 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Parallel Training with GPU Concurrency of Deep Residual Neural Networks Via Nonlinear Multigrid
Jul 14, 2020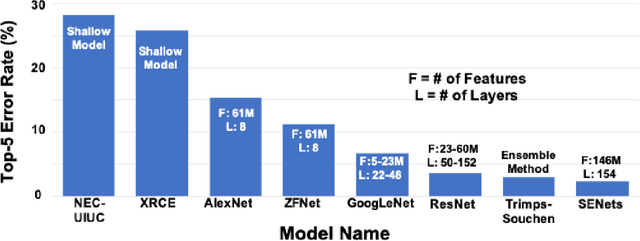
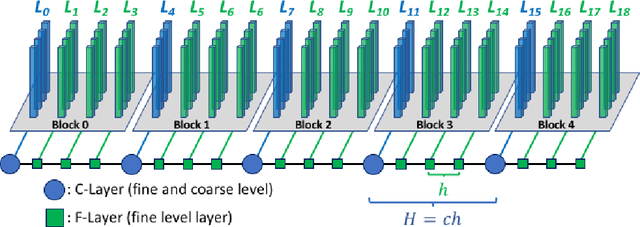

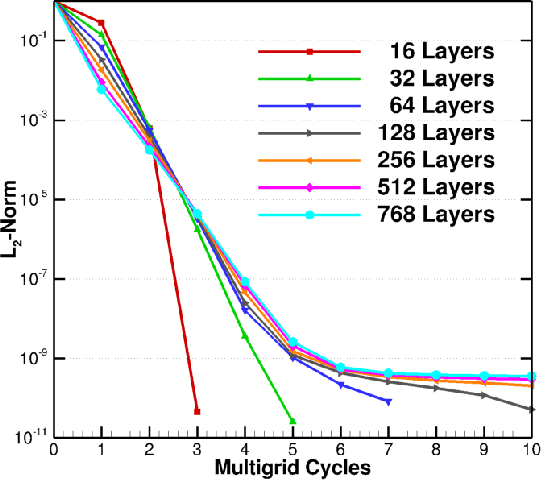
A Multigrid Full Approximation Storage algorithm for solving Deep Residual Networks is developed to enable neural network parallelized layer-wise training and concurrent computational kernel execution on GPUs. This work demonstrates a 10.2x speedup over traditional layer-wise model parallelism techniques using the same number of compute units.
TapirXLA: Embedding Fork-Join Parallelism into the XLA Compiler in TensorFlow Using Tapir
Aug 29, 2019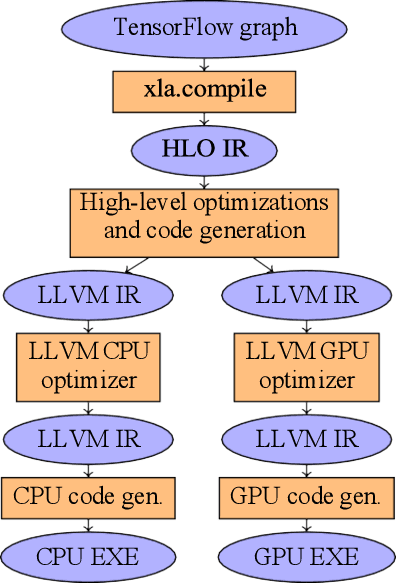
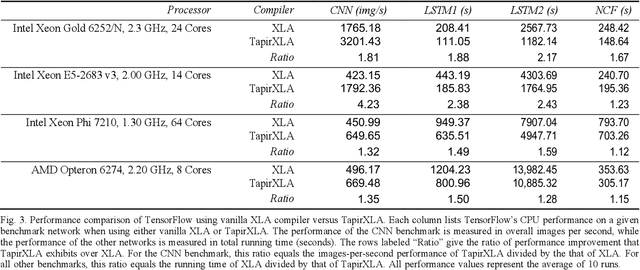
This work introduces TapirXLA, a replacement for TensorFlow's XLA compiler that embeds recursive fork-join parallelism into XLA's low-level representation of code. Machine-learning applications rely on efficient parallel processing to achieve performance, and they employ a variety of technologies to improve performance, including compiler technology. But compilers in machine-learning frameworks lack a deep understanding of parallelism, causing them to lose performance by missing optimizations on parallel computation. This work studies how Tapir, a compiler intermediate representation (IR) that embeds parallelism into a mainstream compiler IR, can be incorporated into a compiler for machine learning to remedy this problem. TapirXLA modifies the XLA compiler in TensorFlow to employ the Tapir/LLVM compiler to optimize low-level parallel computation. TapirXLA encodes the parallelism within high-level TensorFlow operations using Tapir's representation of fork-join parallelism. TapirXLA also exposes to the compiler implementations of linear-algebra library routines whose parallel operations are encoded using Tapir's representation. We compared the performance of TensorFlow using TapirXLA against TensorFlow using an unmodified XLA compiler. On four neural-network benchmarks, TapirXLA speeds up the parallel running time of the network by a geometric-mean multiplicative factor of 30% to 100%, across four CPU architectures.
