 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal fine-tuning for early risk detection
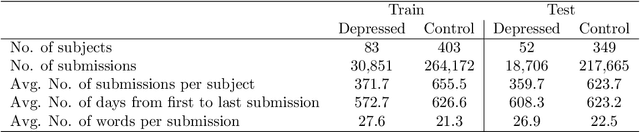
May 16, 2025Early Risk Detection (ERD) on the Web aims to identify promptly users facing social and health issues. Users are analyzed post-by-post, and it is necessary to guarantee correct and quick answers, which is particularly challenging in critical scenarios. ERD involves optimizing classification precision and minimizing detection delay. Standard classification metrics may not suffice, resorting to specific metrics such as ERDE(theta) that explicitly consider precision and delay. The current research focuses on applying a multi-objective approach, prioritizing classification performance and establishing a separate criterion for decision time. In this work, we propose a completely different strategy, temporal fine-tuning, which allows tuning transformer-based models by explicitly incorporating time within the learning process. Our method allows us to analyze complete user post histories, tune models considering different contexts, and evaluate training performance using temporal metrics. We evaluated our proposal in the depression and eating disorders tasks for the Spanish language, achieving competitive results compared to the best models of MentalRiskES 2023. We found that temporal fine-tuning optimized decisions considering context and time progress. In this way, by properly taking advantage of the power of transformers, it is possible to address ERD by combining precision and speed as a single objective.
PySS3: A Python package implementing a novel text classifier with visualization tools for Explainable AI
Dec 19, 2019
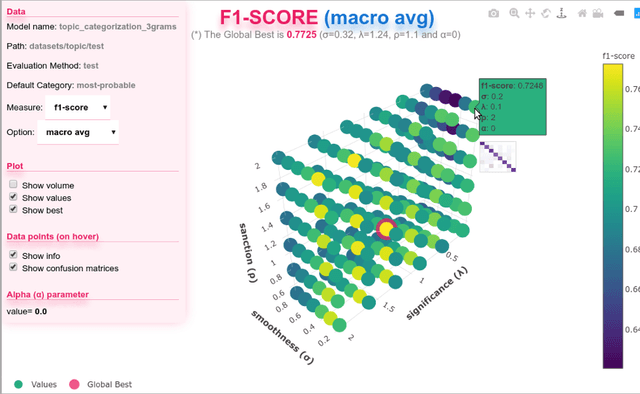
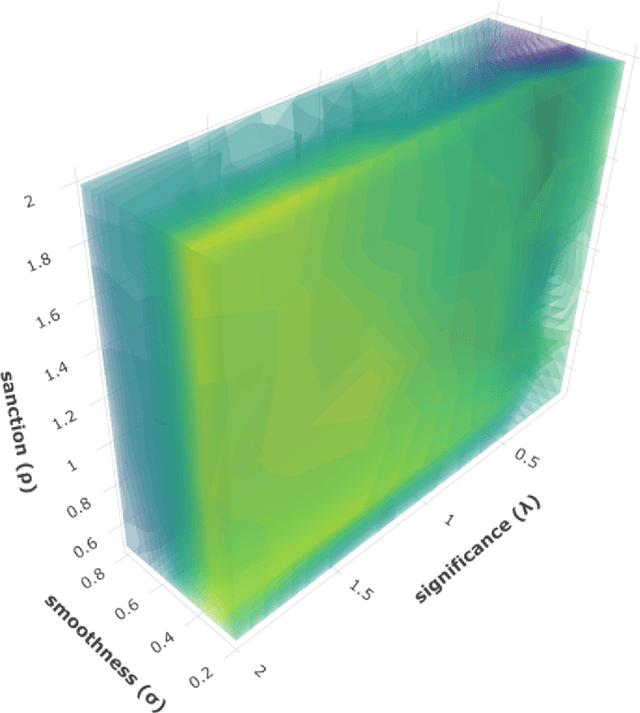

A recently introduced text classifier, called SS3, has obtained state-of-the-art performance on the CLEF's eRisk tasks. SS3 was created to deal with risk detection over text streams and therefore not only supports incremental training and classification but also can visually explain its rationale. However, little attention has been paid to the potential use of SS3 as a general classifier. We believe this could be due to the unavailability of an open-source implementation of SS3. In this work, we introduce PySS3, a package that not only implements SS3 but also comes with visualization tools that allow researchers deploying robust, explainable and trusty machine learning models for text classification.
