 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScattering Networks for Hybrid Representation Learning
Sep 17, 2018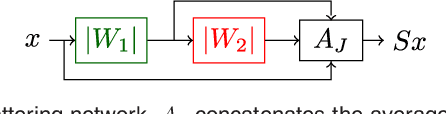
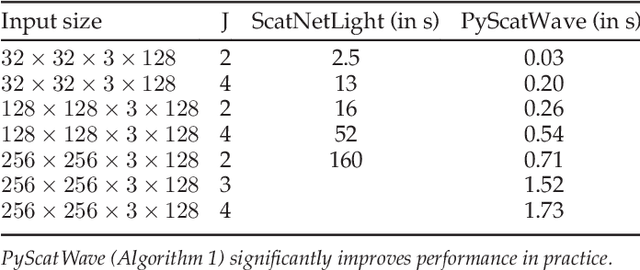
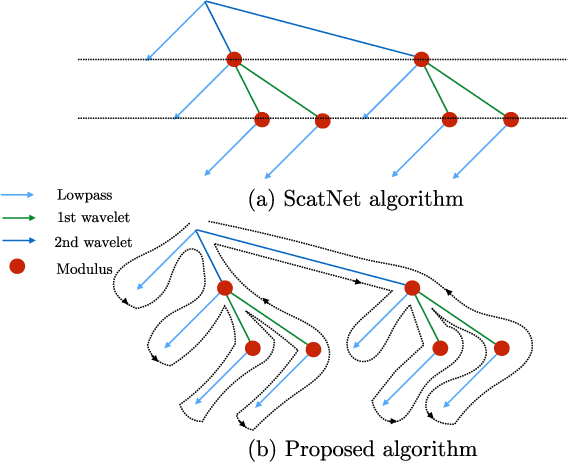
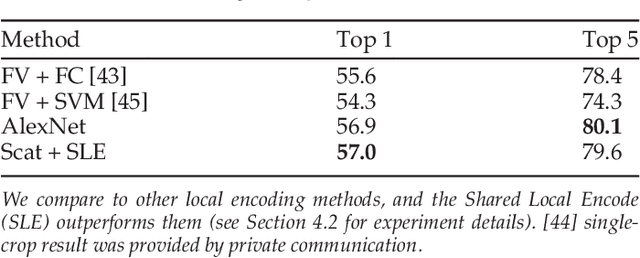
Scattering networks are a class of designed Convolutional Neural Networks (CNNs) with fixed weights. We argue they can serve as generic representations for modelling images. In particular, by working in scattering space, we achieve competitive results both for supervised and unsupervised learning tasks, while making progress towards constructing more interpretable CNNs. For supervised learning, we demonstrate that the early layers of CNNs do not necessarily need to be learned, and can be replaced with a scattering network instead. Indeed, using hybrid architectures, we achieve the best results with predefined representations to-date, while being competitive with end-to-end learned CNNs. Specifically, even applying a shallow cascade of small-windowed scattering coefficients followed by 1$\times$1-convolutions results in AlexNet accuracy on the ILSVRC2012 classification task. Moreover, by combining scattering networks with deep residual networks, we achieve a single-crop top-5 error of 11.4% on ILSVRC2012. Also, we show they can yield excellent performance in the small sample regime on CIFAR-10 and STL-10 datasets, exceeding their end-to-end counterparts, through their ability to incorporate geometrical priors. For unsupervised learning, scattering coefficients can be a competitive representation that permits image recovery. We use this fact to train hybrid GANs to generate images. Finally, we empirically analyze several properties related to stability and reconstruction of images from scattering coefficients.
