 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Convolutional Kernel Networks for Airline Crew Scheduling
May 25, 2021
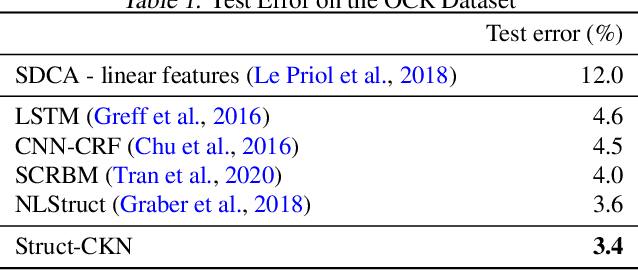
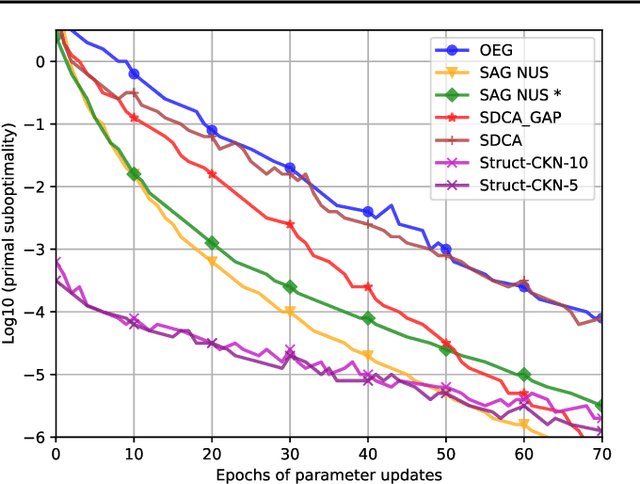
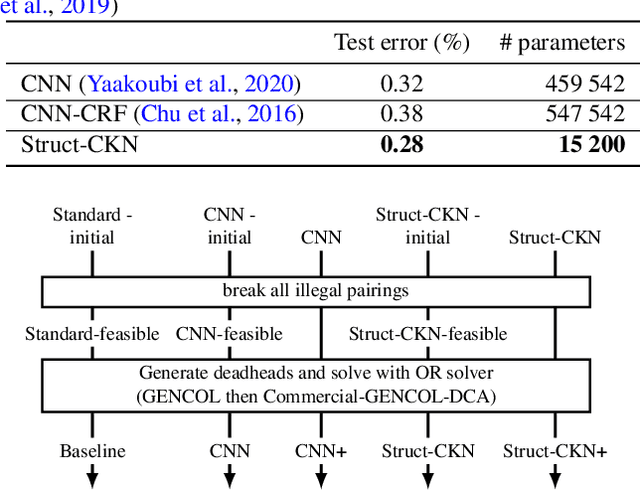
Motivated by the needs from an airline crew scheduling application, we introduce structured convolutional kernel networks (Struct-CKN), which combine CKNs from Mairal et al. (2014) in a structured prediction framework that supports constraints on the outputs. CKNs are a particular kind of convolutional neural networks that approximate a kernel feature map on training data, thus combining properties of deep learning with the non-parametric flexibility of kernel methods. Extending CKNs to structured outputs allows us to obtain useful initial solutions on a flight-connection dataset that can be further refined by an airline crew scheduling solver. More specifically, we use a flight-based network modeled as a general conditional random field capable of incorporating local constraints in the learning process. Our experiments demonstrate that this approach yields significant improvements for the large-scale crew pairing problem (50,000 flights per month) over standard approaches, reducing the solution cost by 17% (a gain of millions of dollars) and the cost of global constraints by 97%.
