 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Epidemic Forecasting and Community Risk Evaluation of COVID-19
Jun 03, 2021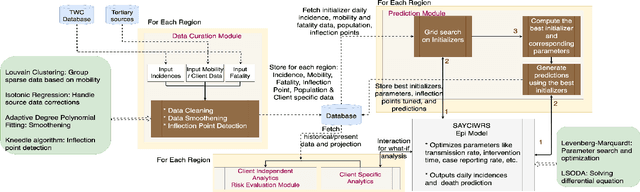
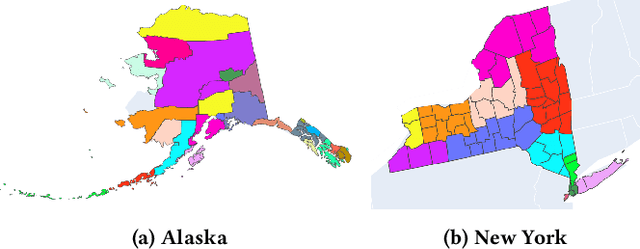
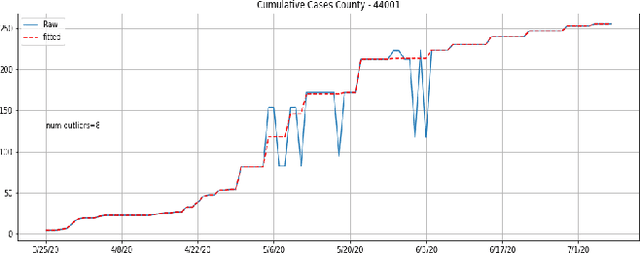
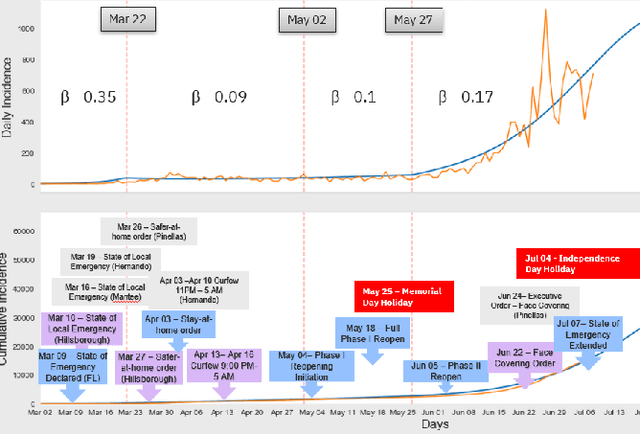
Pandemic control measures like lock-down, restrictions on restaurants and gatherings, social-distancing have shown to be effective in curtailing the spread of COVID-19. However, their sustained enforcement has negative economic effects. To craft strategies and policies that reduce the hardship on the people and the economy while being effective against the pandemic, authorities need to understand the disease dynamics at the right geo-spatial granularity. Considering factors like the hospitals' ability to handle the fluctuating demands, evaluating various reopening scenarios, and accurate forecasting of cases are vital to decision making. Towards this end, we present a flexible end-to-end solution that seamlessly integrates public health data with tertiary client data to accurately estimate the risk of reopening a community. At its core lies a state-of-the-art prediction model that auto-captures changing trends in transmission and mobility. Benchmarking against various published baselines confirm the superiority of our forecasting algorithm. Combined with the ability to extend to multiple client-specific requirements and perform deductive reasoning through counter-factual analysis, this solution provides actionable insights to multiple client domains ranging from government to educational institutions, hospitals, and commercial establishments.
