 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacTweet: Profiling Fake News Twitter Accounts
Oct 15, 2019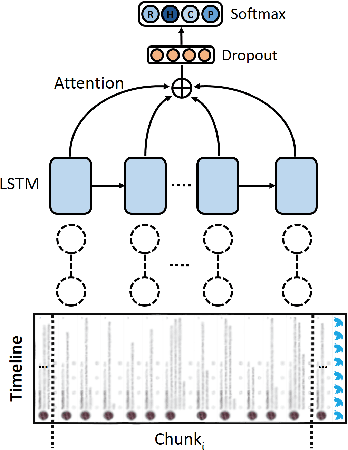
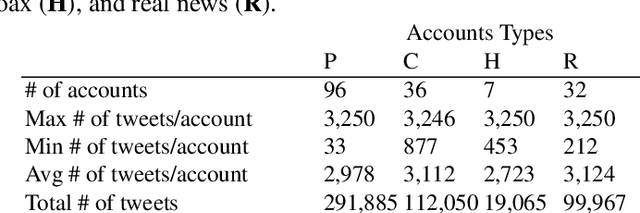
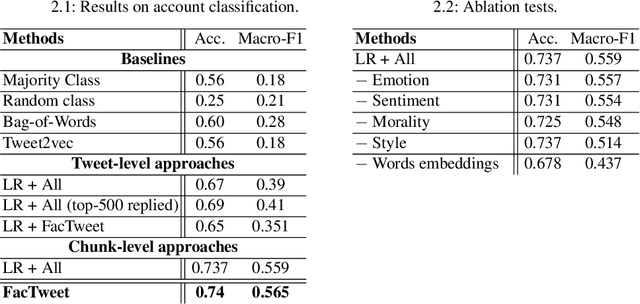
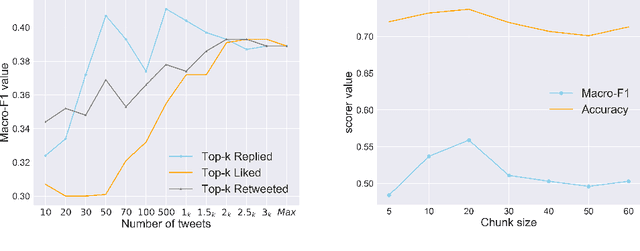
We present an approach to detect fake news in Twitter at the account level using a neural recurrent model and a variety of different semantic and stylistic features. Our method extracts a set of features from the timelines of news Twitter accounts by reading their posts as chunks, rather than dealing with each tweet independently. We show the experimental benefits of modeling latent stylistic signatures of mixed fake and real news with a sequential model over a wide range of strong baselines.
A General Framework for Implicit and Explicit Debiasing of Distributional Word Vector Spaces
Sep 13, 2019
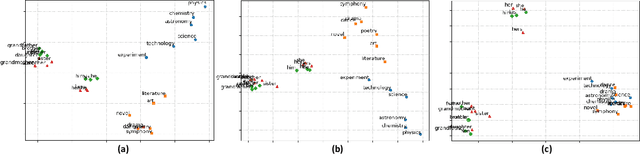
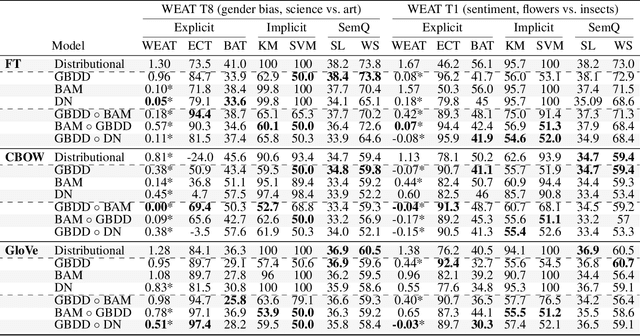
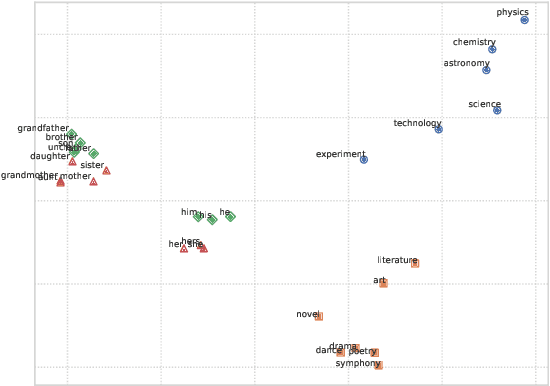
Distributional word vectors have recently been shown to encode many of the human biases, most notably gender and racial biases, and models for attenuating such biases have consequently been proposed. However, existing models and studies (1) operate on under-specified and mutually differing bias definitions, (2) are tailored for a particular bias (e.g., gender bias) and (3) have been evaluated inconsistently and non-rigorously. In this work, we introduce a general framework for debiasing word embeddings. We operationalize the definition of a bias by discerning two types of bias specification: explicit and implicit. We then propose three debiasing models that operate on explicit or implicit bias