t-SS3: a text classifier with dynamic n-grams for early risk detection over text streams
Nov 11, 2019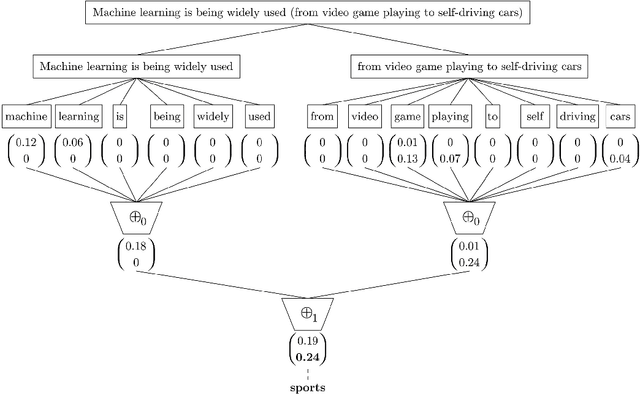
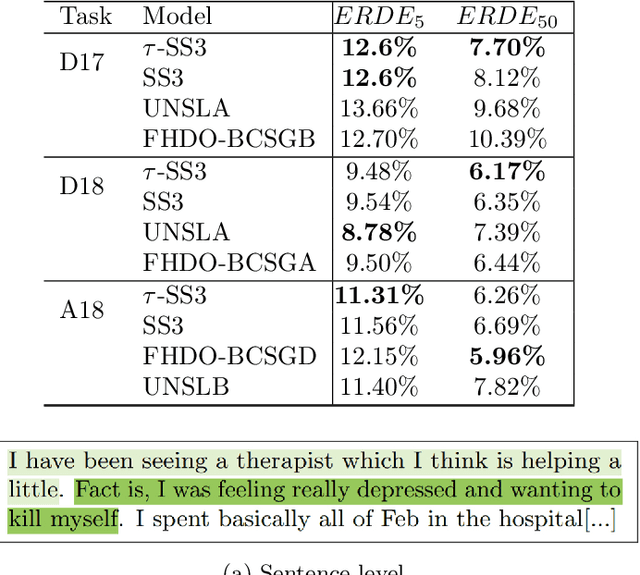
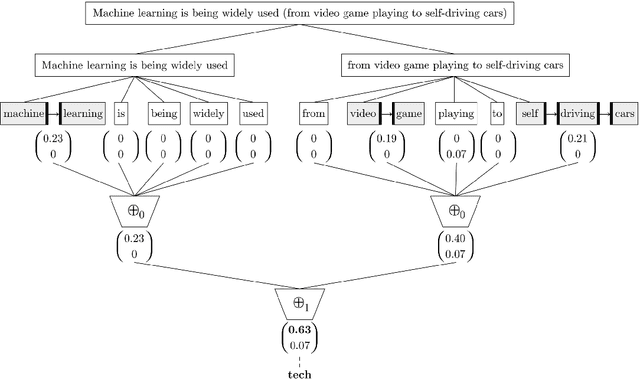
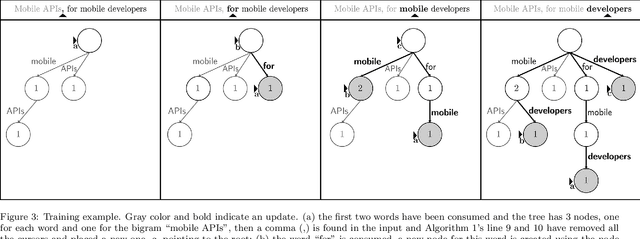
A recently introduced classifier, called SS3, has shown to be well suited to deal with early risk detection (ERD) problems on text streams. It obtained state-of-the-art performance on early depression and anorexia detection on Reddit in the CLEF's eRisk open tasks. SS3 was created to naturally deal with ERD problems since: it supports incremental training and classification over text streams and it can visually explain its rationale. However, SS3 processes the input using a bag-of-word model lacking the ability to recognize important word sequences. This could negatively affect the classification performance and also reduces the descriptiveness of visual explanations. In the standard document classification field, it is very common to use word n-grams to try to overcome some of these limitations. Unfortunately, when working with text streams, using n-grams is not trivial since the system must learn and recognize which n-grams are important ``on the fly''. This paper introduces t-SS3, a variation of SS3 which expands the model to dynamically recognize useful patterns over text streams. We evaluated our model on the eRisk 2017 and 2018 tasks on early depression and anorexia detection. Experimental results show that t-SS3 is able to improve both, existing results and the richness of visual explanations.