Illumination Estimation Challenge: experience of past two years
Dec 31, 2020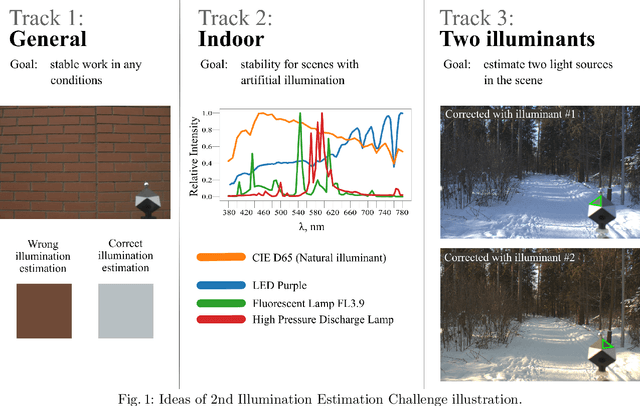
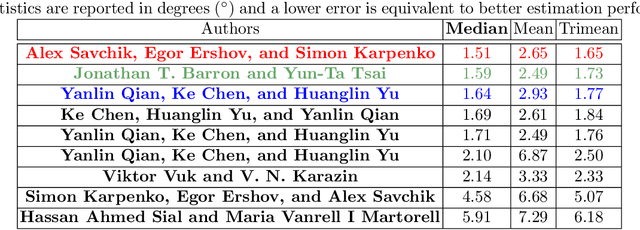

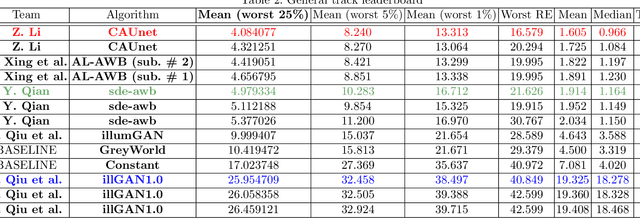
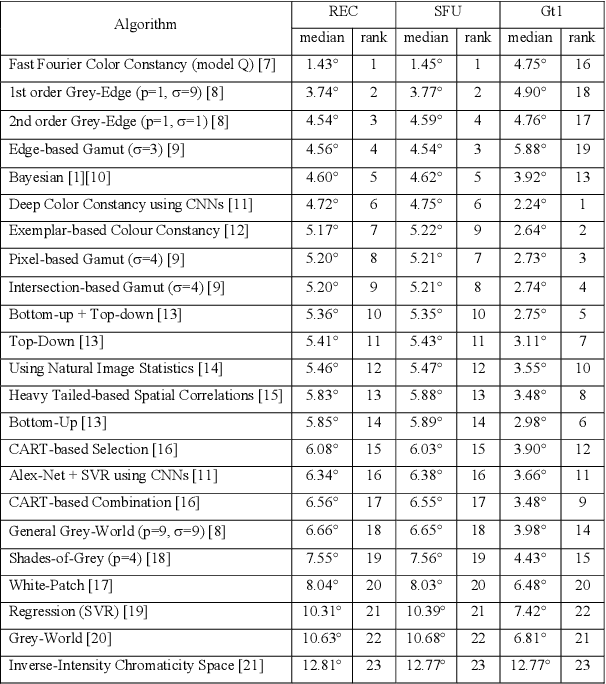
Illumination estimation is the essential step of computational color constancy, one of the core parts of various image processing pipelines of modern digital cameras. Having an accurate and reliable illumination estimation is important for reducing the illumination influence on the image colors. To motivate the generation of new ideas and the development of new algorithms in this field, the 2nd Illumination estimation challenge~(IEC\#2) was conducted. The main advantage of testing a method on a challenge over testing in on some of the known datasets is the fact that the ground-truth illuminations for the challenge test images are unknown up until the results have been submitted, which prevents any potential hyperparameter tuning that may be biased. The challenge had several tracks: general, indoor, and two-illuminant with each of them focusing on different parameters of the scenes. Other main features of it are a new large dataset of images (about 5000) taken with the same camera sensor model, a manual markup accompanying each image, diverse content with scenes taken in numerous countries under a huge variety of illuminations extracted by using the SpyderCube calibration object, and a contest-like markup for the images from the Cube+ dataset that was used in IEC\#1. This paper focuses on the description of the past two challenges, algorithms which won in each track, and the conclusions that were drawn based on the results obtained during the 1st and 2nd challenge that can be useful for similar future developments.