Repurposing Pretrained Models for Robust Out-of-domain Few-Shot Learning
Mar 16, 2021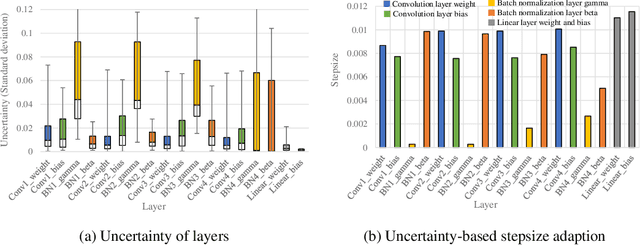
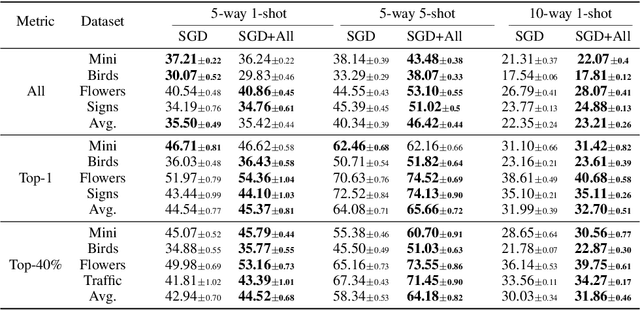
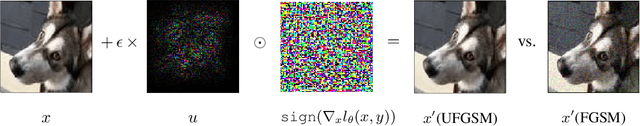
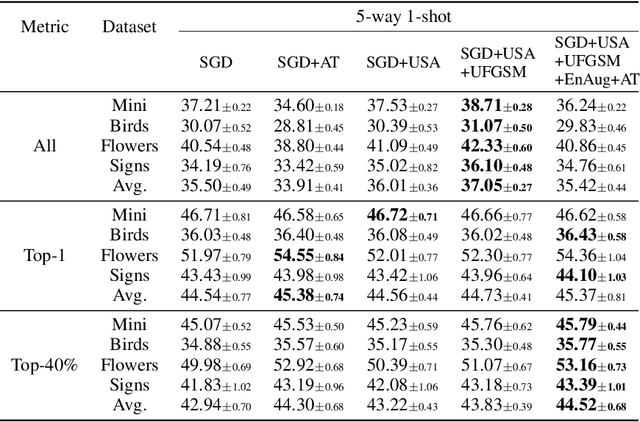
Model-agnostic meta-learning (MAML) is a popular method for few-shot learning but assumes that we have access to the meta-training set. In practice, training on the meta-training set may not always be an option due to data privacy concerns, intellectual property issues, or merely lack of computing resources. In this paper, we consider the novel problem of repurposing pretrained MAML checkpoints to solve new few-shot classification tasks. Because of the potential distribution mismatch, the original MAML steps may no longer be optimal. Therefore we propose an alternative meta-testing procedure and combine MAML gradient steps with adversarial training and uncertainty-based stepsize adaptation. Our method outperforms "vanilla" MAML on same-domain and cross-domains benchmarks using both SGD and Adam optimizers and shows improved robustness to the choice of base stepsize.