* arXiv admin note: substantial text overlap with arXiv:1703.08961
Predicting Solution Summaries to Integer Linear Programs under Imperfect Information with Machine Learning
Sep 12, 2018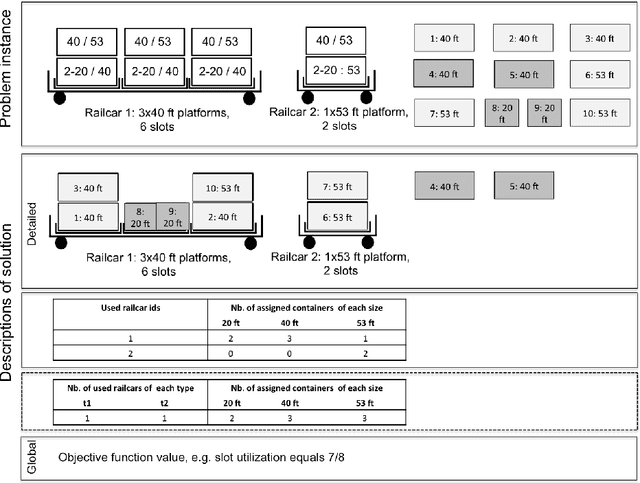
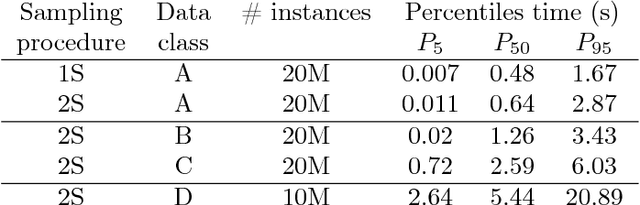
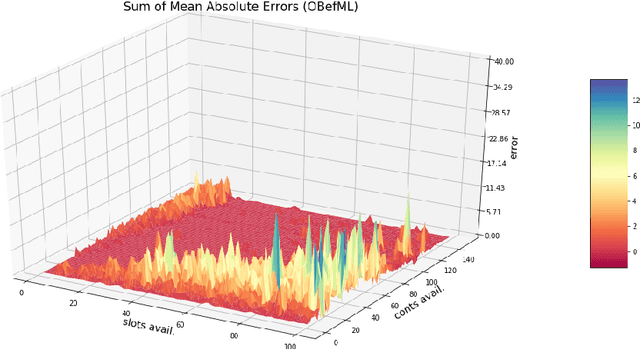
The paper provides a methodological contribution at the intersection of machine learning and operations research. Namely, we propose a methodology to quickly predict solution summaries (i.e., solution descriptions at a given level of detail) to discrete stochastic optimization problems. We approximate the solutions based on supervised learning and the training dataset consists of a large number of deterministic problems that have been solved independently and offline. Uncertainty regarding a missing subset of the inputs is addressed through sampling and aggregation methods. Our motivating application concerns booking decisions of intermodal containers on double-stack trains. Under perfect information, this is the so-called load planning problem and it can be formulated by means of integer linear programming. However, the formulation cannot be used for the application at hand because of the restricted computational budget and unknown container weights. The results show that standard deep learning algorithms allow one to predict descriptions of solutions with high accuracy in very short time (milliseconds or less).
Negative Momentum for Improved Game Dynamics
Jul 12, 2018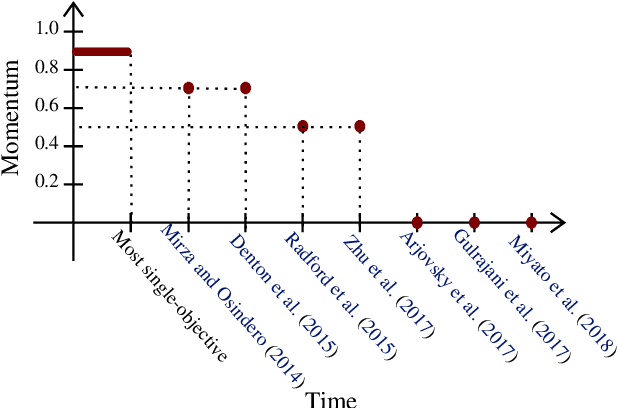

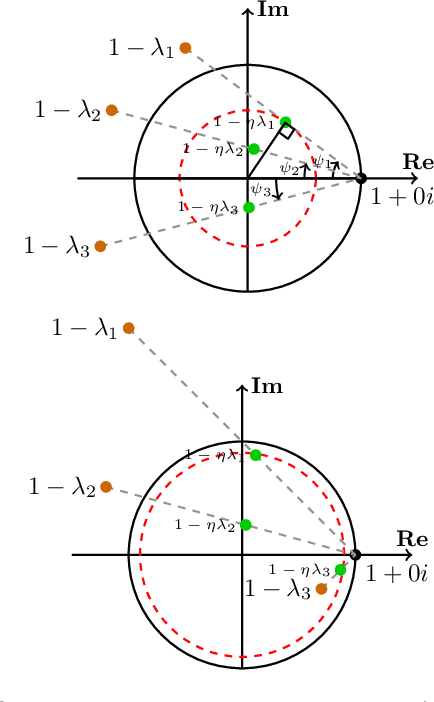
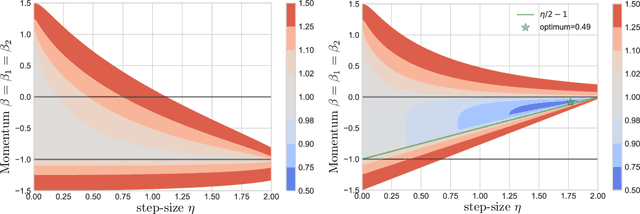
Games generalize the optimization paradigm by introducing different objective functions for different optimizing agents, known as players. Generative Adversarial Networks (GANs) are arguably the most popular game formulation in recent machine learning literature. GANs achieve great results on generating realistic natural images, however they are known for being difficult to train. Training them involves finding a Nash equilibrium, typically performed using gradient descent on the two players' objectives. Game dynamics can induce rotations that slow down convergence to a Nash equilibrium, or prevent it altogether. We provide a theoretical analysis of the game dynamics. Our analysis, supported by experiments, shows that gradient descent with a negative momentum term can improve the convergence properties of some GANs.