specifications, and that can be composed towards more robust debiasing. Finally, we devise a full-fledged evaluation framework in which we couple existing bias metrics with newly proposed ones. Experimental findings across three embedding methods suggest that the proposed debiasing models are robust and widely applicable: they often completely remove the bias both implicitly and explicitly, without degradation of semantic information encoded in any of the input distributional spaces. Moreover, we successfully transfer debiasing models, by means of crosslingual embedding spaces, and remove or attenuate biases in distributional word vector spaces of languages that lack readily available bias specifications.
Unmasking Bias in News
Jun 11, 2019

We present experiments on detecting hyperpartisanship in news using a 'masking' method that allows us to assess the role of style vs. content for the task at hand. Our results corroborate previous research on this task in that topic related features yield better results than stylistic ones. We additionally show that competitive results can be achieved by simply including higher-length n-grams, which suggests the need to develop more challenging datasets and tasks that address implicit and more subtle forms of bias.
Political Text Scaling Meets Computational Semantics
May 08, 2019
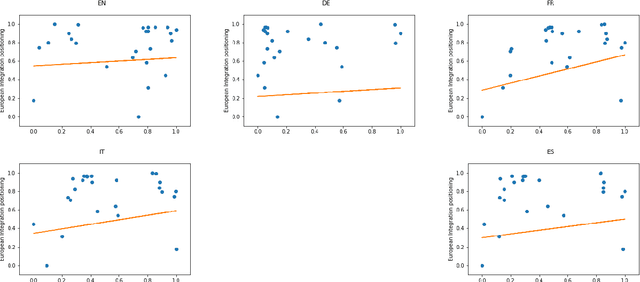
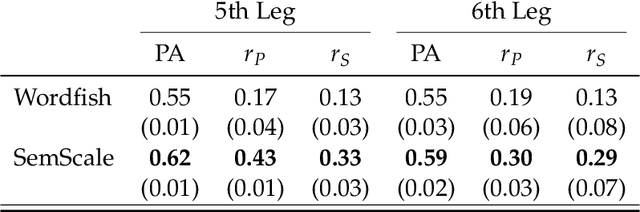
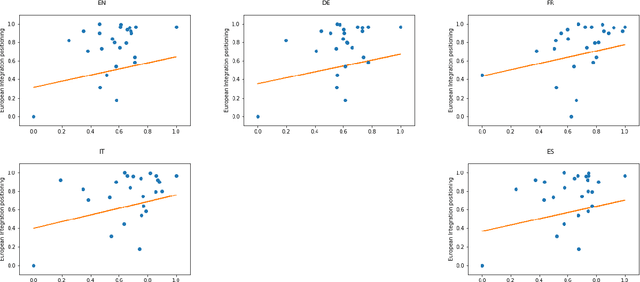
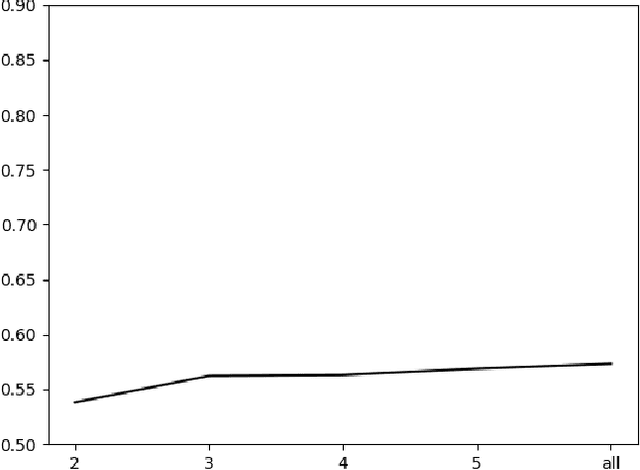
