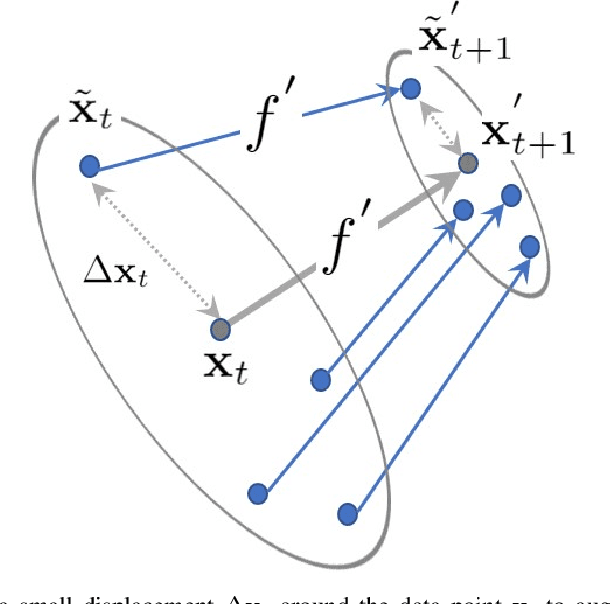
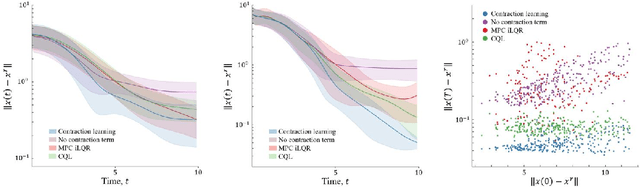
This paper proposes a data-driven method for learning convergent control policies from offline data using Contraction theory. Contraction theory enables constructing a policy that makes the closed-loop system trajectories inherently convergent towards a unique trajectory. At the technical level, identifying the contraction metric, which is the distance metric with respect to which a robot's trajectories exhibit contraction is often non-trivial. We propose to jointly learn the control policy and its corresponding contraction metric while enforcing contraction. To achieve this, we learn an implicit dynamics model of the robotic system from an offline data set consisting of the robot's state and input trajectories. Using this learned dynamics model, we propose a data augmentation algorithm for learning contraction policies. We randomly generate samples in the state-space and propagate them forward in time through the learned dynamics model to generate auxiliary sample trajectories. We then learn both the control policy and the contraction metric such that the distance between the trajectories from the offline data set and our generated auxiliary sample trajectories decreases over time. We evaluate the performance of our proposed framework on simulated robotic goal-reaching tasks and demonstrate that enforcing contraction results in faster convergence and greater robustness of the learned policy.
A sub-modular receding horizon solution for mobile multi-agent persistent monitoring
Aug 12, 2019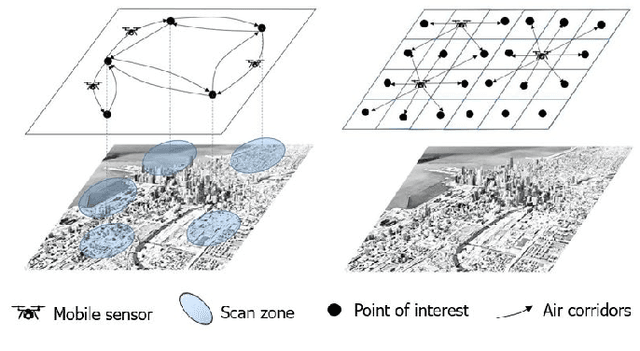
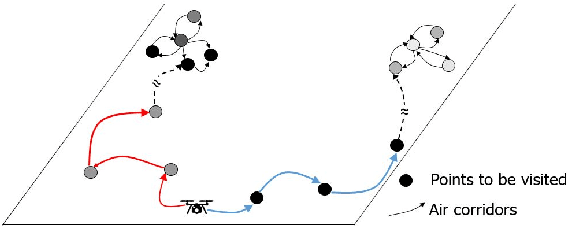
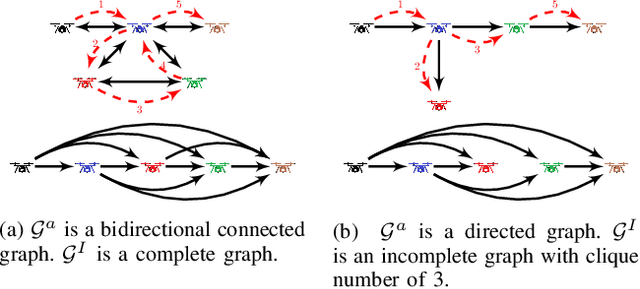
We study the problem of persistent monitoring of finite number of inter-connected geographical nodes for event detection via a group of heterogeneous mobile agents. We use Poisson process model to capture the probability of the events occurring at the geographical nodes. We then tie a utility function to the probability of detecting an event in each point of interest and use it in our policy design to incentivize the agents to visit the geographical nodes with higher probability of event occurrence. We show that the design of an optimal monitoring policy to maximize the utility of event detection over a mission horizon is an NP-hard problem. By showing that the reward function is a monotone increasing and submodular function, we then proceed to propose a suboptimal dispatch policy design with a known optimality gap. To reduce the time complexity of constructing the feasible search set and also to induce robustness to changes in event occurrence and other operational factors, we preform our suboptimal policy design in a receding horizon setting. Our next contribution is to add a new term to our optimization problem to compensate for the shortsightedness of the receding horizon approach. This added term provides a measure of importance for nodes beyond the receding horizon's sight, and is meant to give the policy design an intuition to steer the agents towards areas with higher importance on the global map. Finally, we discuss how our proposed algorithm can be implemented in a decentralized manner. We demonstrate our results through a simulation study.