Adaptive Stochastic Dual Coordinate Ascent for Conditional Random Fields
Jul 10, 2018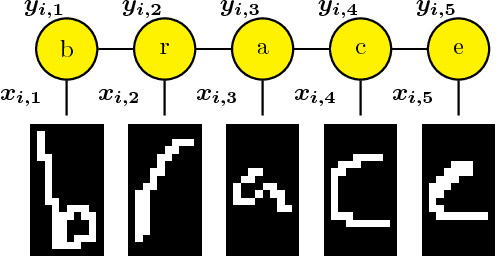
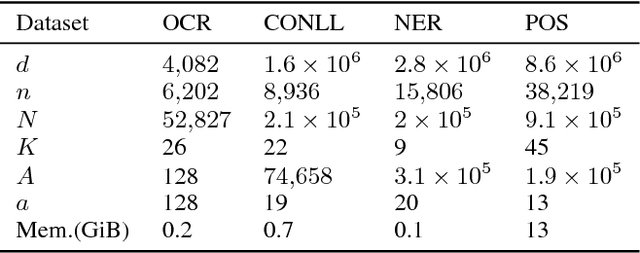
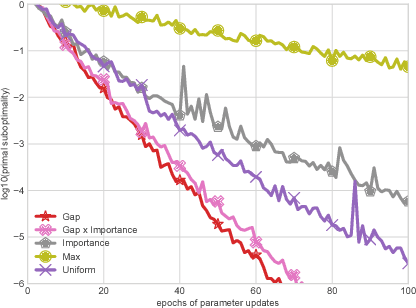
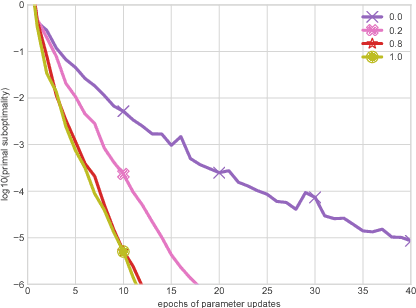
This work investigates the training of conditional random fields (CRFs) via the stochastic dual coordinate ascent (SDCA) algorithm of Shalev-Shwartz and Zhang (2016). SDCA enjoys a linear convergence rate and a strong empirical performance for binary classification problems. However, it has never been used to train CRFs. Yet it benefits from an `exact' line search with a single marginalization oracle call, unlike previous approaches. In this paper, we adapt SDCA to train CRFs, and we enhance it with an adaptive non-uniform sampling strategy based on block duality gaps. We perform experiments on four standard sequence prediction tasks. SDCA demonstrates performances on par with the state of the art, and improves over it on three of the four datasets, which have in common the use of sparse features.