Disentangling Image Distortions in Deep Feature Space
Feb 26, 2020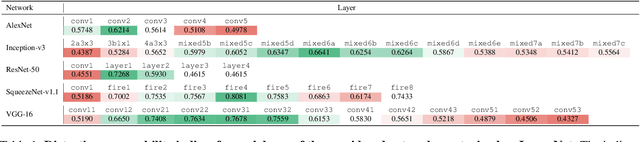

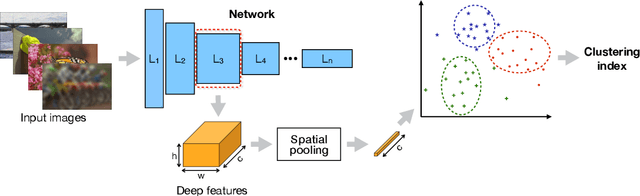
Previous literature suggests that perceptual similarity is an emergent property shared across deep visual representations. Experiments conducted on a dataset of human-judged image distortions have proven that deep features outperform, by a large margin, classic perceptual metrics. In this work we take a further step in the direction of a broader understanding of such property by analyzing the capability of deep visual representations to intrinsically characterize different types of image distortions. To this end, we firstly generate a number of synthetically distorted images by applying three mainstream distortion types to the LIVE database and then we analyze the features extracted by different layers of different Deep Network architectures. We observe that a dimension-reduced representation of the features extracted from a given layer permits to efficiently separate types of distortions in the feature space. Moreover, each network layer exhibits a different ability to separate between different types of distortions, and this ability varies according to the network architecture. As a further analysis, we evaluate the exploitation of features taken from the layer that better separates image distortions for: i) reduced-reference image quality assessment, and ii) distortion types and severity levels characterization on both single and multiple distortion databases. Results achieved on both tasks suggest that deep visual representations can be unsupervisedly employed to efficiently characterize various image distortions.
Deep Residual Autoencoder for quality independent JPEG restoration
Mar 14, 2019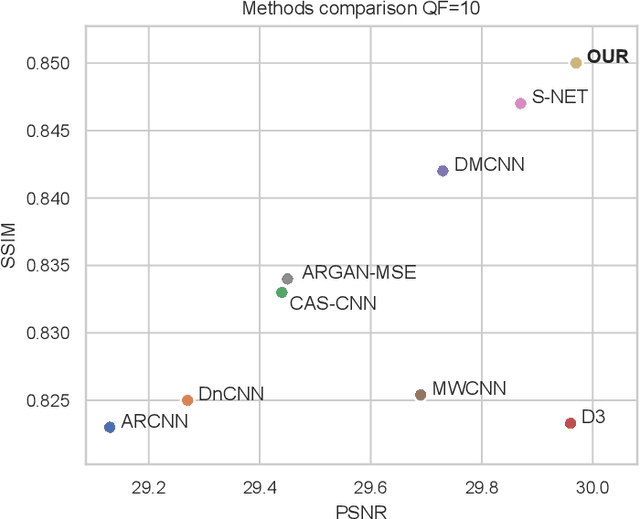
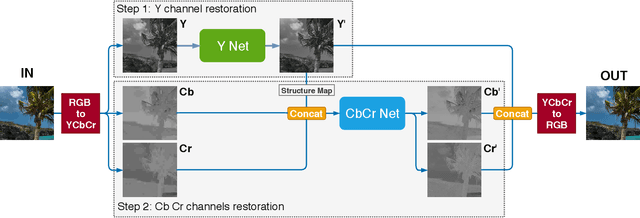

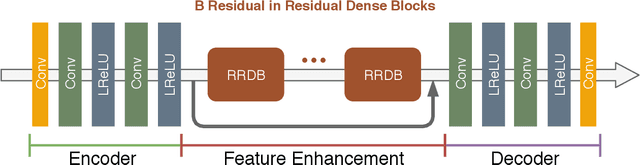
In this paper we propose a deep residual autoencoder exploiting Residual-in-Residual Dense Blocks (RRDB) to remove artifacts in JPEG compressed images that is independent from the Quality Factor (QF) used. The proposed approach leverages both the learning capacity of deep residual networks and prior knowledge of the JPEG compression pipeline. The proposed model operates in the YCbCr color space and performs JPEG artifact restoration in two phases using two different autoencoders: the first one restores the luma channel exploiting 2D convolutions; the second one, using the restored luma channel as a guide, restores the chroma channels explotining 3D convolutions. Extensive experimental results on three widely used benchmark datasets (i.e. LIVE1, BDS500, and CLASSIC-5) show that our model is able to outperform the state of the art with respect to all the evaluation metrics considered (i.e. PSNR, PSNR-B, and SSIM). This results is remarkable since the approaches in the state of the art use a different set of weights for each compression quality, while the proposed model uses the same weights for all of them, making it applicable to images in the wild where the QF used for compression is unkwnown. Furthermore, the proposed model shows a greater robustness than state-of-the-art methods when applied to compression qualities not seen during training.