Online Adversarial Attacks
Mar 02, 2021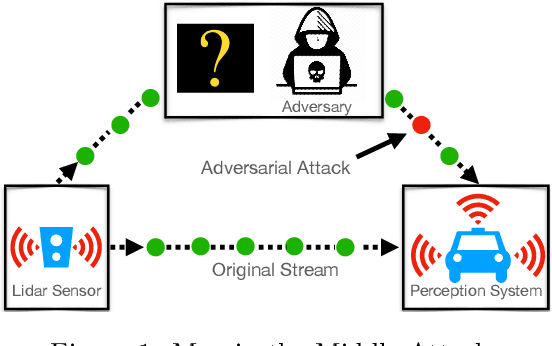
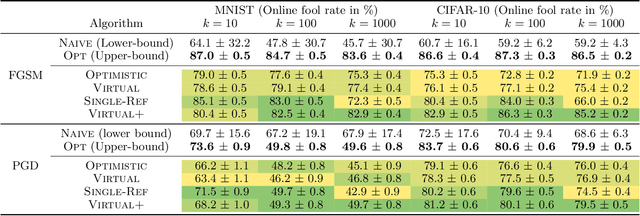
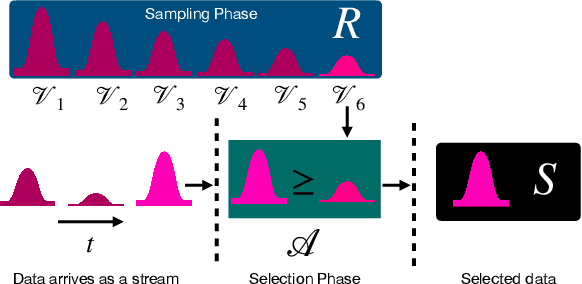
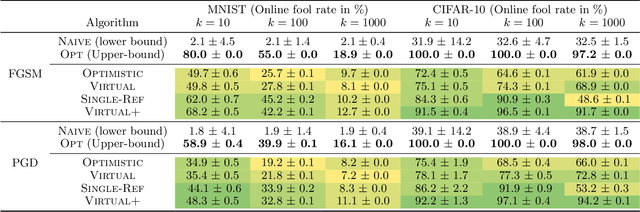
Adversarial attacks expose important vulnerabilities of deep learning models, yet little attention has been paid to settings where data arrives as a stream. In this paper, we formalize the online adversarial attack problem, emphasizing two key elements found in real-world use-cases: attackers must operate under partial knowledge of the target model, and the decisions made by the attacker are irrevocable since they operate on a transient data stream. We first rigorously analyze a deterministic variant of the online threat model by drawing parallels to the well-studied $k$-\textit{secretary problem} and propose \algoname, a simple yet practical algorithm yielding a provably better competitive ratio for $k=2$ over the current best single threshold algorithm. We also introduce the \textit{stochastic $k$-secretary} -- effectively reducing online blackbox attacks to a $k$-secretary problem under noise -- and prove theoretical bounds on the competitive ratios of \textit{any} online algorithms adapted to this setting. Finally, we complement our theoretical results by conducting a systematic suite of experiments on MNIST and CIFAR-10 with both vanilla and robust classifiers, revealing that, by leveraging online secretary algorithms, like \algoname, we can get an online attack success rate close to the one achieved by the optimal offline solution.
SVRG Meets AdaGrad: Painless Variance Reduction
Feb 18, 2021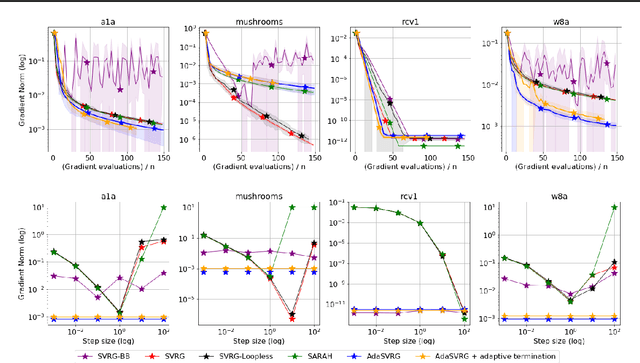
Variance reduction (VR) methods for finite-sum minimization typically require the knowledge of problem-dependent constants that are often unknown and difficult to estimate. To address this, we use ideas from adaptive gradient methods to propose AdaSVRG, which is a fully adaptive variant of SVRG, a common VR method. AdaSVRG uses AdaGrad in the inner loop of SVRG, making it robust to the choice of step-size, and allowing it to adaptively determine the length of each inner-loop. When minimizing a sum of $n$ smooth convex functions, we prove that AdaSVRG requires $O(n + 1/\epsilon)$ gradient evaluations to achieve an $\epsilon$-suboptimality, matching the typical rate, but without needing to know problem-dependent constants. However, VR methods including AdaSVRG are slower than SGD when used with over-parameterized models capable of interpolating the training data. Hence, we also propose a hybrid algorithm that can adaptively switch from AdaGrad to AdaSVRG, achieving the best of both stochastic gradient and VR methods, but without needing to tune their step-sizes. Via experiments on synthetic and standard real-world datasets, we validate the robustness and effectiveness of AdaSVRG, demonstrating its superior performance over other "tune-free" VR methods.
