 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Tracking in Surgery--The 2024 Surgical Tattoos in Infrared (STIR) Challenge
Mar 31, 2025Understanding tissue motion in surgery is crucial to enable applications in downstream tasks such as segmentation, 3D reconstruction, virtual tissue landmarking, autonomous probe-based scanning, and subtask autonomy. Labeled data are essential to enabling algorithms in these downstream tasks since they allow us to quantify and train algorithms. This paper introduces a point tracking challenge to address this, wherein participants can submit their algorithms for quantification. The submitted algorithms are evaluated using a dataset named surgical tattoos in infrared (STIR), with the challenge aptly named the STIR Challenge 2024. The STIR Challenge 2024 comprises two quantitative components: accuracy and efficiency. The accuracy component tests the accuracy of algorithms on in vivo and ex vivo sequences. The efficiency component tests the latency of algorithm inference. The challenge was conducted as a part of MICCAI EndoVis 2024. In this challenge, we had 8 total teams, with 4 teams submitting before and 4 submitting after challenge day. This paper details the STIR Challenge 2024, which serves to move the field towards more accurate and efficient algorithms for spatial understanding in surgery. In this paper we summarize the design, submissions, and results from the challenge. The challenge dataset is available here: https://zenodo.org/records/14803158 , and the code for baseline models and metric calculation is available here: https://github.com/athaddius/STIRMetrics
Tracking and Mapping in Medical Computer Vision: A Review
Oct 17, 2023



As computer vision algorithms are becoming more capable, their applications in clinical systems will become more pervasive. These applications include diagnostics such as colonoscopy and bronchoscopy, guiding biopsies and minimally invasive interventions and surgery, automating instrument motion and providing image guidance using pre-operative scans. Many of these applications depend on the specific visual nature of medical scenes and require designing and applying algorithms to perform in this environment. In this review, we provide an update to the field of camera-based tracking and scene mapping in surgery and diagnostics in medical computer vision. We begin with describing our review process, which results in a final list of 515 papers that we cover. We then give a high-level summary of the state of the art and provide relevant background for those who need tracking and mapping for their clinical applications. We then review datasets provided in the field and the clinical needs therein. Then, we delve in depth into the algorithmic side, and summarize recent developments, which should be especially useful for algorithm designers and to those looking to understand the capability of off-the-shelf methods. We focus on algorithms for deformable environments while also reviewing the essential building blocks in rigid tracking and mapping since there is a large amount of crossover in methods. Finally, we discuss the current state of the tracking and mapping methods along with needs for future algorithms, needs for quantification, and the viability of clinical applications in the field. We conclude that new methods need to be designed or combined to support clinical applications in deformable environments, and more focus needs to be put into collecting datasets for training and evaluation.
STIR: Surgical Tattoos in Infrared
Sep 28, 2023Quantifying performance of methods for tracking and mapping tissue in endoscopic environments is essential for enabling image guidance and automation of medical interventions and surgery. Datasets developed so far either use rigid environments, visible markers, or require annotators to label salient points in videos after collection. These are respectively: not general, visible to algorithms, or costly and error-prone. We introduce a novel labeling methodology along with a dataset that uses said methodology, Surgical Tattoos in Infrared (STIR). STIR has labels that are persistent but invisible to visible spectrum algorithms. This is done by labelling tissue points with IR-flourescent dye, indocyanine green (ICG), and then collecting visible light video clips. STIR comprises hundreds of stereo video clips in both in-vivo and ex-vivo scenes with start and end points labelled in the IR spectrum. With over 3,000 labelled points, STIR will help to quantify and enable better analysis of tracking and mapping methods. After introducing STIR, we analyze multiple different frame-based tracking methods on STIR using both 3D and 2D endpoint error and accuracy metrics. STIR is available at https://dx.doi.org/10.21227/w8g4-g548
SENDD: Sparse Efficient Neural Depth and Deformation for Tissue Tracking
May 10, 2023Deformable tracking and real-time estimation of 3D tissue motion is essential to enable automation and image guidance applications in robotically assisted surgery. Our model, Sparse Efficient Neural Depth and Deformation (SENDD), extends prior 2D tracking work to estimate flow in 3D space. SENDD introduces novel contributions of learned detection, and sparse per-point depth and 3D flow estimation, all with less than half a million parameters. SENDD does this by using graph neural networks of sparse keypoint matches to estimate both depth and 3D flow. We quantify and benchmark SENDD on a comprehensively labelled tissue dataset, and compare it to an equivalent 2D flow model. SENDD performs comparably while enabling applications that 2D flow cannot. SENDD can track points and estimate depth at 10fps on an NVIDIA RTX 4000 for 1280 tracked (query) points and its cost scales linearly with an increasing/decreasing number of points. SENDD enables multiple downstream applications that require 3D motion estimation.
A Robotic 3D Perception System for Operating Room Environment Awareness
Mar 30, 2020

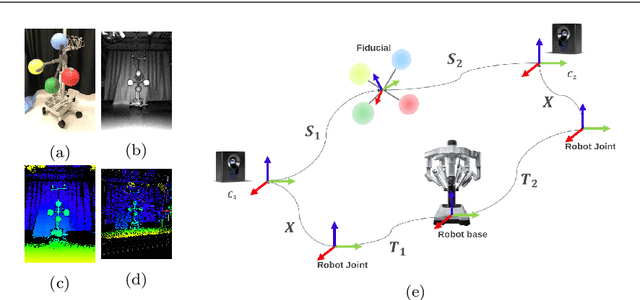

Purpose: We describe a 3D multi-view perception system for the da Vinci surgical system to enable Operating room (OR) scene understanding and context awareness. Methods: Our proposed system is comprised of four Time-of-Flight (ToF) cameras rigidly attached to strategic locations on the daVinci Xi patient side cart (PSC). The cameras are registered to the robot's kinematic chain by performing a one-time calibration routine and therefore, information from all cameras can be fused and represented in one common coordinate frame. Based on this architecture, a multi-view 3D scene semantic segmentation algorithm is created to enable recognition of common and salient objects/equipment and surgical activities in a da Vinci OR. Our proposed 3D semantic segmentation method has been trained and validated on a novel densely annotated dataset that has been captured from clinical scenarios. Results: The results show that our proposed architecture has acceptable registration error ($3.3\%\pm1.4\%$ of object-camera distance) and can robustly improve scene segmentation performance (mean Intersection Over Union - mIOU) for less frequently appearing classes ($\ge 0.013$) compared to a single-view method. Conclusion: We present the first dynamic multi-view perception system with a novel segmentation architecture, which can be used as a building block technology for applications such as surgical workflow analysis, automation of surgical sub-tasks and advanced guidance systems.