Unmasking Bias in News
Jun 11, 2019

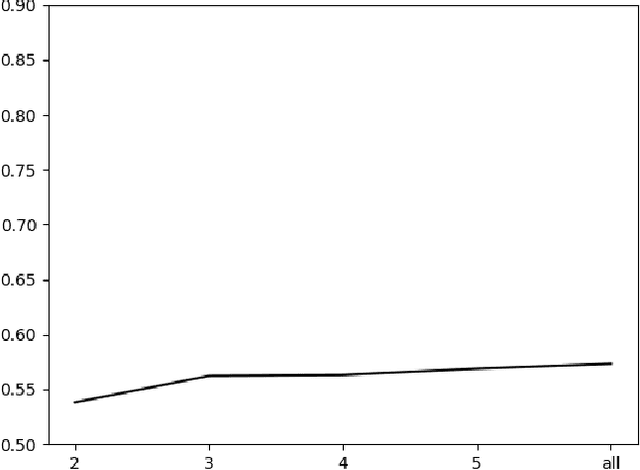
We present experiments on detecting hyperpartisanship in news using a 'masking' method that allows us to assess the role of style vs. content for the task at hand. Our results corroborate previous research on this task in that topic related features yield better results than stylistic ones. We additionally show that competitive results can be achieved by simply including higher-length n-grams, which suggests the need to develop more challenging datasets and tasks that address implicit and more subtle forms of bias.
A Comparative Analysis of Distributional Term Representations for Author Profiling in Social Media
May 21, 2019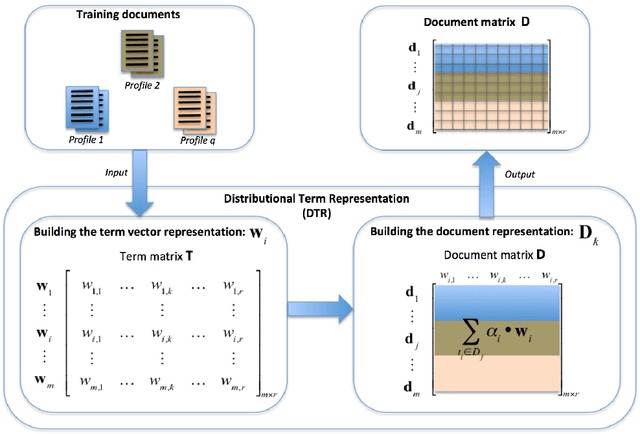
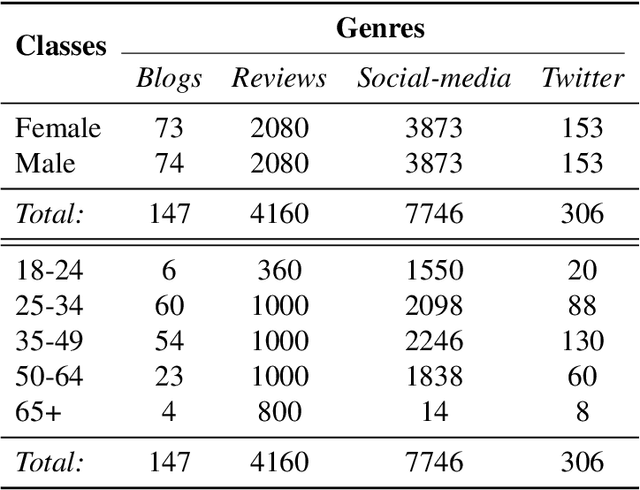
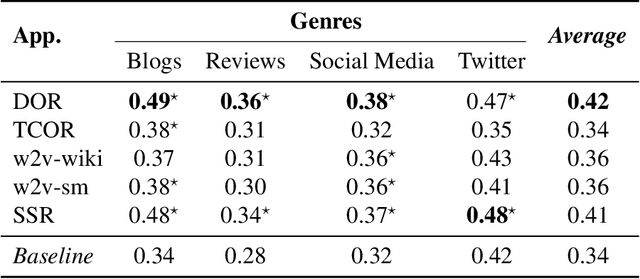
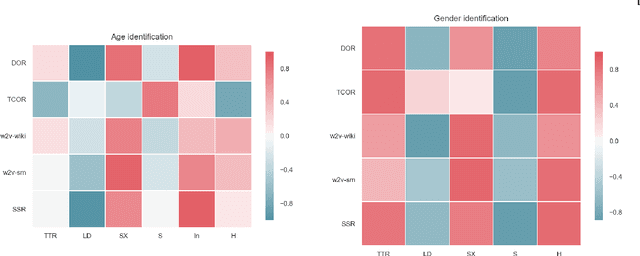
Author Profiling (AP) aims at predicting specific characteristics from a group of authors by analyzing their written documents. Many research has been focused on determining suitable features for modeling writing patterns from authors. Reported results indicate that content-based features continue to be the most relevant and discriminant features for solving this task. Thus, in this paper, we present a thorough analysis regarding the appropriateness of different distributional term representations (DTR) for the AP task. In this regard, we introduce a novel framework for supervised AP using these representations and, supported on it. We approach a comparative analysis of representations such as DOR, TCOR, SSR, and word2vec in the AP problem. We also compare the performance of the DTRs against classic approaches including popular topic-based methods. The obtained results indicate that DTRs are suitable for solving the AP task in social media domains as they achieve competitive results while providing meaningful interpretability.