Multitask Painting Categorization by Deep Multibranch Neural Network
Dec 19, 2018
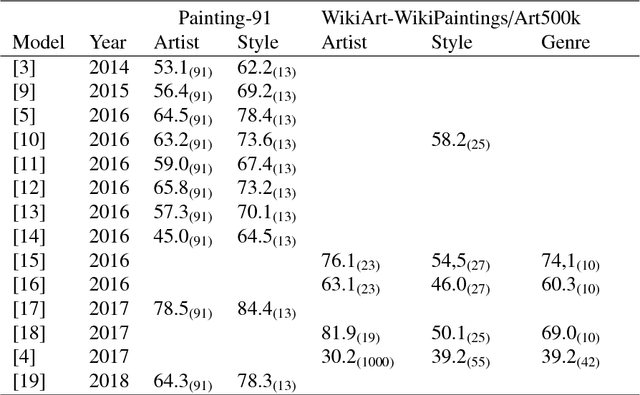
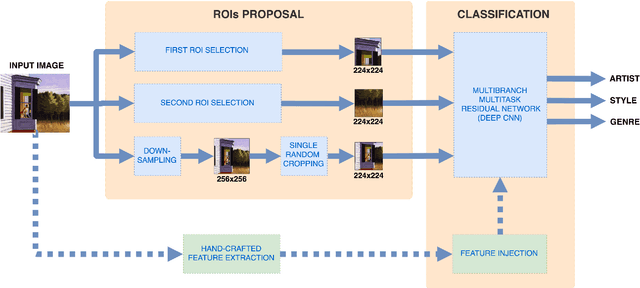
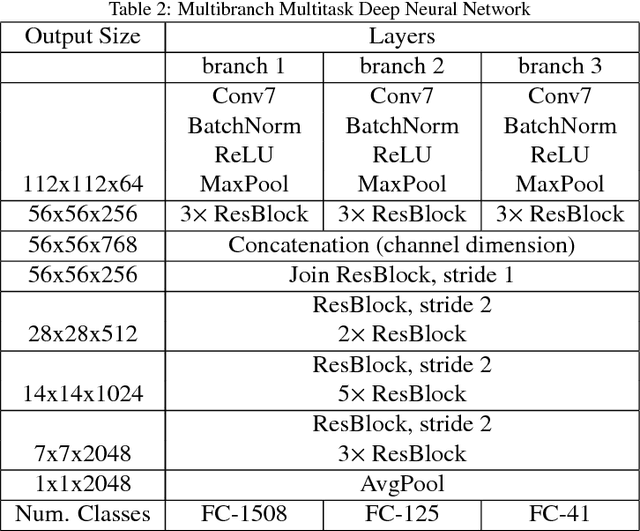
In this work we propose a new deep multibranch neural network to solve the tasks of artist, style, and genre categorization in a multitask formulation. In order to gather clues from low-level texture details and, at the same time, exploit the coarse layout of the painting, the branches of the proposed networks are fed with crops at different resolutions. We propose and compare two different crop strategies: the first one is a random-crop strategy that permits to manage the tradeoff between accuracy and speed; the second one is a smart extractor based on Spatial Transformer Networks trained to extract the most representative subregions. Furthermore, inspired by the results obtained in other domains, we experiment the joint use of hand-crafted features directly computed on the input images along with neural ones. Experiments are performed on a new dataset originally sourced from wikiart.org and hosted by Kaggle, and made suitable for artist, style and genre multitask learning. The dataset here proposed, named MultitaskPainting100k, is composed by 100K paintings, 1508 artists, 125 styles and 41 genres. Our best method, tested on the MultitaskPainting100k dataset, achieves accuracy levels of 56.5%, 57.2%, and 63.6% on the tasks of artist, style and genre prediction respectively.
