 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymphony for Medical Coding: A Next-Generation Agentic System for Scalable and Explainable Medical Coding
Mar 31, 2026Medical coding translates free-text clinical documentation into standardized codes drawn from classification systems that contain tens of thousands of entries and are updated annually. It is central to billing, clinical research, and quality reporting, yet remains largely manual, slow, and error-prone. Existing automated approaches learn to predict a fixed set of codes from labeled data, thereby preventing adaptation to new codes or different coding systems without retraining on different data. They also provide no explanation for their predictions, limiting trust in safety-critical settings. We introduce Symphony for Medical Coding, a system that approaches the task the way expert human coders do: by reasoning over the clinical narrative with direct access to the coding guidelines. This design allows Symphony to operate across any coding system and to provide span-level evidence linking each predicted code to the text that supports it. We evaluate on two public benchmarks and three real-world datasets spanning inpatient, outpatient, emergency, and subspecialty settings across the United States and the United Kingdom. Symphony achieves state-of-the-art results across all settings, establishing itself as a flexible, deployment-ready foundation for automated clinical coding.
Grammatical Error Correction in Low Error Density Domains: A New Benchmark and Analyses
Oct 15, 2020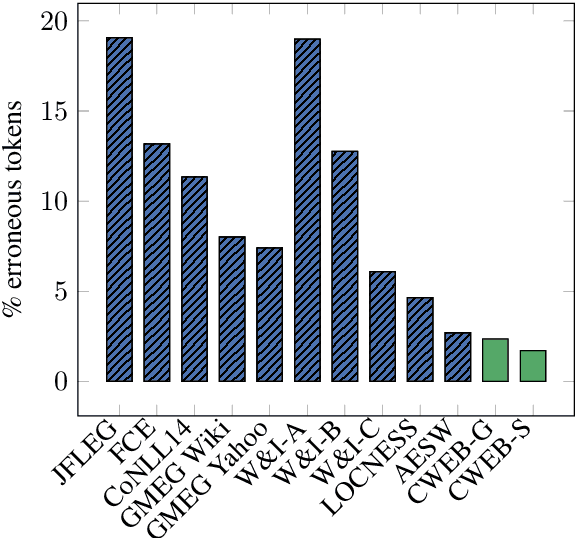

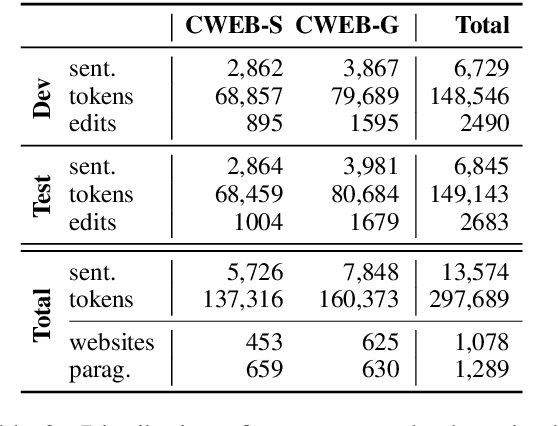
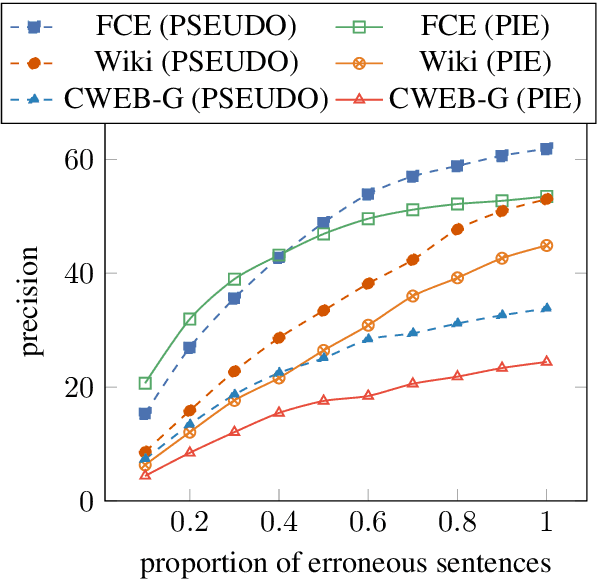
Evaluation of grammatical error correction (GEC) systems has primarily focused on essays written by non-native learners of English, which however is only part of the full spectrum of GEC applications. We aim to broaden the target domain of GEC and release CWEB, a new benchmark for GEC consisting of website text generated by English speakers of varying levels of proficiency. Website data is a common and important domain that contains far fewer grammatical errors than learner essays, which we show presents a challenge to state-of-the-art GEC systems. We demonstrate that a factor behind this is the inability of systems to rely on a strong internal language model in low error density domains. We hope this work shall facilitate the development of open-domain GEC models that generalize to different topics and genres.