A Text Classification Framework for Simple and Effective Early Depression Detection Over Social Media Streams
May 18, 2019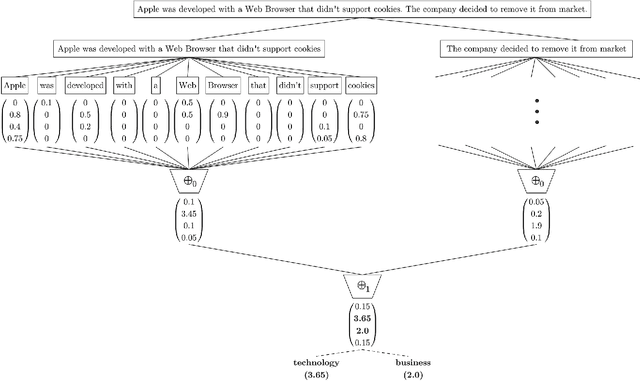
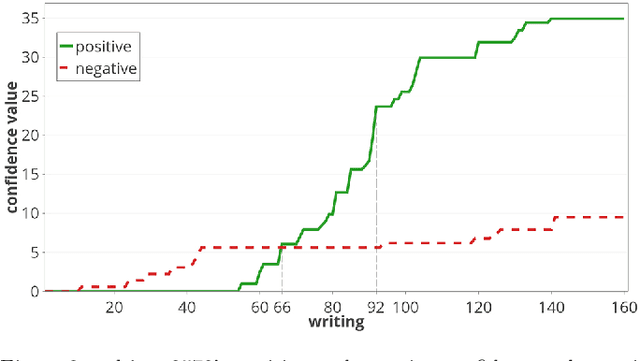
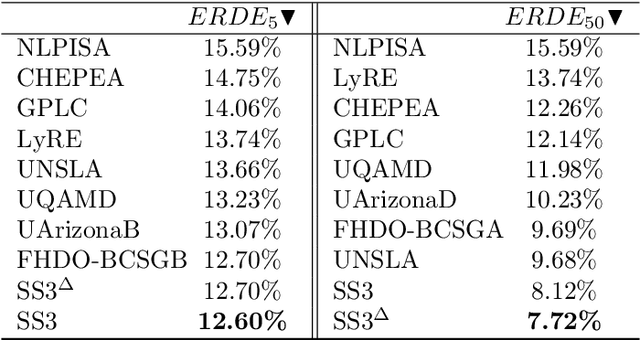
With the rise of the Internet, there is a growing need to build intelligent systems that are capable of efficiently dealing with early risk detection (ERD) problems on social media, such as early depression detection, early rumor detection or identification of sexual predators. These systems, nowadays mostly based on machine learning techniques, must be able to deal with data streams since users provide their data over time. In addition, these systems must be able to decide when the processed data is sufficient to actually classify users. Moreover, since ERD tasks involve risky decisions by which people's lives could be affected, such systems must also be able to justify their decisions. However, most standard and state-of-the-art supervised machine learning models (such as SVM, MNB, Neural Networks, etc.) are not well suited to deal with this scenario. This is due to the fact that they either act as black boxes or do not support incremental classification/learning. In this paper we introduce SS3, a novel supervised learning model for text classification that naturally supports these aspects. SS3 was designed to be used as a general framework to deal with ERD problems. We evaluated our model on the CLEF's eRisk2017 pilot task on early depression detection. Most of the 30 contributions