Parametric Adversarial Divergences are Good Task Losses for Generative Modeling
Jun 27, 2018
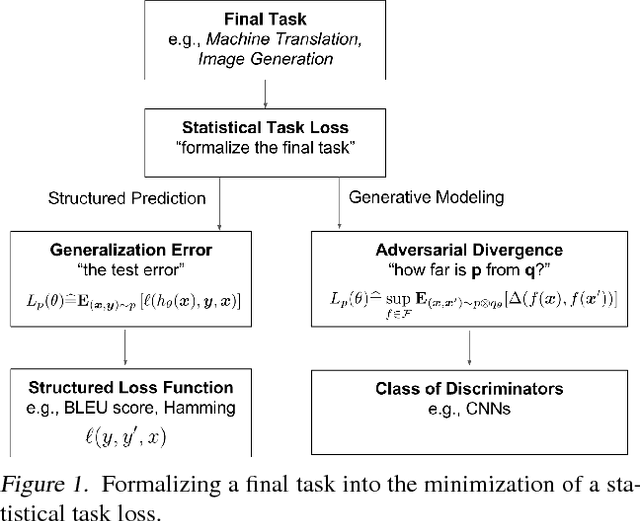

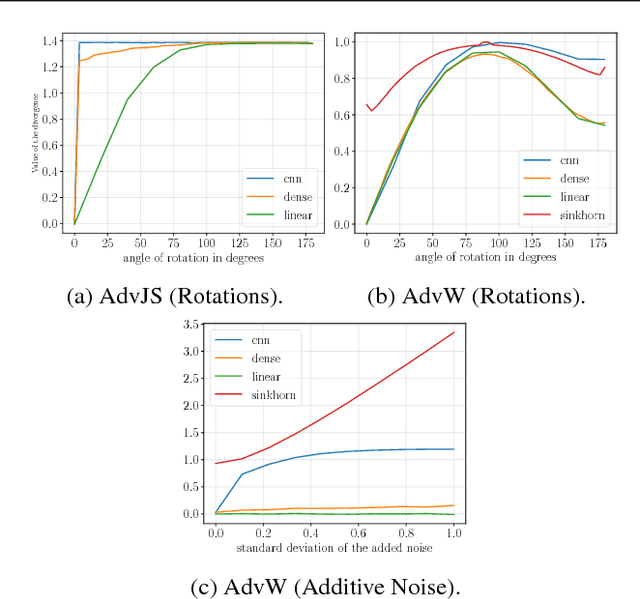
Generative modeling of high dimensional data like images is a notoriously difficult and ill-defined problem. In particular, how to evaluate a learned generative model is unclear. In this position paper, we argue that adversarial learning, pioneered with generative adversarial networks (GANs), provides an interesting framework to implicitly define more meaningful task losses for generative modeling tasks, such as for generating "visually realistic" images. We refer to those task losses as parametric adversarial divergences and we give two main reasons why we think parametric divergences are good learning objectives for generative modeling. Additionally, we unify the processes of choosing a good structured loss (in structured prediction) and choosing a discriminator architecture (in generative modeling) using statistical decision theory; we are then able to formalize and quantify the intuition that "weaker" losses are easier to learn from, in a specific setting. Finally, we propose two new challenging tasks to evaluate parametric and nonparametric divergences: a qualitative task of generating very high-resolution digits, and a quantitative task of learning data that satisfies high-level algebraic constraints. We use two common divergences to train a generator and show that the parametric divergence outperforms the nonparametric divergence on both the qualitative and the quantitative task.
Frank-Wolfe Splitting via Augmented Lagrangian Method
Apr 09, 2018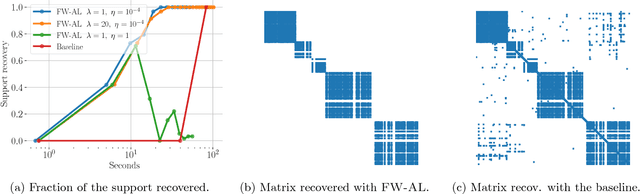
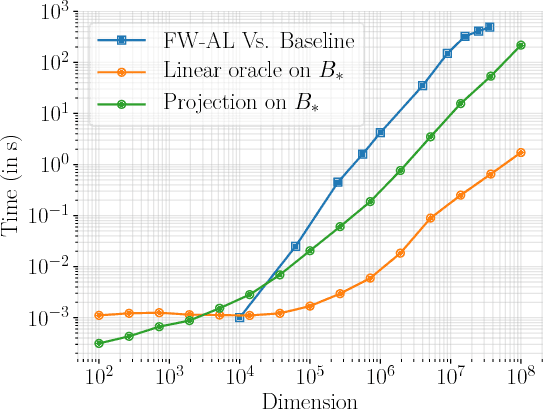
Minimizing a function over an intersection of convex sets is an important task in optimization that is often much more challenging than minimizing it over each individual constraint set. While traditional methods such as Frank-Wolfe (FW) or proximal gradient descent assume access to a linear or quadratic oracle on the intersection, splitting techniques take advantage of the structure of each sets, and only require access to the oracle on the individual constraints. In this work, we develop and analyze the Frank-Wolfe Augmented Lagrangian (FW-AL) algorithm, a method for minimizing a smooth function over convex compact sets related by a "linear consistency" constraint that only requires access to a linear minimization oracle over the individual constraints. It is based on the Augmented Lagrangian Method (ALM), also known as Method of Multipliers, but unlike most existing splitting methods, it only requires access to linear (instead of quadratic) minimization oracles. We use recent advances in the analysis of Frank-Wolfe and the alternating direction method of multipliers algorithms to prove a sublinear convergence rate for FW-AL over general convex compact sets and a linear convergence rate for polytopes.