On the Convergence of Continuous Constrained Optimization for Structure Learning
Dec 16, 2020
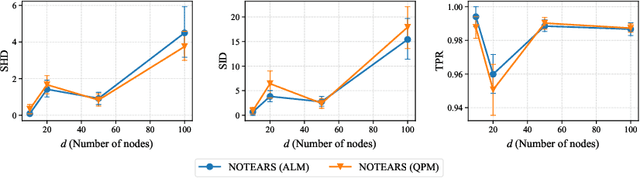
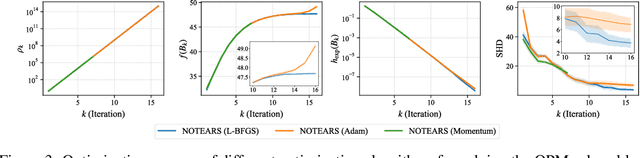
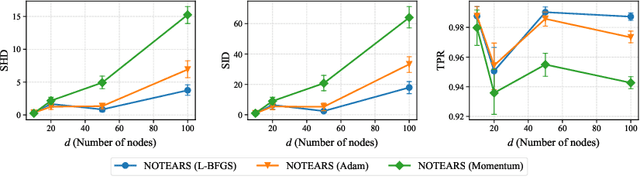
Structure learning of directed acyclic graphs (DAGs) is a fundamental problem in many scientific endeavors. A new line of work, based on NOTEARS (Zheng et al., 2018), reformulates the structure learning problem as a continuous optimization one by leveraging an algebraic characterization of DAG constraint. The constrained problem is typically solved using the augmented Lagrangian method (ALM) which is often preferred to the quadratic penalty method (QPM) by virtue of its convergence result that does not require the penalty coefficient to go to infinity, hence avoiding ill-conditioning. In this work, we review the standard convergence result of the ALM and show that the required conditions are not satisfied in the recent continuous constrained formulation for learning DAGs. We demonstrate empirically that its behavior is akin to that of the QPM which is prone to ill-conditioning, thus motivating the use of second-order method in this setting. We also establish the convergence guarantee of QPM to a DAG solution, under mild conditions, based on a property of the DAG constraint term.
Geometry-Aware Universal Mirror-Prox
Nov 23, 2020Mirror-prox (MP) is a well-known algorithm to solve variational inequality (VI) problems. VI with a monotone operator covers a large group of settings such as convex minimization, min-max or saddle point problems. To get a convergent algorithm, the step-size of the classic MP algorithm relies heavily on the problem dependent knowledge of the operator such as its smoothness parameter which is hard to estimate. Recently, a universal variant of MP for smooth/bounded operators has been introduced that depends only on the norm of updates in MP. In this work, we relax the dependence to evaluating the norm of updates to Bregman divergence between updates. This relaxation allows us to extends the analysis of universal MP to the settings where the operator is not smooth or bounded. Furthermore, we analyse the VI problem with a stochastic monotone operator in different settings and obtain an optimal rate up to a logarithmic factor.
