 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Resource Usage for Efficient Distributed Deep Learning
Jan 28, 2022



Deep learning (DL) workflows demand an ever-increasing budget of compute and energy in order to achieve outsized gains. Neural architecture searches, hyperparameter sweeps, and rapid prototyping consume immense resources that can prevent resource-constrained researchers from experimenting with large models and carry considerable environmental impact. As such, it becomes essential to understand how different deep neural networks (DNNs) and training leverage increasing compute and energy resources -- especially specialized computationally-intensive models across different domains and applications. In this paper, we conduct over 3,400 experiments training an array of deep networks representing various domains/tasks -- natural language processing, computer vision, and chemistry -- on up to 424 graphics processing units (GPUs). During training, our experiments systematically vary compute resource characteristics and energy-saving mechanisms such as power utilization and GPU clock rate limits to capture and illustrate the different trade-offs and scaling behaviors each representative model exhibits under various resource and energy-constrained regimes. We fit power law models that describe how training time scales with available compute resources and energy constraints. We anticipate that these findings will help inform and guide high-performance computing providers in optimizing resource utilization, by selectively reducing energy consumption for different deep learning tasks/workflows with minimal impact on training.
Bringing Atomistic Deep Learning to Prime Time
Dec 09, 2021
Artificial intelligence has not yet revolutionized the design of materials and molecules. In this perspective, we identify four barriers preventing the integration of atomistic deep learning, molecular science, and high-performance computing. We outline focused research efforts to address the opportunities presented by these challenges.
Scalable Geometric Deep Learning on Molecular Graphs
Dec 06, 2021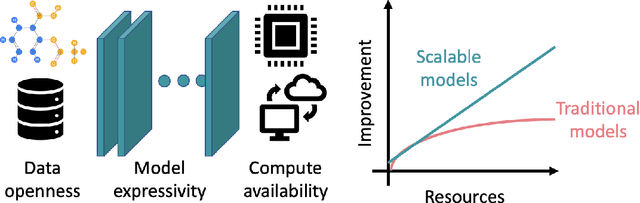

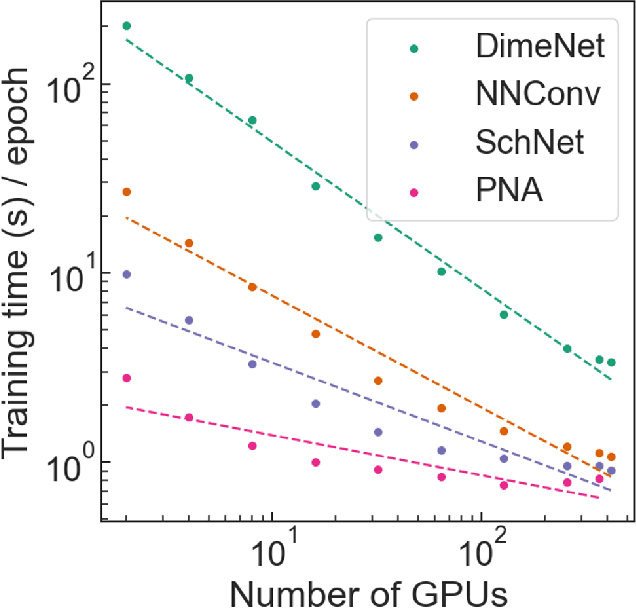
Deep learning in molecular and materials sciences is limited by the lack of integration between applied science, artificial intelligence, and high-performance computing. Bottlenecks with respect to the amount of training data, the size and complexity of model architectures, and the scale of the compute infrastructure are all key factors limiting the scaling of deep learning for molecules and materials. Here, we present $\textit{LitMatter}$, a lightweight framework for scaling molecular deep learning methods. We train four graph neural network architectures on over 400 GPUs and investigate the scaling behavior of these methods. Depending on the model architecture, training time speedups up to $60\times$ are seen. Empirical neural scaling relations quantify the model-dependent scaling and enable optimal compute resource allocation and the identification of scalable molecular geometric deep learning model implementations.