SEARNN: Training RNNs with Global-Local Losses
Mar 04, 2018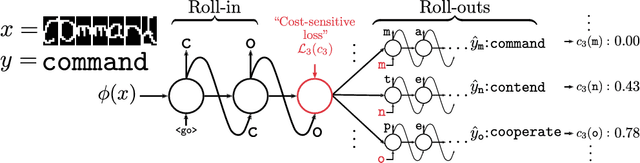
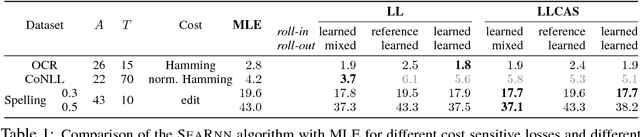

We propose SEARNN, a novel training algorithm for recurrent neural networks (RNNs) inspired by the "learning to search" (L2S) approach to structured prediction. RNNs have been widely successful in structured prediction applications such as machine translation or parsing, and are commonly trained using maximum likelihood estimation (MLE). Unfortunately, this training loss is not always an appropriate surrogate for the test error: by only maximizing the ground truth probability, it fails to exploit the wealth of information offered by structured losses. Further, it introduces discrepancies between training and predicting (such as exposure bias) that may hurt test performance. Instead, SEARNN leverages test-alike search space exploration to introduce global-local losses that are closer to the test error. We first demonstrate improved performance over MLE on two different tasks: OCR and spelling correction. Then, we propose a subsampling strategy to enable SEARNN to scale to large vocabulary sizes. This allows us to validate the benefits of our approach on a machine translation task.
On Structured Prediction Theory with Calibrated Convex Surrogate Losses
Jan 29, 2018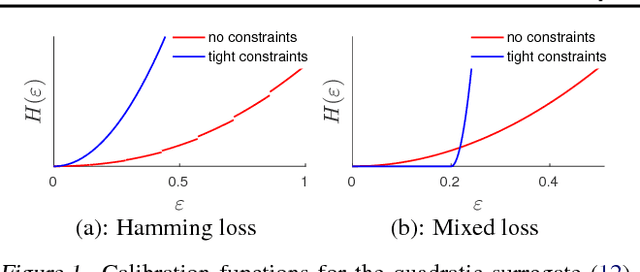
We provide novel theoretical insights on structured prediction in the context of efficient convex surrogate loss minimization with consistency guarantees. For any task loss, we construct a convex surrogate that can be optimized via stochastic gradient descent and we prove tight bounds on the so-called "calibration function" relating the excess surrogate risk to the actual risk. In contrast to prior related work, we carefully monitor the effect of the exponential number of classes in the learning guarantees as well as on the optimization complexity. As an interesting consequence, we formalize the intuition that some task losses make learning harder than others, and that the classical 0-1 loss is ill-suited for general structured prediction.