Machine Learning in Airline Crew Pairing to Construct Initial Clusters for Dynamic Constraint Aggregation
Sep 30, 2020
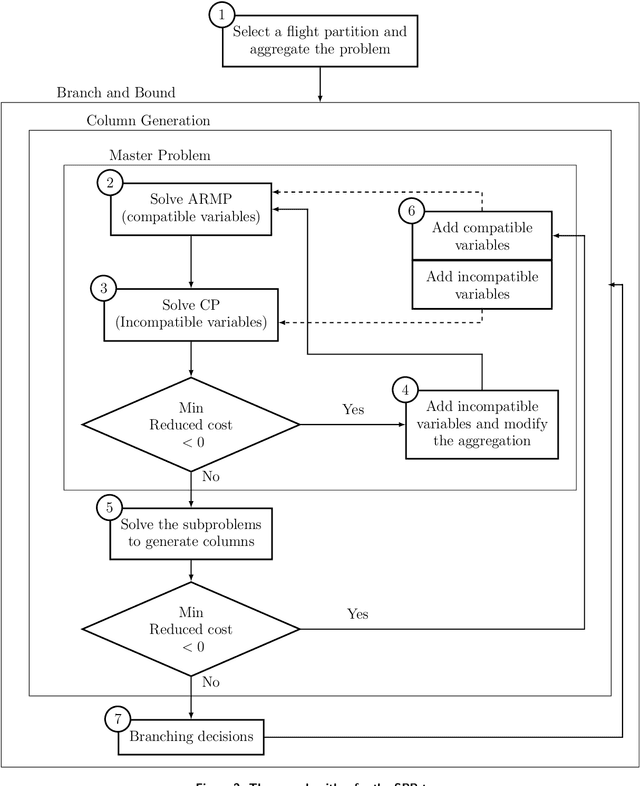
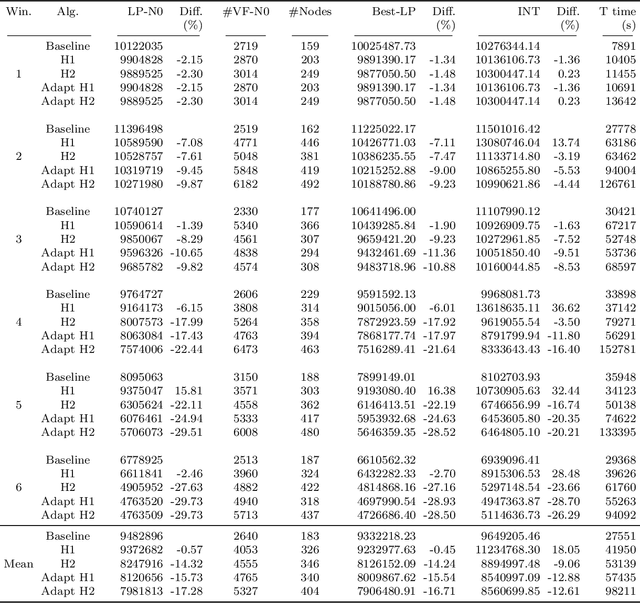
The crew pairing problem (CPP) is generally modelled as a set partitioning problem where the flights have to be partitioned in pairings. A pairing is a sequence of flight legs separated by connection time and rest periods that starts and ends at the same base. Because of the extensive list of complex rules and regulations, determining whether a sequence of flights constitutes a feasible pairing can be quite difficult by itself, making CPP one of the hardest of the airline planning problems. In this paper, we first propose to improve the prototype Baseline solver of Desaulniers et al. (2020) by adding dynamic control strategies to obtain an efficient solver for large-scale CPPs: Commercial-GENCOL-DCA. These solvers are designed to aggregate the flights covering constraints to reduce the size of the problem. Then, we use machine learning (ML) to produce clusters of flights having a high probability of being performed consecutively by the same crew. The solver combines several advanced Operations Research techniques to assemble and modify these clusters, when necessary, to produce a good solution. We show, on monthly CPPs with up to 50 000 flights, that Commercial-GENCOL-DCA with clusters produced by ML-based heuristics outperforms Baseline fed by initial clusters that are pairings of a solution obtained by rolling horizon with GENCOL. The reduction of solution cost averages between 6.8% and 8.52%, which is mainly due to the reduction in the cost of global constraints between 69.79% and 78.11%.