The Pseudo Projection Operator: Applications of Deep Learning to Projection Based Filtering in Non-Trivial Frequency Regimes
Nov 13, 2021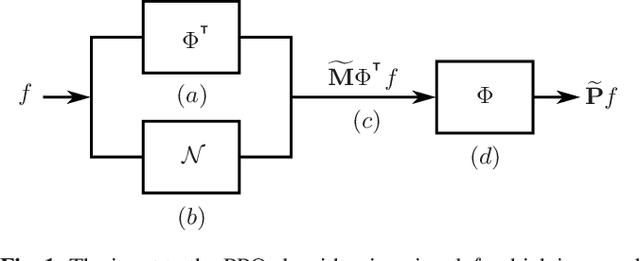
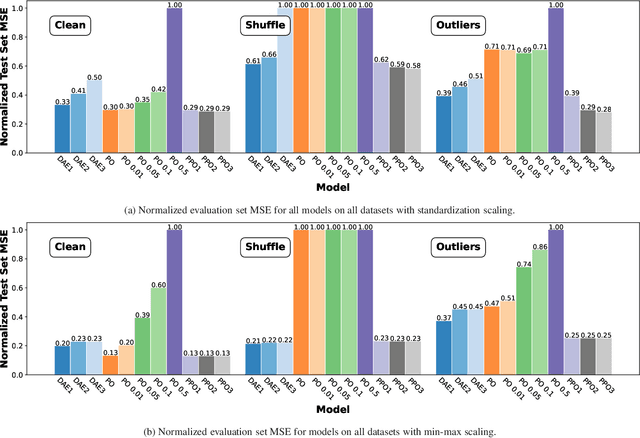
Traditional frequency based projection filters, or projection operators (PO), separate signal and noise through a series of transformations which remove frequencies where noise is present. However, this technique relies on a priori knowledge of what frequencies contain signal and noise and that these frequencies do not overlap, which is difficult to achieve in practice. To address these issues, we introduce a PO-neural network hybrid model, the Pseudo Projection Operator (PPO), which leverages a neural network to perform frequency selection. We compare the filtering capabilities of a PPO, PO, and denoising autoencoder (DAE) on the University of Rochester Multi-Modal Music Performance Dataset with a variety of added noise types. In the majority of experiments, the PPO outperforms both the PO and DAE. Based upon these results, we suggest future application of the PPO to filtering problems in the physical and biological sciences.