Improved asynchronous parallel optimization analysis for stochastic incremental methods
Jan 12, 2018

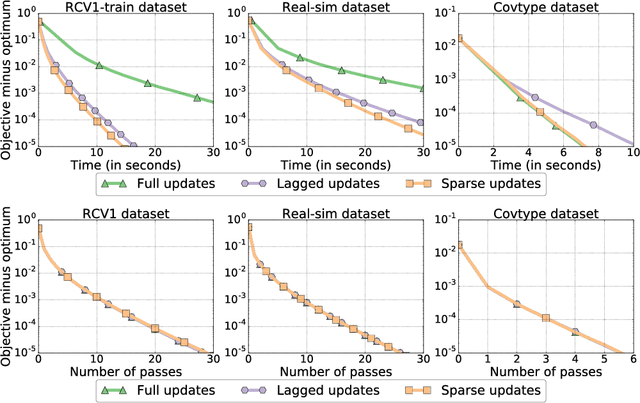

As datasets continue to increase in size and multi-core computer architectures are developed, asynchronous parallel optimization algorithms become more and more essential to the field of Machine Learning. Unfortunately, conducting the theoretical analysis asynchronous methods is difficult, notably due to the introduction of delay and inconsistency in inherently sequential algorithms. Handling these issues often requires resorting to simplifying but unrealistic assumptions. Through a novel perspective, we revisit and clarify a subtle but important technical issue present in a large fraction of the recent convergence rate proofs for asynchronous parallel optimization algorithms, and propose a simplification of the recently introduced "perturbed iterate" framework that resolves it. We demonstrate the usefulness of our new framework by analyzing three distinct asynchronous parallel incremental optimization algorithms: Hogwild (asynchronous SGD), KROMAGNON (asynchronous SVRG) and ASAGA, a novel asynchronous parallel version of the incremental gradient algorithm SAGA that enjoys fast linear convergence rates. We are able to both remove problematic assumptions and obtain better theoretical results. Notably, we prove that ASAGA and KROMAGNON can obtain a theoretical linear speedup on multi-core systems even without sparsity assumptions. We present results of an implementation on a 40-core architecture illustrating the practical speedups as well as the hardware overhead. Finally, we investigate the overlap constant, an ill-understood but central quantity for the theoretical analysis of asynchronous parallel algorithms. We find that it encompasses much more complexity than suggested in previous work, and often is order-of-magnitude bigger than traditionally thought.
A3T: Adversarially Augmented Adversarial Training
Jan 12, 2018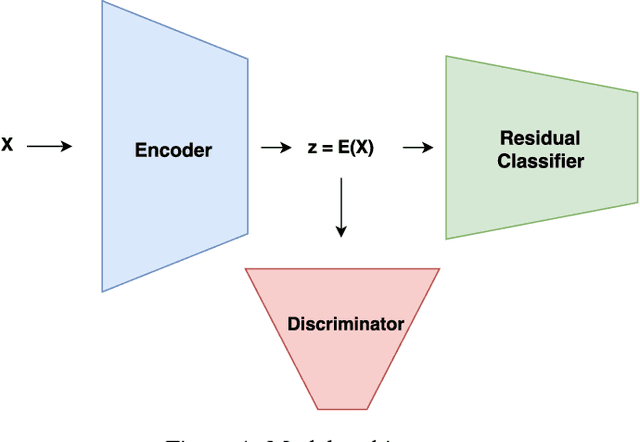

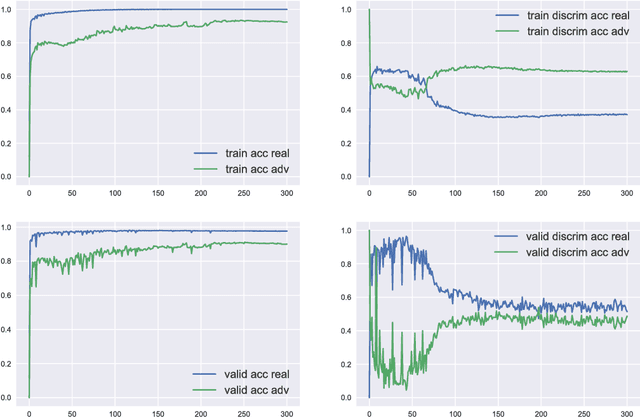
Recent research showed that deep neural networks are highly sensitive to so-called adversarial perturbations, which are tiny perturbations of the input data purposely designed to fool a machine learning classifier. Most classification models, including deep learning models, are highly vulnerable to adversarial attacks. In this work, we investigate a procedure to improve adversarial robustness of deep neural networks through enforcing representation invariance. The idea is to train the classifier jointly with a discriminator attached to one of its hidden layer and trained to filter the adversarial noise. We perform preliminary experiments to test the viability of the approach and to compare it to other standard adversarial training methods.