submitted to this competition used state-of-the-art methods. Experimental results show that our classifier was able to outperform these models and standard classifiers, despite being less computationally expensive and having the ability to explain its rationale.
* Highlights: (*) A novel text classifier having the ability to visually explain its rationale; (*) Domain-independent classification that does not require feature engineering; (*) Support for incremental learning and text classification over streams; (*) Efficient framework for addressing early risk detection problems; (*) State-of-the-art performance on early depression detection task
Semantically-informed distance and similarity measures for paraphrase plagiarism identification
May 29, 2018

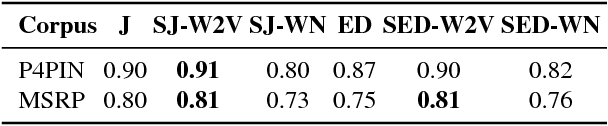
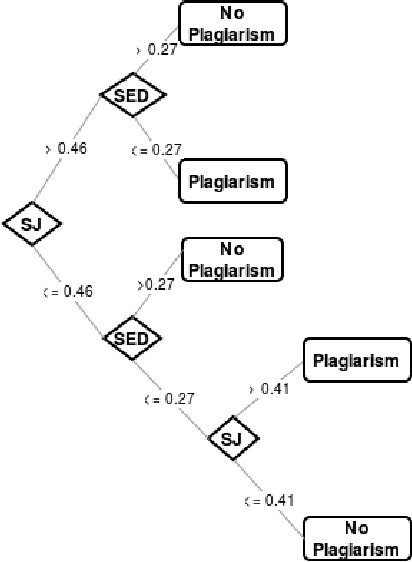
Paraphrase plagiarism identification represents a very complex task given that plagiarized texts are intentionally modified through several rewording techniques. Accordingly, this paper introduces two new measures for evaluating the relatedness of two given texts: a semantically-informed similarity measure and a semantically-informed edit distance. Both measures are able to extract semantic information from either an external resource or a distributed representation of words, resulting in informative features for training a supervised classifier for detecting paraphrase plagiarism. Obtained results indicate that the proposed metrics are consistently good in detecting different types of paraphrase plagiarism. In addition, results are very competitive against state-of-the art methods having the advantage of representing a much more simple but equally effective solution.