AI Accelerator Survey and Trends
Sep 18, 2021
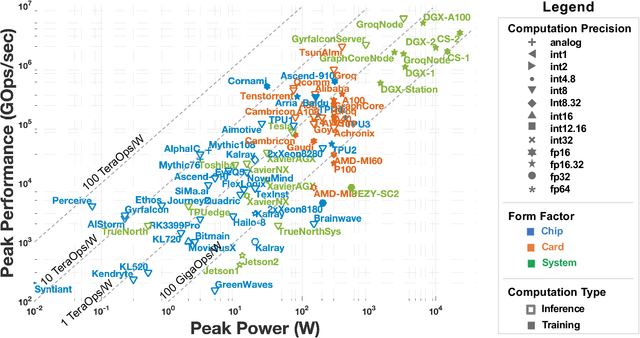
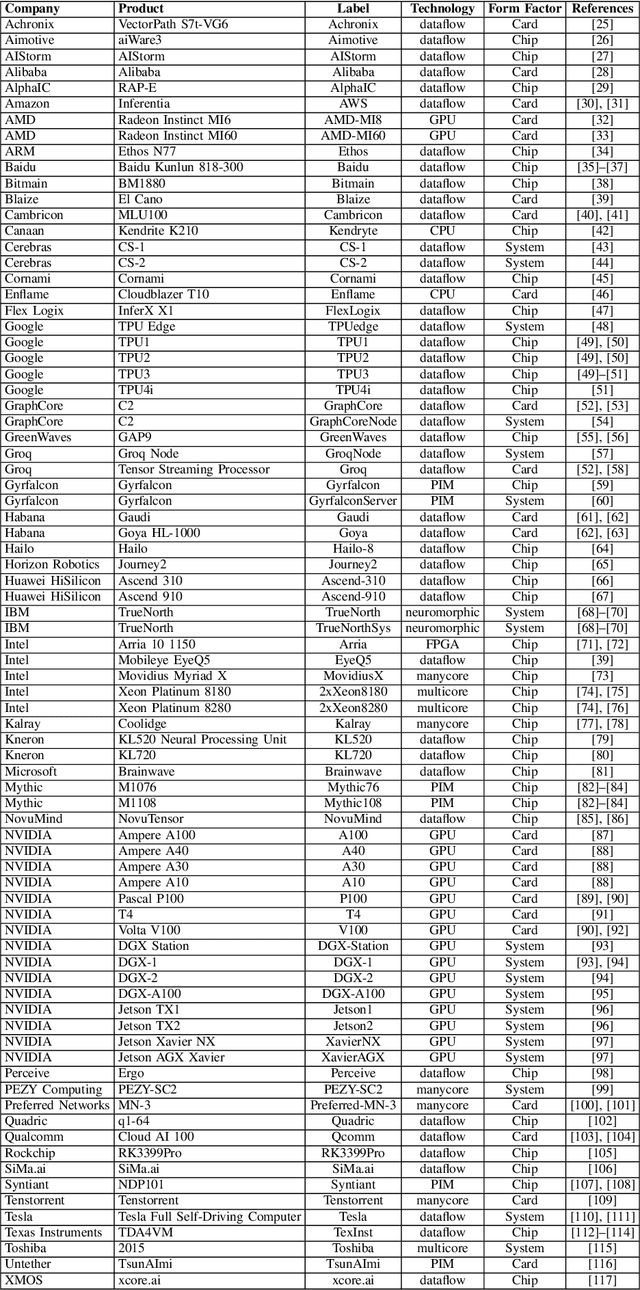
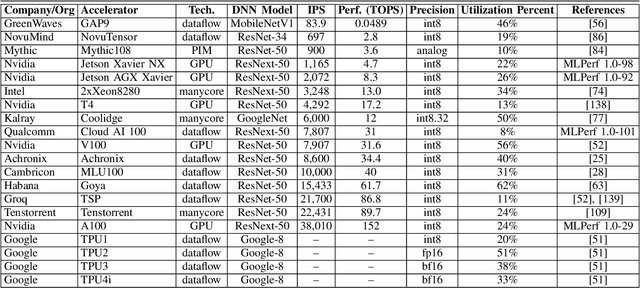
Over the past several years, new machine learning accelerators were being announced and released every month for a variety of applications from speech recognition, video object detection, assisted driving, and many data center applications. This paper updates the survey of AI accelerators and processors from past two years. This paper collects and summarizes the current commercial accelerators that have been publicly announced with peak performance and power consumption numbers. The performance and power values are plotted on a scatter graph, and a number of dimensions and observations from the trends on this plot are again discussed and analyzed. This year, we also compile a list of benchmarking performance results and compute the computational efficiency with respect to peak performance.