Distributed Deep Learning for Precipitation Nowcasting
Aug 28, 2019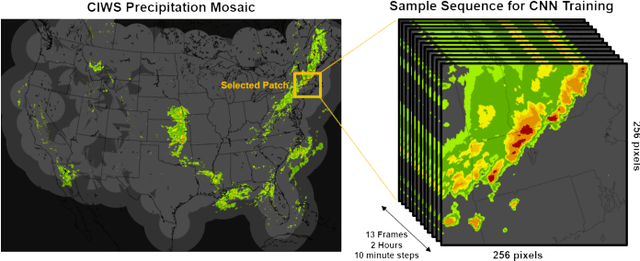
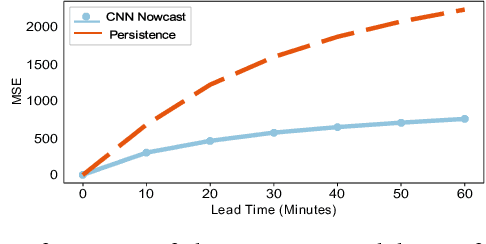
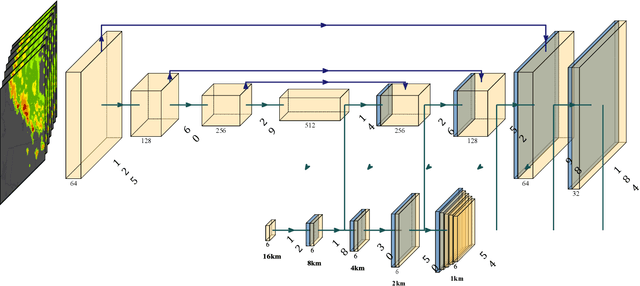
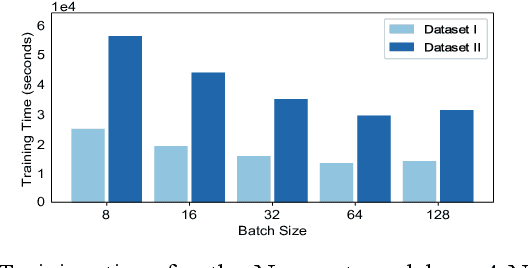
Effective training of Deep Neural Networks requires massive amounts of data and compute. As a result, longer times are needed to train complex models requiring large datasets, which can severely limit research on model development and the exploitation of all available data. In this paper, this problem is investigated in the context of precipitation nowcasting, a term used to describe highly detailed short-term forecasts of precipitation and other hazardous weather. Convolutional Neural Networks (CNNs) are a powerful class of models that are well-suited for this task; however, the high resolution input weather imagery combined with model complexity required to process this data makes training CNNs to solve this task time consuming. To address this issue, a data-parallel model is implemented where a CNN is replicated across multiple compute nodes and the training batches are distributed across multiple nodes. By leveraging multiple GPUs, we show that the training time for a given nowcasting model architecture can be reduced from 59 hours to just over 1 hour. This will allow for faster iterations for improving CNN architectures and will facilitate future advancement in the area of nowcasting.
Large Scale Organization and Inference of an Imagery Dataset for Public Safety
Aug 16, 2019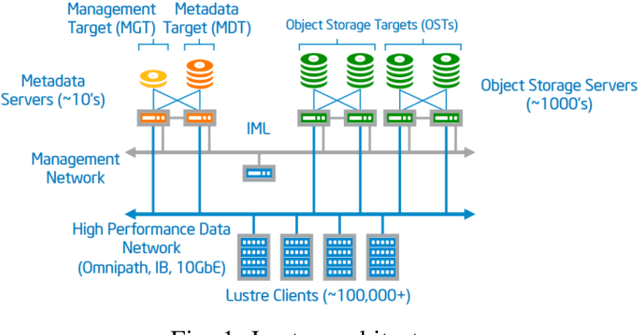

Video applications and analytics are routinely projected as a stressing and significant service of the Nationwide Public Safety Broadband Network. As part of a NIST PSCR funded effort, the New Jersey Office of Homeland Security and Preparedness and MIT Lincoln Laboratory have been developing a computer vision dataset of operational and representative public safety scenarios. The scale and scope of this dataset necessitates a hierarchical organization approach for efficient compute and storage. We overview architectural considerations using the Lincoln Laboratory Supercomputing Cluster as a test architecture. We then describe how we intelligently organized the dataset across LLSC and evaluated it with large scale imagery inference across terabytes of data.