During the last fifteen years, text scaling approaches have become a central element for the text-as-data community. However, they are based on the assumption that latent positions can be captured just by modeling word-frequency information from the different documents under study. We challenge this by presenting a new semantically aware unsupervised scaling algorithm, SemScale, which relies upon distributional representations of the documents under study. We conduct an extensive quantitative analysis over a collection of speeches from the European Parliament in five different languages and from two different legislations, in order to understand whether a) an approach that is aware of semantics would better capture known underlying political dimensions compared to a frequency-based scaling method, b) such positioning correlates in particular with a specific subset of linguistic traits, compared to the use of the entire text, and c) these findings hold across different languages. To support further research on this new branch of text scaling approaches, we release the employed dataset and evaluation setting, an easy-to-use online demo, and a Python implementation of SemScale.
HHMM at SemEval-2019 Task 2: Unsupervised Frame Induction using Contextualized Word Embeddings
May 05, 2019

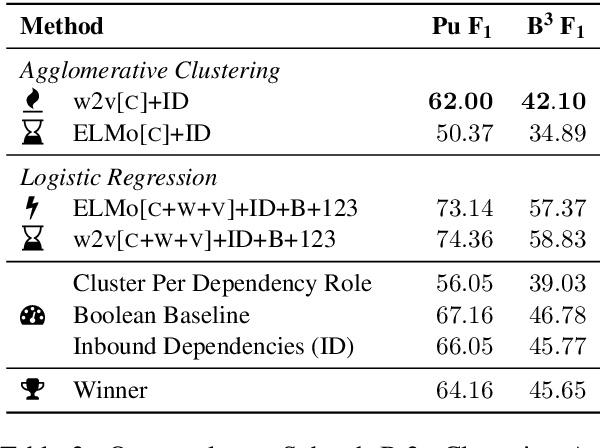
We present our system for semantic frame induction that showed the best performance in Subtask B.1 and finished as the runner-up in Subtask A of the SemEval 2019 Task 2 on unsupervised semantic frame induction (QasemiZadeh et al., 2019). Our approach separates this task into two independent steps: verb clustering using word and their context embeddings and role labeling by combining these embeddings with syntactical features. A simple combination of these steps shows very competitive results and can be extended to process other datasets and languages.
