 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKickstarting Deep Reinforcement Learning
Mar 10, 2018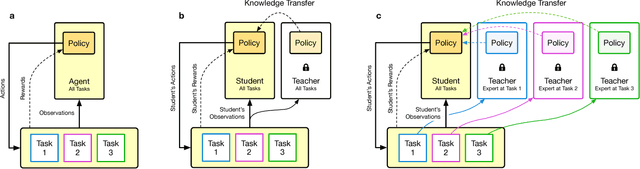
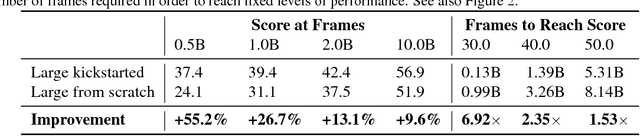
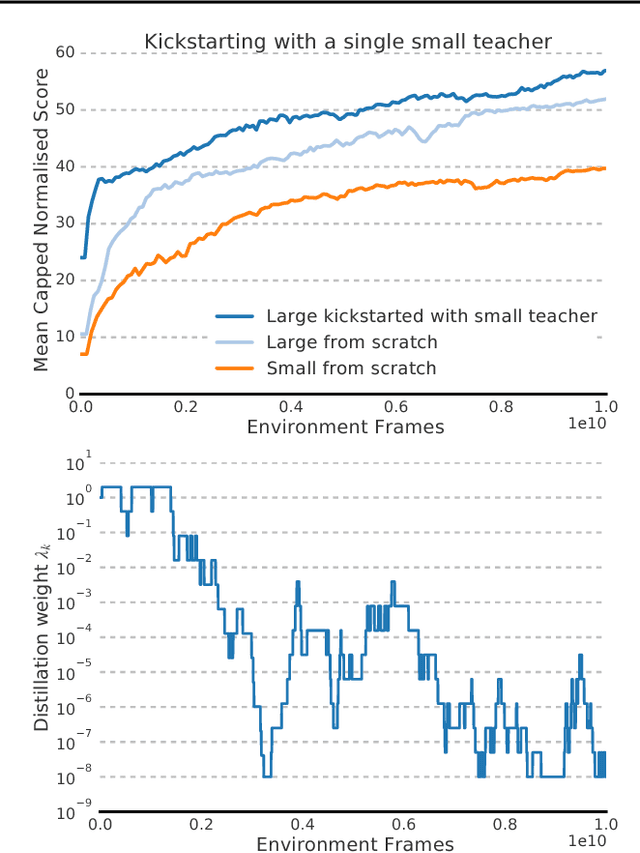
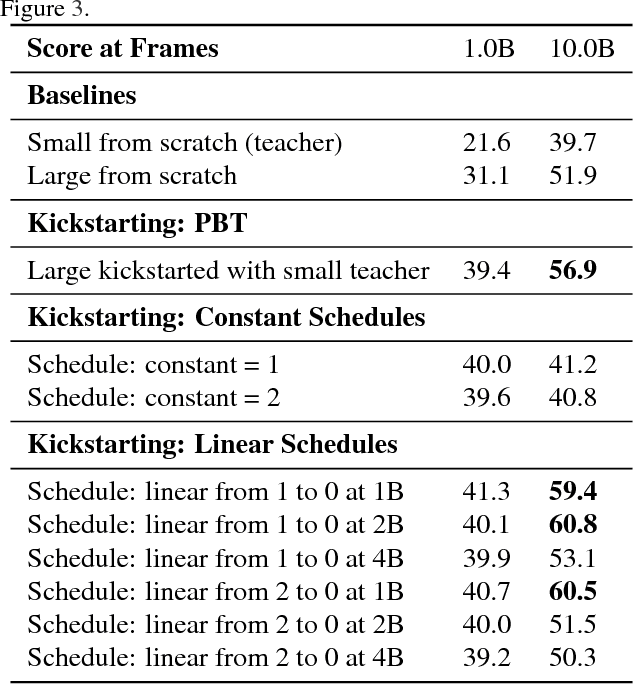
We present a method for using previously-trained 'teacher' agents to kickstart the training of a new 'student' agent. To this end, we leverage ideas from policy distillation and population based training. Our method places no constraints on the architecture of the teacher or student agents, and it regulates itself to allow the students to surpass their teachers in performance. We show that, on a challenging and computationally-intensive multi-task benchmark (DMLab-30), kickstarted training improves the data efficiency of new agents, making it significantly easier to iterate on their design. We also show that the same kickstarting pipeline can allow a single student agent to leverage multiple 'expert' teachers which specialize on individual tasks. In this setting kickstarting yields surprisingly large gains, with the kickstarted agent matching the performance of an agent trained from scratch in almost 10x fewer steps, and surpassing its final performance by 42 percent. Kickstarting is conceptually simple and can easily be incorporated into reinforcement learning experiments.