A visual approach for age and gender identification on Twitter
May 28, 2018
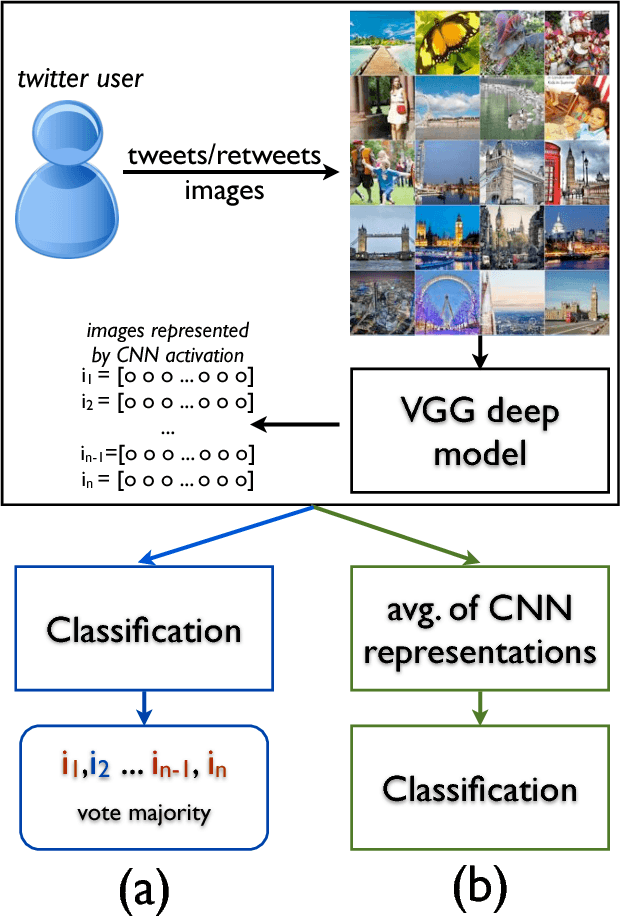
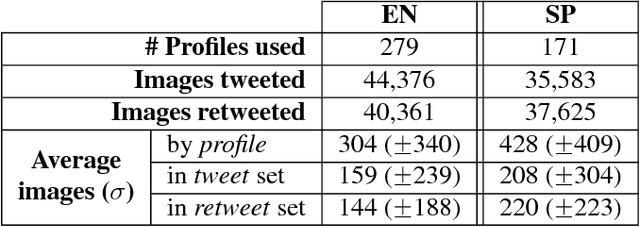

The goal of Author Profiling (AP) is to identify demographic aspects (e.g., age, gender) from a given set of authors by analyzing their written texts. Recently, the AP task has gained interest in many problems related to computer forensics, psychology, marketing, but specially in those related with social media exploitation. As known, social media data is shared through a wide range of modalities (e.g., text, images and audio), representing valuable information to be exploited for extracting valuable insights from users. Nevertheless, most of the current work in AP using social media data has been devoted to analyze textual information only, and there are very few works that have started exploring the gender identification using visual information. Contrastingly, this paper focuses in exploiting the visual modality to perform both age and gender identification in social media, specifically in Twitter. Our goal is to evaluate the pertinence of using visual information in solving the AP task. Accordingly, we have extended the Twitter corpus from PAN 2014, incorporating posted images from all the users, making a distinction between tweeted and retweeted images. Performed experiments provide interesting evidence on the usefulness of visual information in comparison with traditional textual representations for the AP task.