Knowledge-rich Image Gist Understanding Beyond Literal Meaning
Apr 18, 2019
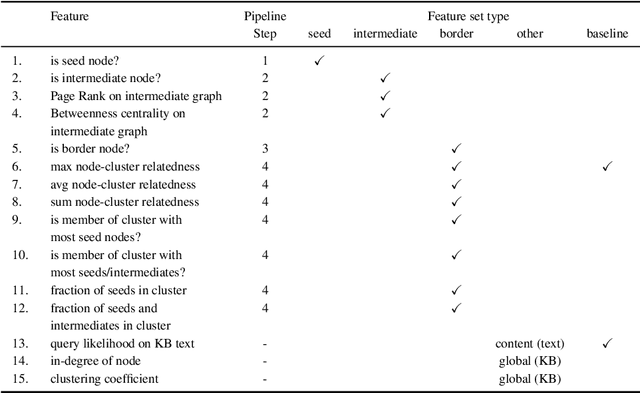
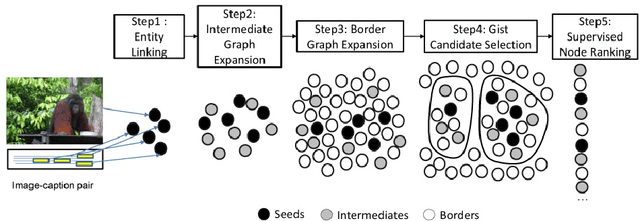

We investigate the problem of understanding the message (gist) conveyed by images and their captions as found, for instance, on websites or news articles. To this end, we propose a methodology to capture the meaning of image-caption pairs on the basis of large amounts of machine-readable knowledge that has previously been shown to be highly effective for text understanding. Our method identifies the connotation of objects beyond their denotation: where most approaches to image understanding focus on the denotation of objects, i.e., their literal meaning, our work addresses the identification of connotations, i.e., iconic meanings of objects, to understand the message of images. We view image understanding as the task of representing an image-caption pair on the basis of a wide-coverage vocabulary of concepts such as the one provided by Wikipedia, and cast gist detection as a concept-ranking problem with image-caption pairs as queries. To enable a thorough investigation of the problem of gist understanding, we produce a gold standard of over 300 image-caption pairs and over 8,000 gist annotations covering a wide variety of topics at different levels of abstraction. We use this dataset to experimentally benchmark the contribution of signals from heterogeneous sources, namely image and text. The best result with a Mean Average Precision (MAP) of 0.69 indicate that by combining both dimensions we are able to better understand the meaning of our image-caption pairs than when using language or vision information alone. We test the robustness of our gist detection approach when receiving automatically generated input, i.e., using automatically generated image tags or generated captions, and prove the feasibility of an end-to-end automated process.
Providing Advanced Access to Historical War Memoirs Through the Identification of Events, Participants and Roles
Apr 08, 2019

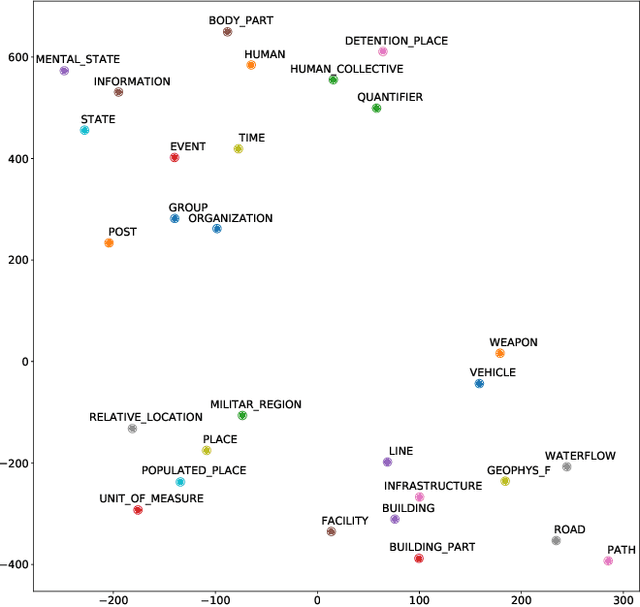
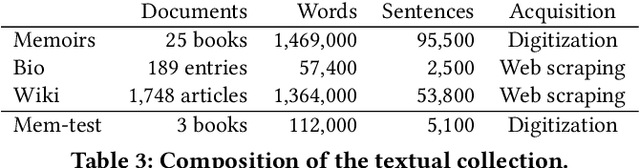
The progressive digitization of historical archives provides new, often domain specific, textual resources that report on facts and events happened in the past; among them, memoirs are a very common type of primary source. In this paper, we present an approach for extracting information from historical war memoirs and turning it into structured knowledge. This is based on the semantic notions of events, participants and roles. We assess quantitatively each of the key-steps of our approach and provide a graph-based representation of the extracted knowledge, which allows the end user to move between close and distant reading of the collection.