The MIT Supercloud Dataset
Aug 04, 2021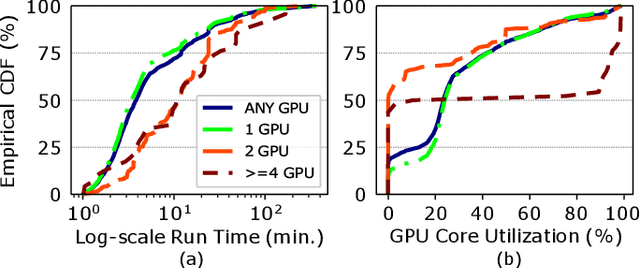
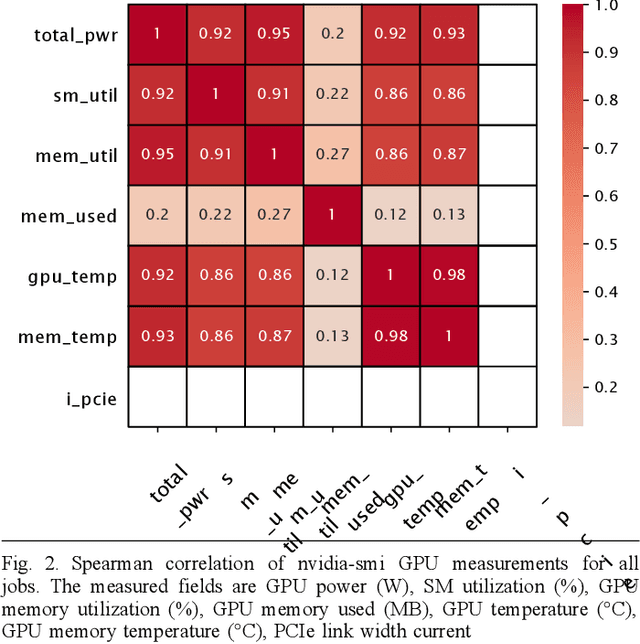
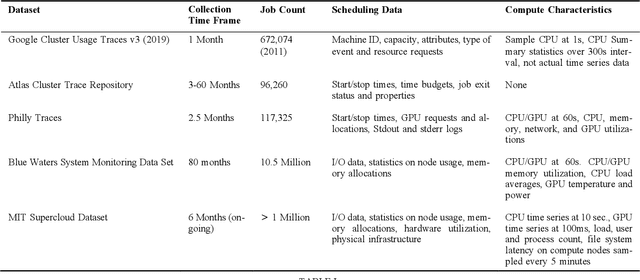

Artificial intelligence (AI) and Machine learning (ML) workloads are an increasingly larger share of the compute workloads in traditional High-Performance Computing (HPC) centers and commercial cloud systems. This has led to changes in deployment approaches of HPC clusters and the commercial cloud, as well as a new focus on approaches to optimized resource usage, allocations and deployment of new AI frame- works, and capabilities such as Jupyter notebooks to enable rapid prototyping and deployment. With these changes, there is a need to better understand cluster/datacenter operations with the goal of developing improved scheduling policies, identifying inefficiencies in resource utilization, energy/power consumption, failure prediction, and identifying policy violations. In this paper we introduce the MIT Supercloud Dataset which aims to foster innovative AI/ML approaches to the analysis of large scale HPC and datacenter/cloud operations. We provide detailed monitoring logs from the MIT Supercloud system, which include CPU and GPU usage by jobs, memory usage, file system logs, and physical monitoring data. This paper discusses the details of the dataset, collection methodology, data availability, and discusses potential challenge problems being developed using this data. Datasets and future challenge announcements will be available via https://dcc.mit.edu.
Survey of Machine Learning Accelerators
Sep 01, 2020
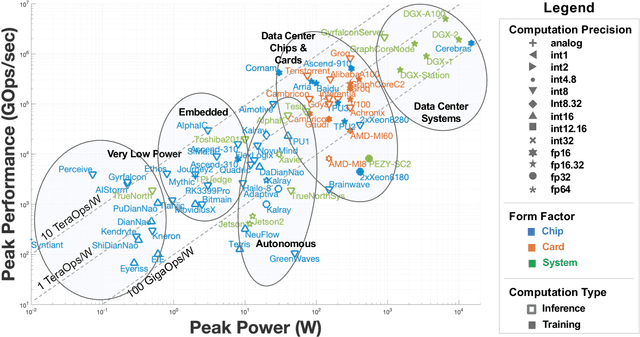
New machine learning accelerators are being announced and released each month for a variety of applications from speech recognition, video object detection, assisted driving, and many data center applications. This paper updates the survey of of AI accelerators and processors from last year's IEEE-HPEC paper. This paper collects and summarizes the current accelerators that have been publicly announced with performance and power consumption numbers. The performance and power values are plotted on a scatter graph and a number of dimensions and observations from the trends on this plot are discussed and analyzed. For instance, there are interesting trends in the plot regarding power consumption, numerical precision, and inference versus training. This year, there are many more announced accelerators that are implemented with many more architectures and technologies from vector engines, dataflow engines, neuromorphic designs, flash-based analog memory processing, and photonic-based processing.