Benchmark Analysis of Representative Deep Neural Network Architectures
Oct 19, 2018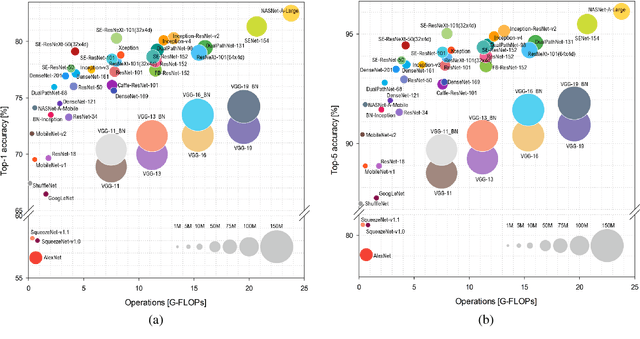
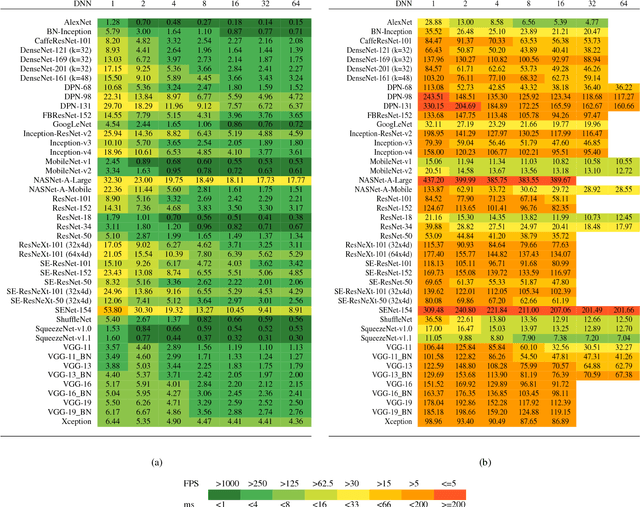
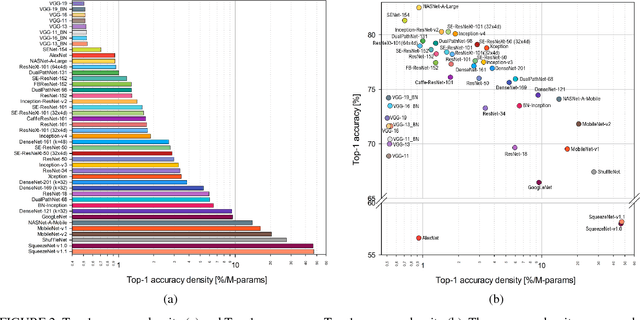

This work presents an in-depth analysis of the majority of the deep neural networks (DNNs) proposed in the state of the art for image recognition. For each DNN multiple performance indices are observed, such as recognition accuracy, model complexity, computational complexity, memory usage, and inference time. The behavior of such performance indices and some combinations of them are analyzed and discussed. To measure the indices we experiment the use of DNNs on two different computer architectures, a workstation equipped with a NVIDIA Titan X Pascal and an embedded system based on a NVIDIA Jetson TX1 board. This experimentation allows a direct comparison between DNNs running on machines with very different computational capacity. This study is useful for researchers to have a complete view of what solutions have been explored so far and in which research directions are worth exploring in the future; and for practitioners to select the DNN architecture(s) that better fit the resource constraints of practical deployments and applications. To complete this work, all the DNNs, as well as the software used for the analysis, are available online.