Unsupervised Sense-Aware Hypernymy Extraction
Sep 17, 2018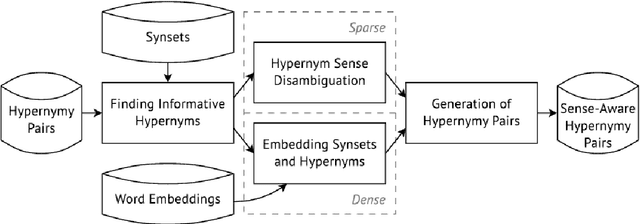
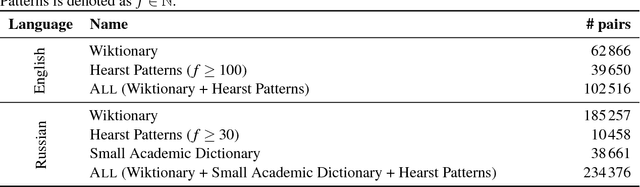
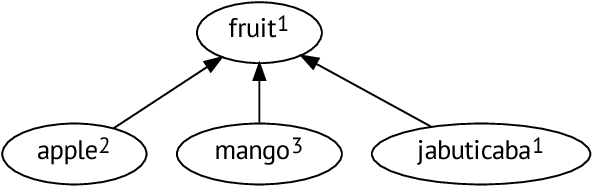

In this paper, we show how unsupervised sense representations can be used to improve hypernymy extraction. We present a method for extracting disambiguated hypernymy relationships that propagates hypernyms to sets of synonyms (synsets), constructs embeddings for these sets, and establishes sense-aware relationships between matching synsets. Evaluation on two gold standard datasets for English and Russian shows that the method successfully recognizes hypernymy relationships that cannot be found with standard Hearst patterns and Wiktionary datasets for the respective languages.
Local-Global Graph Clustering with Applications in Sense and Frame Induction
Aug 20, 2018We present Watset, a new meta-algorithm for fuzzy graph clustering. This algorithm creates an intermediate representation of the input graph that naturally reflects the "ambiguity" of its nodes. It uses hard clustering to discover clusters in this "disambiguated" intermediate graph. After outlining the approach and analyzing its computational complexity, we demonstrate that Watset shows excellent results in two applications: unsupervised synset induction from a synonymy graph and unsupervised semantic frame induction from dependency triples. The presented algorithm is generic and can be also applied to other networks of linguistic data.
Unsupervised Semantic Frame Induction using Triclustering
May 18, 2018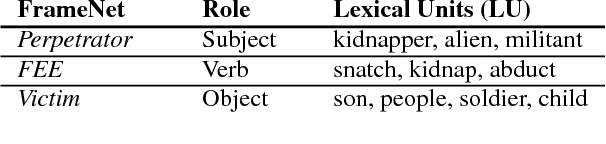
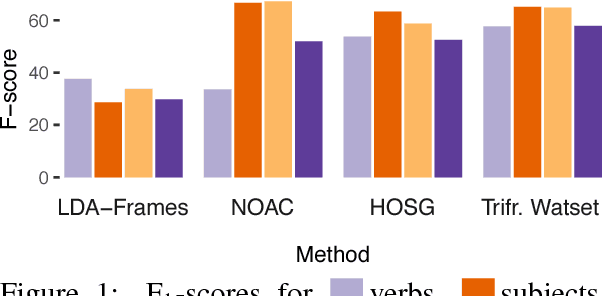

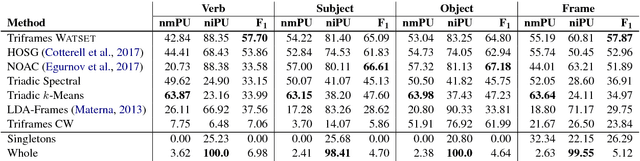
We use dependency triples automatically extracted from a Web-scale corpus to perform unsupervised semantic frame induction. We cast the frame induction problem as a triclustering problem that is a generalization of clustering for triadic data. Our replicable benchmarks demonstrate that the proposed graph-based approach, Triframes, shows state-of-the art results on this task on a FrameNet-derived dataset and performing on par with competitive methods on a verb class clustering task.