Accuracy and Performance Comparison of Video Action Recognition Approaches
Aug 20, 2020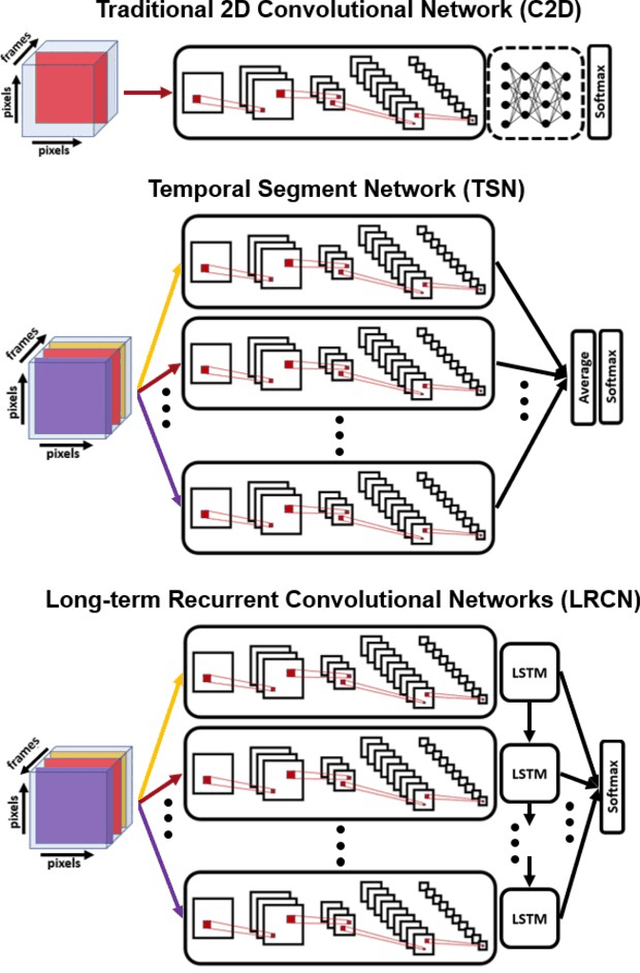
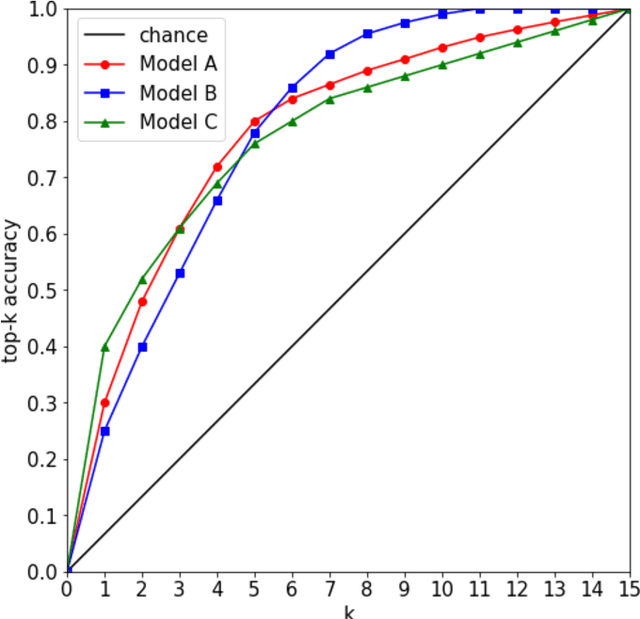
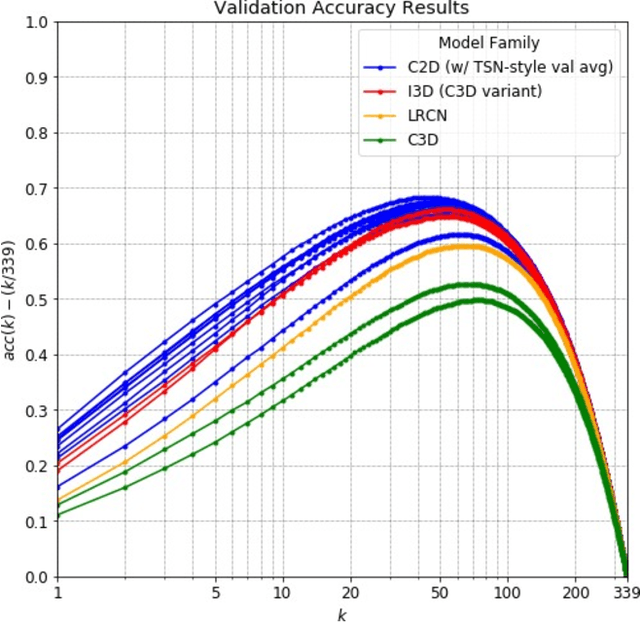
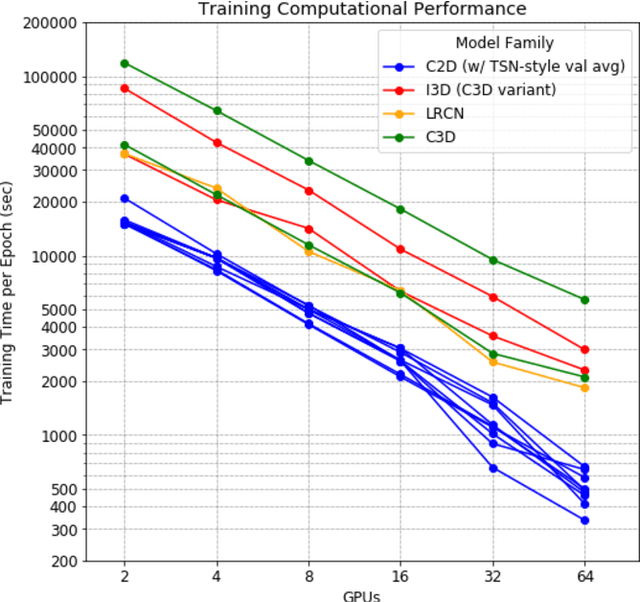
Over the past few years, there has been significant interest in video action recognition systems and models. However, direct comparison of accuracy and computational performance results remain clouded by differing training environments, hardware specifications, hyperparameters, pipelines, and inference methods. This article provides a direct comparison between fourteen off-the-shelf and state-of-the-art models by ensuring consistency in these training characteristics in order to provide readers with a meaningful comparison across different types of video action recognition algorithms. Accuracy of the models is evaluated using standard Top-1 and Top-5 accuracy metrics in addition to a proposed new accuracy metric. Additionally, we compare computational performance of distributed training from two to sixty-four GPUs on a state-of-the-art HPC system.