Rehabilitating the ColorChecker Dataset for Illuminant Estimation
Sep 17, 2018
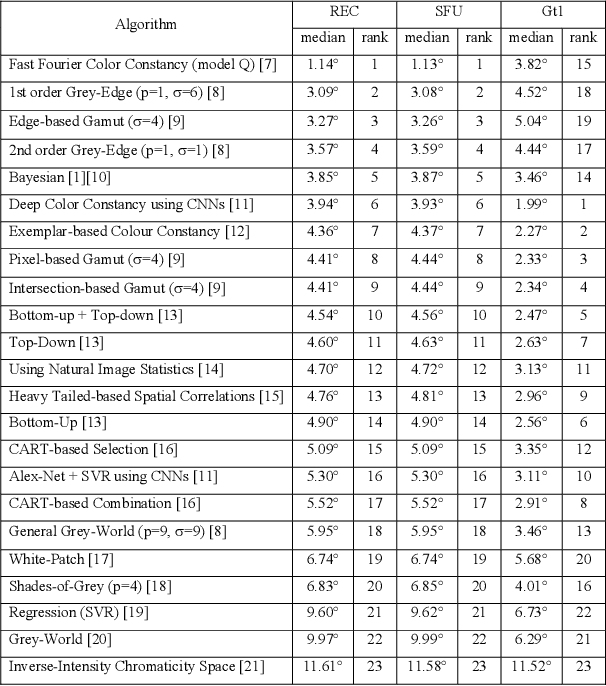
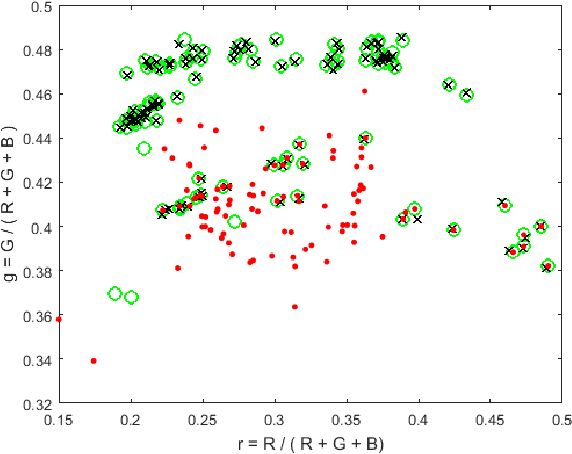
In a previous work, it was shown that there is a curious problem with the benchmark ColorChecker dataset for illuminant estimation. To wit, this dataset has at least 3 different sets of ground-truths. Typically, for a single algorithm a single ground-truth is used. But then different algorithms, whose performance is measured with respect to different ground-truths, are compared against each other and then ranked. This makes no sense. We show in this paper that there are also errors in how each ground-truth set was calculated. As a result, all performance rankings based on the ColorChecker dataset - and there are scores of these - are inaccurate. In this paper, we re-generate a new 'recommended' set of ground-truth based on the calculation methodology described by Shi and Funt. We then review the performance evaluation of a range of illuminant estimation algorithms. Compared with the legacy ground-truths, we find that the difference in how algorithms perform can be large, with many local rankings of algorithms being reversed. Finally, we draw the readers attention to our new 'open' data repository which, we hope, will allow the ColorChecker set to be rehabilitated and once again to become a useful benchmark for illuminant estimation algorithms.
Aesthetics Assessment of Images Containing Faces
May 22, 2018
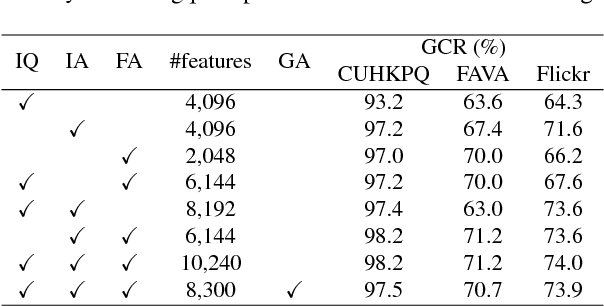
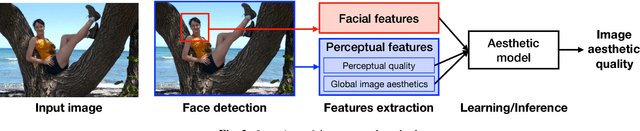
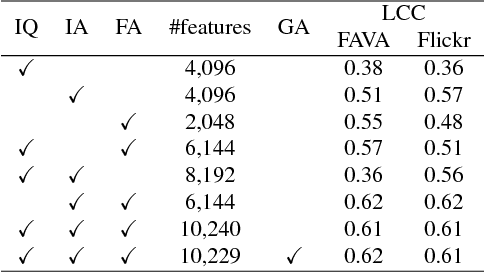
Recent research has widely explored the problem of aesthetics assessment of images with generic content. However, few approaches have been specifically designed to predict the aesthetic quality of images containing human faces, which make up a massive portion of photos in the web. This paper introduces a method for aesthetic quality assessment of images with faces. We exploit three different Convolutional Neural Networks to encode information regarding perceptual quality, global image aesthetics, and facial attributes; then, a model is trained to combine these features to explicitly predict the aesthetics of images containing faces. Experimental results show that our approach outperforms existing methods for both binary, i.e. low/high, and continuous aesthetic score prediction on four different databases in the state-of-the-art.