AI Enabling Technologies: A Survey
May 08, 2019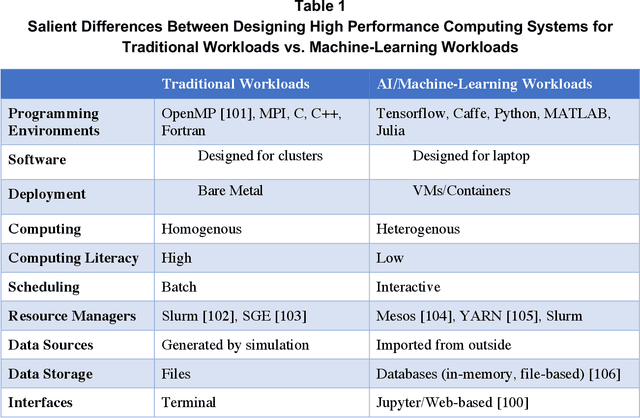
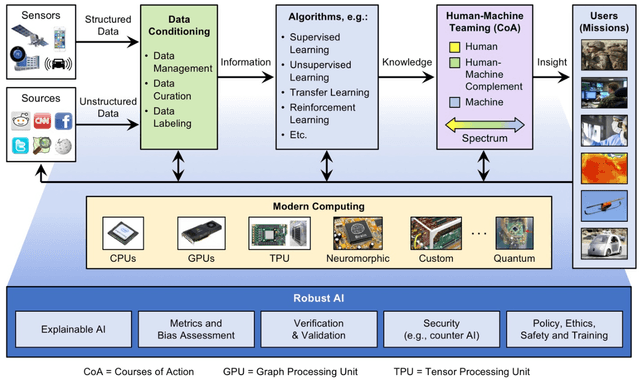

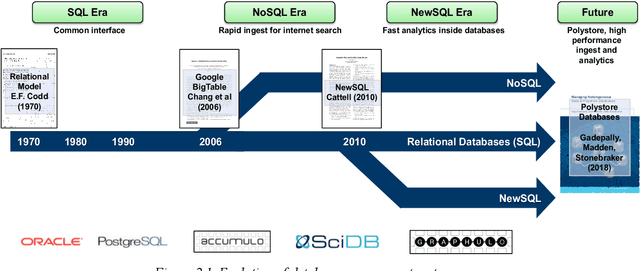
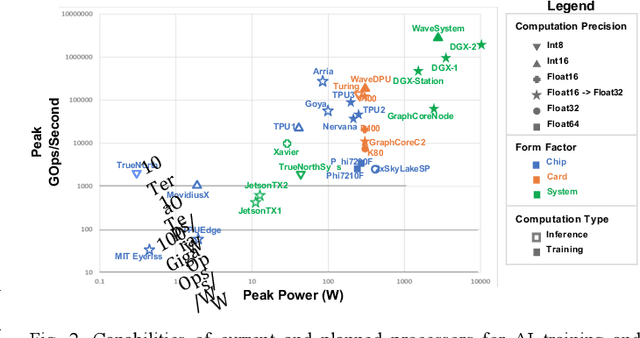
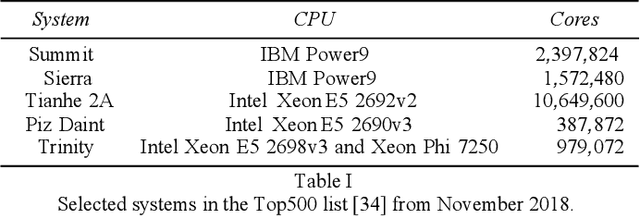
Artificial Intelligence (AI) has the opportunity to revolutionize the way the United States Department of Defense (DoD) and Intelligence Community (IC) address the challenges of evolving threats, data deluge, and rapid courses of action. Developing an end-to-end artificial intelligence system involves parallel development of different pieces that must work together in order to provide capabilities that can be used by decision makers, warfighters and analysts. These pieces include data collection, data conditioning, algorithms, computing, robust artificial intelligence, and human-machine teaming. While much of the popular press today surrounds advances in algorithms and computing, most modern AI systems leverage advances across numerous different fields. Further, while certain components may not be as visible to end-users as others, our experience has shown that each of these interrelated components play a major role in the success or failure of an AI system. This article is meant to highlight many of these technologies that are involved in an end-to-end AI system. The goal of this article is to provide readers with an overview of terminology, technical details and recent highlights from academia, industry and government. Where possible, we indicate relevant resources that can be used for further reading and understanding.