Compute, Time and Energy Characterization of Encoder-Decoder Networks with Automatic Mixed Precision Training
Aug 18, 2020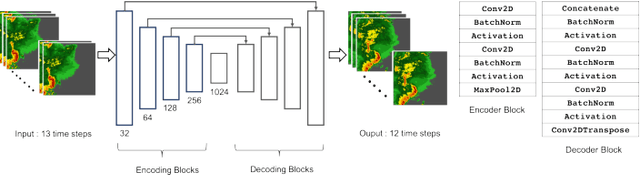
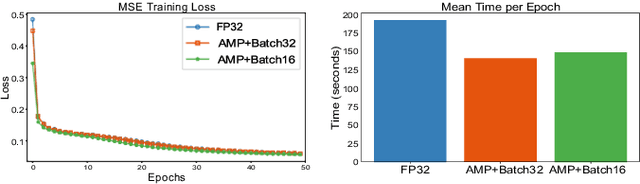
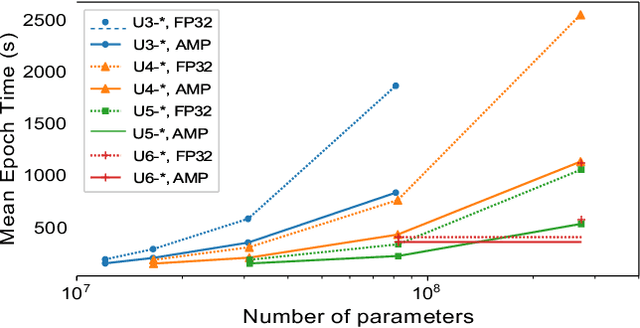
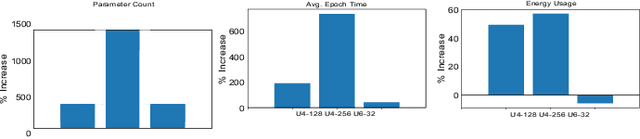
Deep neural networks have shown great success in many diverse fields. The training of these networks can take significant amounts of time, compute and energy. As datasets get larger and models become more complex, the exploration of model architectures becomes prohibitive. In this paper we examine the compute, energy and time costs of training a UNet based deep neural network for the problem of predicting short term weather forecasts (called precipitation Nowcasting). By leveraging a combination of data distributed and mixed-precision training, we explore the design space for this problem. We also show that larger models with better performance come at a potentially incremental cost if appropriate optimizations are used. We show that it is possible to achieve a significant improvement in training time by leveraging mixed-precision training without sacrificing model performance. Additionally, we find that a 1549% increase in the number of trainable parameters for a network comes at a relatively smaller 63.22% increase in energy usage for a UNet with 4 encoding layers.
Benchmarking network fabrics for data distributed training of deep neural networks
Aug 18, 2020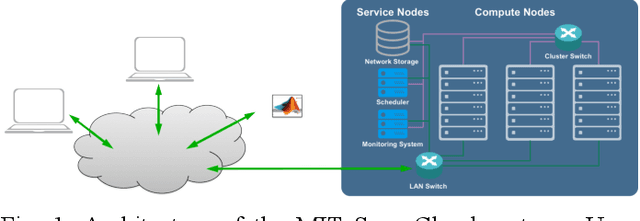
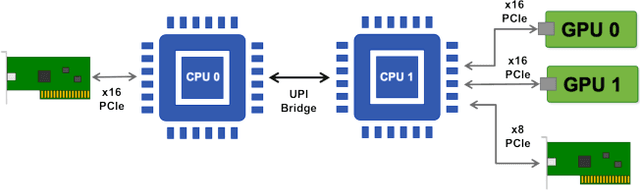
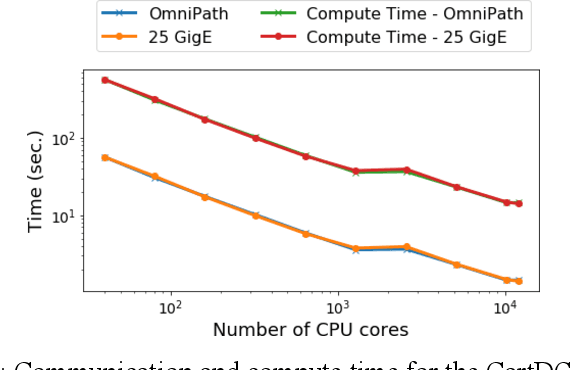

Artificial Intelligence/Machine Learning applications require the training of complex models on large amounts of labelled data. The large computational requirements for training deep models have necessitated the development of new methods for faster training. One such approach is the data parallel approach, where the training data is distributed across multiple compute nodes. This approach is simple to implement and supported by most of the commonly used machine learning frameworks. The data parallel approach leverages MPI for communicating gradients across all nodes. In this paper, we examine the effects of using different physical hardware interconnects and network-related software primitives for enabling data distributed deep learning. We compare the effect of using GPUDirect and NCCL on Ethernet and OmniPath fabrics. Our results show that using Ethernet-based networking in shared HPC systems does not have a significant effect on the training times for commonly used deep neural network architectures or traditional HPC applications such as Computational Fluid Dynamics.