* First publication in the "Cahiers du GERAD" series in February 2020. Submitted to EURO Journal on Transportation and Logistics on January 17, 2020 and available online on September 2, 2020
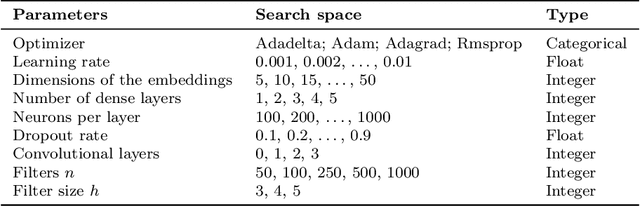
Flight-connection Prediction for Airline Crew Scheduling to Construct Initial Clusters for OR Optimizer
Sep 26, 2020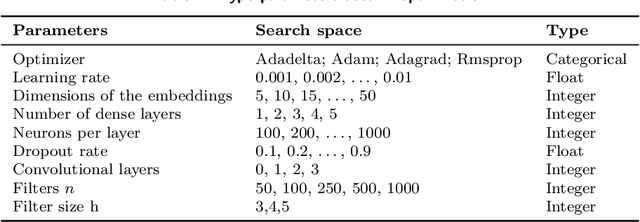

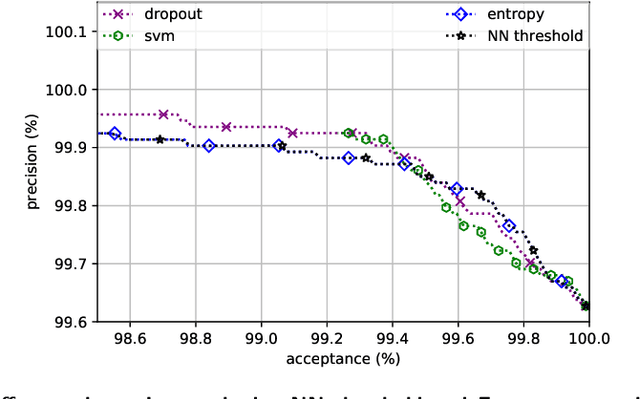
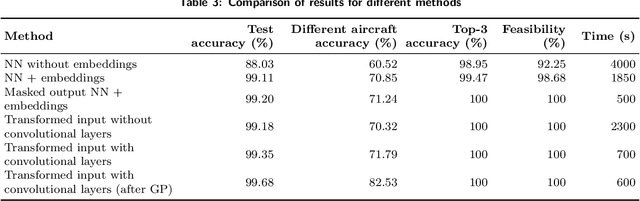
We present a case study of using machine learning classification algorithms to initialize a large scale commercial operations research solver (GENCOL) in the context of the airline crew pairing problem, where small savings of as little as 1% translate to increasing annual revenue by millions of dollars in a large airline. We focus on the problem of predicting the next connecting flight of a crew, framed as a multiclass classification problem trained from historical data, and design an adapted neural network approach that achieves high accuracy (99.7% overall or 82.5% on harder instances). We demonstrate the usefulness of our approach by using simple heuristics to combine the flight-connection predictions to form initial crew-pairing clusters that can be fed in the GENCOL solver, yielding a 10x speed improvement and up to 0.2% cost saving.
Implicit Regularization in Deep Learning: A View from Function Space
Aug 03, 2020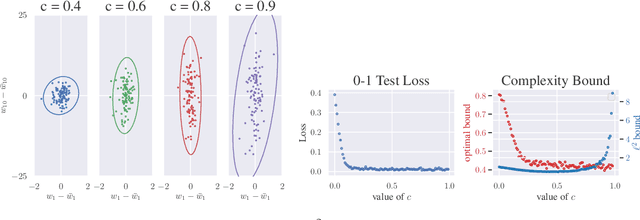
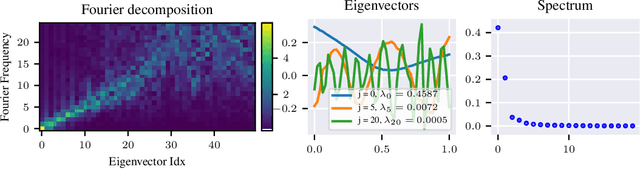
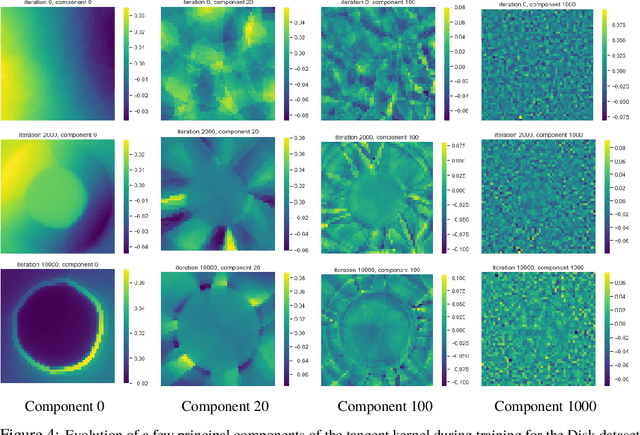
We approach the problem of implicit regularization in deep learning from a geometrical viewpoint. We highlight a possible regularization effect induced by a dynamical alignment of the neural tangent features introduced by Jacot et al, along a small number of task-relevant directions. By extrapolating a new analysis of Rademacher complexity bounds in linear models, we propose and study a new heuristic complexity measure for neural networks which captures this phenomenon, in terms of sequences of tangent kernel classes along in the learning trajectories.