How Far Can You Get By Combining Change Detection Algorithms?
Apr 04, 2018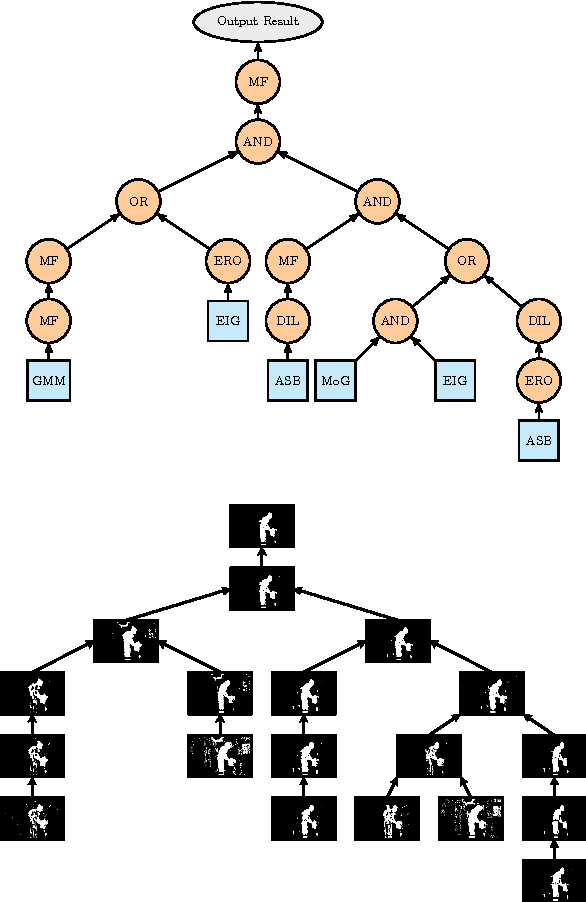
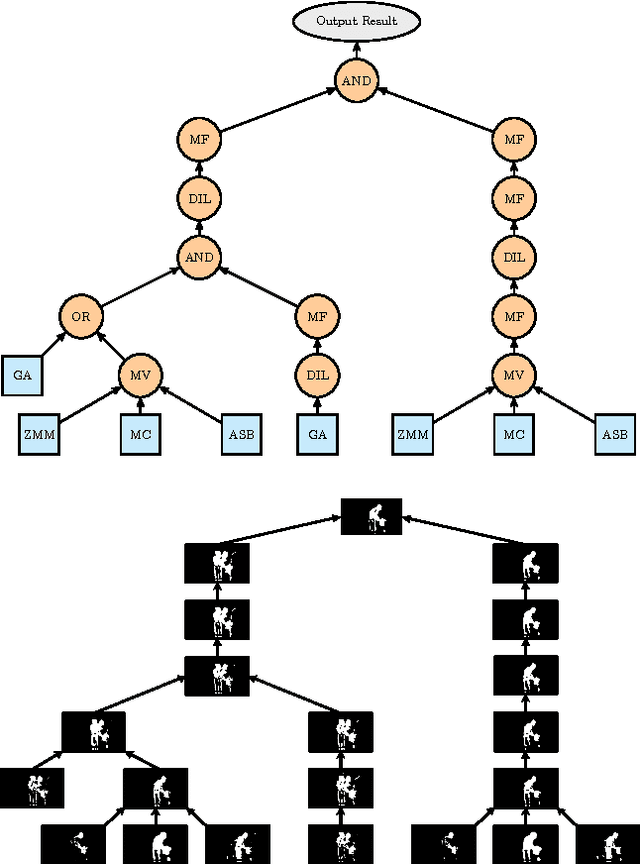
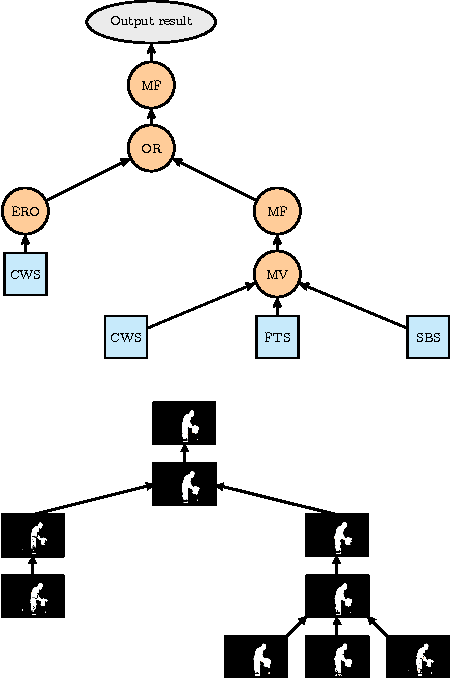

Given the existence of many change detection algorithms, each with its own peculiarities and strengths, we propose a combination strategy, that we termed IUTIS (In Unity There Is Strength), based on a genetic Programming framework. This combination strategy is aimed at leveraging the strengths of the algorithms and compensate for their weakness. In this paper we show our findings in applying the proposed strategy in two different scenarios. The first scenario is purely performance-based. The second scenario performance and efficiency must be balanced. Results demonstrate that starting from simple algorithms we can achieve comparable results with respect to more complex state-of-the-art change detection algorithms, while keeping the computational complexity affordable for real-time applications.
Automated Pruning for Deep Neural Network Compression
Dec 05, 2017
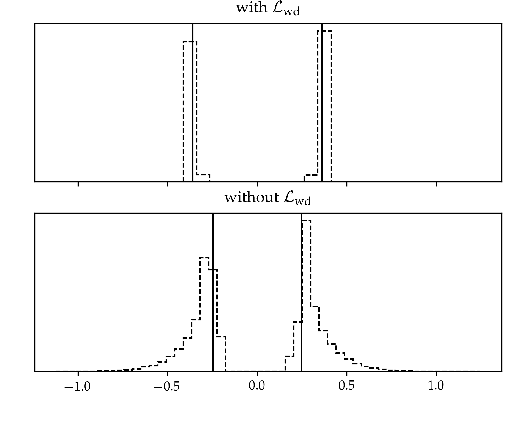
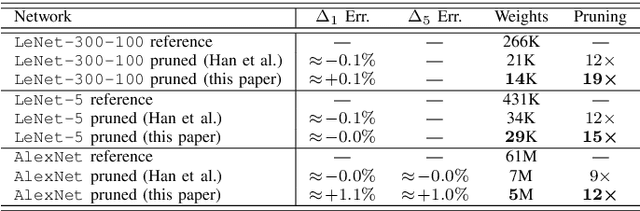
In this work we present a method to improve the pruning step of the current state-of-the-art methodology to compress neural networks. The novelty of the proposed pruning technique is in its differentiability, which allows pruning to be performed during the backpropagation phase of the network training. This enables an end-to-end learning and strongly reduces the training time. The technique is based on a family of differentiable pruning functions and a new regularizer specifically designed to enforce pruning. The experimental results show that the joint optimization of both the thresholds and the network weights permits to reach a higher compression rate, reducing the number of weights of the pruned network by a further 14% to 33% with respect to the current state-of-the-art. Furthermore, we believe that this is the first study where the generalization capabilities in transfer learning tasks of the features extracted by a pruned network are analyzed. To achieve this goal, we show that the representations learned using the proposed pruning methodology maintain the same effectiveness and generality of those learned by the corresponding non-compressed network on a set of different recognition tasks.