Gated Multimodal Units for Information Fusion
Feb 07, 2017
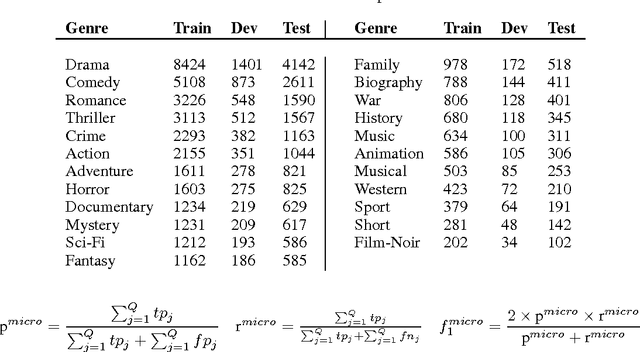
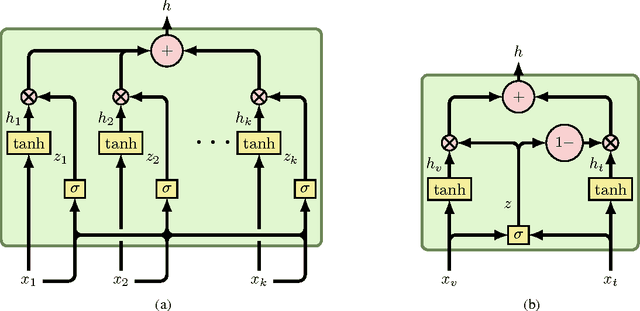
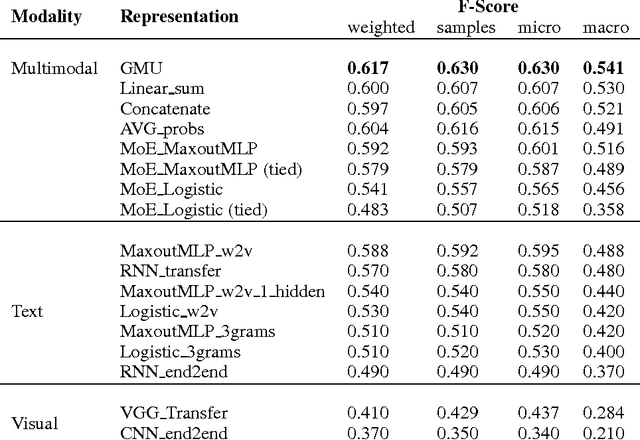
This paper presents a novel model for multimodal learning based on gated neural networks. The Gated Multimodal Unit (GMU) model is intended to be used as an internal unit in a neural network architecture whose purpose is to find an intermediate representation based on a combination of data from different modalities. The GMU learns to decide how modalities influence the activation of the unit using multiplicative gates. It was evaluated on a multilabel scenario for genre classification of movies using the plot and the poster. The GMU improved the macro f-score performance of single-modality approaches and outperformed other fusion strategies, including mixture of experts models. Along with this work, the MM-IMDb dataset is released which, to the best of our knowledge, is the largest publicly available multimodal dataset for genre prediction on movies.
Early text classification: a Naive solution
Sep 20, 2015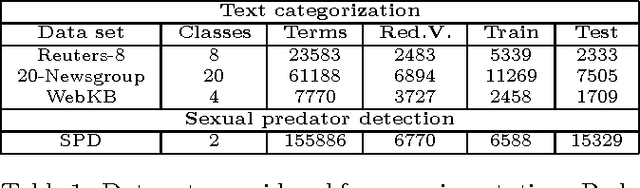
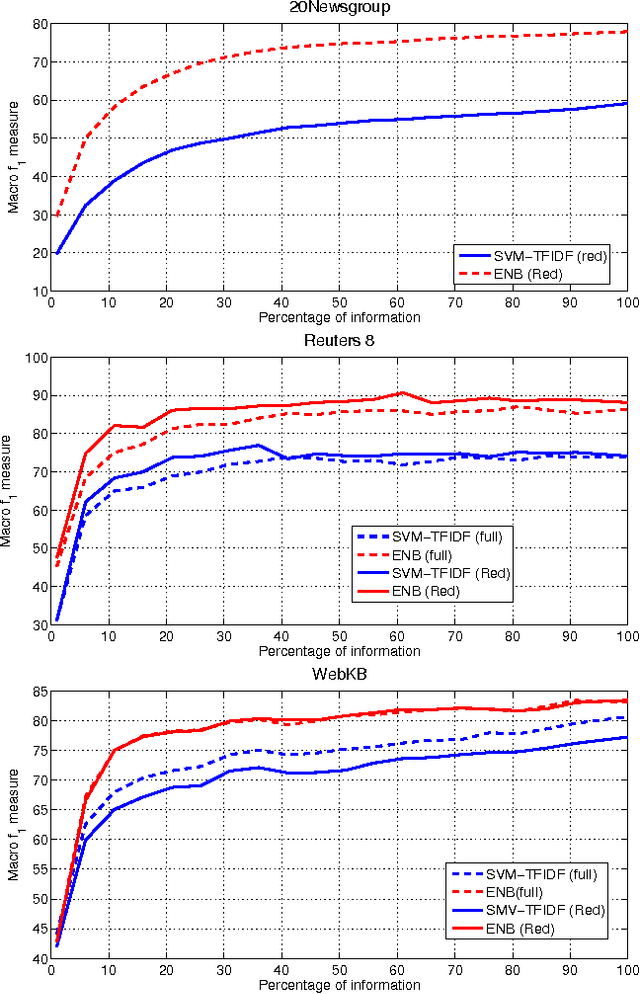
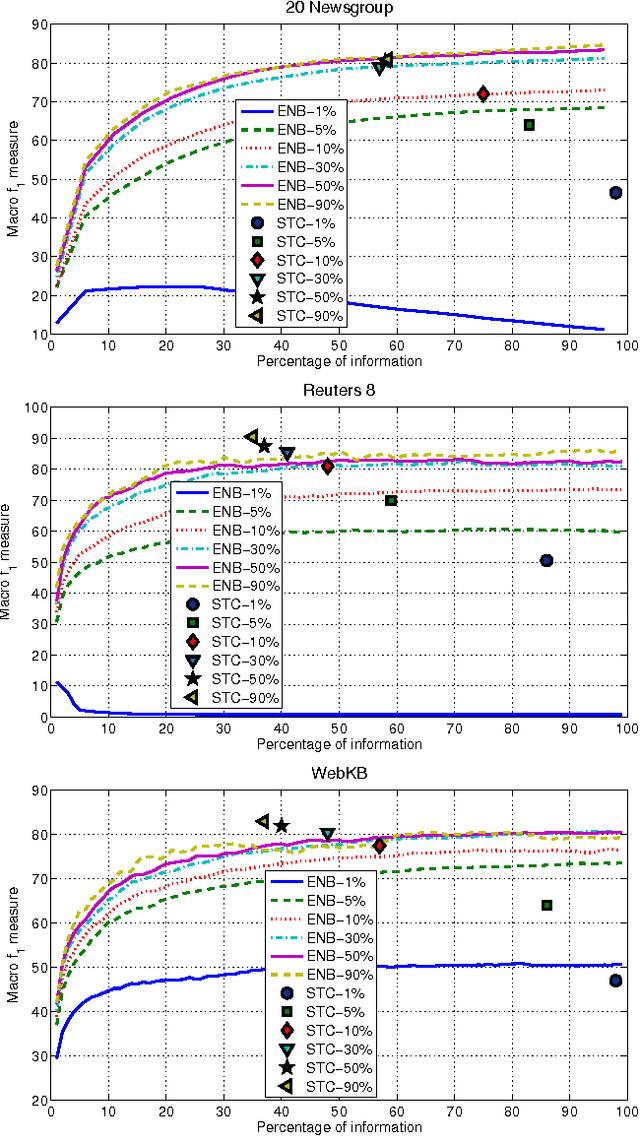
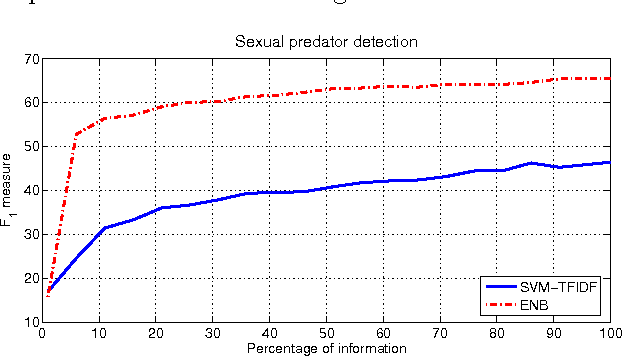
Text classification is a widely studied problem, and it can be considered solved for some domains and under certain circumstances. There are scenarios, however, that have received little or no attention at all, despite its relevance and applicability. One of such scenarios is early text classification, where one needs to know the category of a document by using partial information only. A document is processed as a sequence of terms, and the goal is to devise a method that can make predictions as fast as possible. The importance of this variant of the text classification problem is evident in domains like sexual predator detection, where one wants to identify an offender as early as possible. This paper analyzes the suitability of the standard naive Bayes classifier for approaching this problem. Specifically, we assess its performance when classifying documents after seeing an increasingly number of terms. A simple modification to the standard naive Bayes implementation allows us to make predictions with partial information. To the best of our knowledge naive Bayes has not been used for this purpose before. Throughout an extensive experimental evaluation we show the effectiveness of the classifier for early text classification. What is more, we show that this simple solution is very competitive when compared with state of the art methodologies that are more elaborated. We foresee our work will pave the way for the development of more effective early text classification techniques based in the naive Bayes formulation.