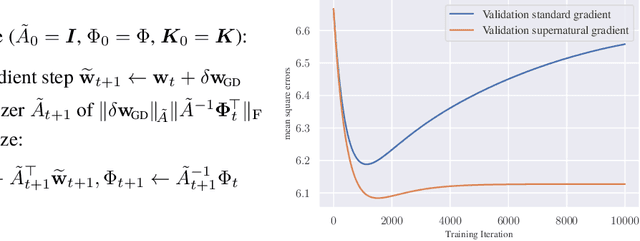
Stochastic Hamiltonian Gradient Methods for Smooth Games
Jul 08, 2020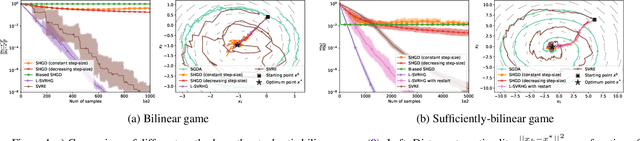

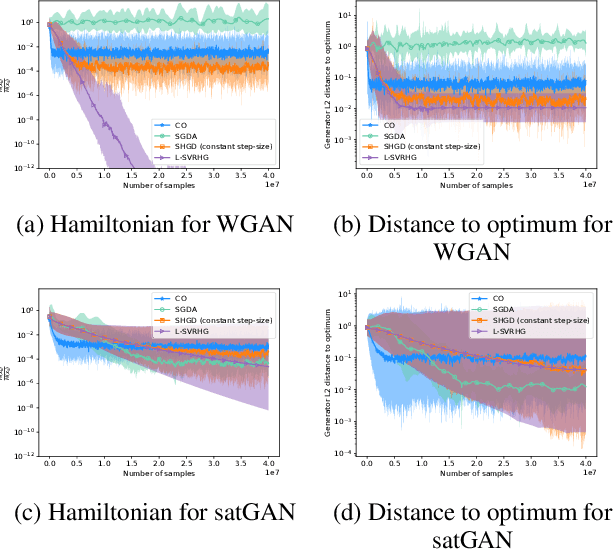

The success of adversarial formulations in machine learning has brought renewed motivation for smooth games. In this work, we focus on the class of stochastic Hamiltonian methods and provide the first convergence guarantees for certain classes of stochastic smooth games. We propose a novel unbiased estimator for the stochastic Hamiltonian gradient descent (SHGD) and highlight its benefits. Using tools from the optimization literature we show that SHGD converges linearly to the neighbourhood of a stationary point. To guarantee convergence to the exact solution, we analyze SHGD with a decreasing step-size and we also present the first stochastic variance reduced Hamiltonian method. Our results provide the first global non-asymptotic last-iterate convergence guarantees for the class of stochastic unconstrained bilinear games and for the more general class of stochastic games that satisfy a "sufficiently bilinear" condition, notably including some non-convex non-concave problems. We supplement our analysis with experiments on stochastic bilinear and sufficiently bilinear games, where our theory is shown to be tight, and on simple adversarial machine learning formulations.