 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards interpretable AI with quantum annealing feature selection
Apr 28, 2026Deep learning models are used in critical applications, in which mistakes can have serious consequences. Therefore, it is crucial to understand how and why models generate predictions. This understanding provides useful information to check whether the model is learning the right patterns, detect biases in the data, improve model design, and build systems that can be trusted. This work proposes a new method for interpreting Convolutional Neural Networks in image classification tasks. The approach works by selecting the most important feature maps that contribute to each prediction. To solve this combinatorial problem, we encode it into a quantum constrained optimization problem and propose to solve it using quantum annealing. We evaluate our method against the state-of-the-art explainable AI techniques, specifically GradCAM and GradCAM++, and observe an improved class disentanglement, i.e. the model's decision boundaries become more distinct and its reasoning more transparent. This demonstrates that our approach enhances the quality of explanations, making it easier to understand which features the model relies on for specific predictions. In addition, we study the computational behavior of the quantum annealing algorithm. Specifically, we analyze the minimum energy gap of the system during computation and the probability that the algorithm finds the correct solution. These analyses provide theoretical insight into why the method works effectively in practice.
Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS) challenge results
May 13, 2025



Deep learning (DL) has become the dominant approach for medical image segmentation, yet ensuring the reliability and clinical applicability of these models requires addressing key challenges such as annotation variability, calibration, and uncertainty estimation. This is why we created the Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS), which highlights the critical role of multiple annotators in establishing a more comprehensive ground truth, emphasizing that segmentation is inherently subjective and that leveraging inter-annotator variability is essential for robust model evaluation. Seven teams participated in the challenge, submitting a variety of DL models evaluated using metrics such as Dice Similarity Coefficient (DSC), Expected Calibration Error (ECE), and Continuous Ranked Probability Score (CRPS). By incorporating consensus and dissensus ground truth, we assess how DL models handle uncertainty and whether their confidence estimates align with true segmentation performance. Our findings reinforce the importance of well-calibrated models, as better calibration is strongly correlated with the quality of the results. Furthermore, we demonstrate that segmentation models trained on diverse datasets and enriched with pre-trained knowledge exhibit greater robustness, particularly in cases deviating from standard anatomical structures. Notably, the best-performing models achieved high DSC and well-calibrated uncertainty estimates. This work underscores the need for multi-annotator ground truth, thorough calibration assessments, and uncertainty-aware evaluations to develop trustworthy and clinically reliable DL-based medical image segmentation models.
Interpreting CNN Predictions using Conditional Generative Adversarial Networks
Jan 19, 2023



We propose a novel method that trains a conditional Generative Adversarial Network (GAN) to generate visual interpretations of a Convolutional Neural Network (CNN). To comprehend a CNN, the GAN is trained with information on how the CNN processes an image when making predictions. Supplying that information has two main challenges: how to represent this information in a form that is feedable to the GANs and how to effectively feed the representation to the GAN. To address these issues, we developed a suitable representation of CNN architectures by cumulatively averaging intermediate interpretation maps. We also propose two alternative approaches to feed the representations to the GAN and to choose an effective training strategy. Our approach learned the general aspects of CNNs and was agnostic to datasets and CNN architectures. The study includes both qualitative and quantitative evaluations and compares the proposed GANs with state-of-the-art approaches. We found that the initial layers of CNNs and final layers are equally crucial for interpreting CNNs upon interpreting the proposed GAN. We believe training a GAN to interpret CNNs would open doors for improved interpretations by leveraging fast-paced deep learning advancements. The code used for experimentation is publicly available at https://github.com/Akash-guna/Explain-CNN-With-GANS
Salient Region Detection and Segmentation in Images using Dynamic Mode Decomposition
Jul 11, 2016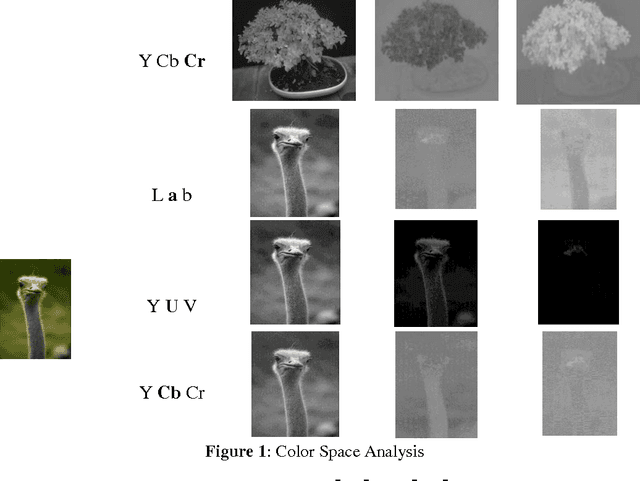


Visual Saliency is the capability of vision system to select distinctive parts of scene and reduce the amount of visual data that need to be processed. The presentpaper introduces (1) a novel approach to detect salient regions by considering color and luminance based saliency scores using Dynamic Mode Decomposition (DMD), (2) a new interpretation to use DMD approach in static image processing. This approach integrates two data analysis methods: (1) Fourier Transform, (2) Principle Component Analysis.The key idea of our work is to create a color based saliency map. This is based on the observation thatsalient part of an image usually have distinct colors compared to the remaining portion of the image. We have exploited the power of different color spaces to model the complex and nonlinear behavior of human visual system to generate a color based saliency map. To further improve the effect of final saliency map, weutilized luminance information exploiting the fact that human eye is more sensitive towards brightness than color.The experimental results shows that our method based on DMD theory is effective in comparison with previous state-of-art saliency estimation approaches. The approach presented in this paperis evaluated using ROC curve, F-measure rate, Precision-Recall rate, AUC score etc.