 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosePilot: An Edge-AI Solution for Posture Correction in Physical Exercises
May 25, 2025Automated pose correction remains a significant challenge in AI-driven fitness systems, despite extensive research in activity recognition. This work presents PosePilot, a novel system that integrates pose recognition with real-time personalized corrective feedback, overcoming the limitations of traditional fitness solutions. Using Yoga, a discipline requiring precise spatio-temporal alignment as a case study, we demonstrate PosePilot's ability to analyze complex physical movements. Designed for deployment on edge devices, PosePilot can be extended to various at-home and outdoor exercises. We employ a Vanilla LSTM, allowing the system to capture temporal dependencies for pose recognition. Additionally, a BiLSTM with multi-head Attention enhances the model's ability to process motion contexts, selectively focusing on key limb angles for accurate error detection while maintaining computational efficiency. As part of this work, we introduce a high-quality video dataset used for evaluating our models. Most importantly, PosePilot provides instant corrective feedback at every stage of a movement, ensuring precise posture adjustments throughout the exercise routine. The proposed approach 1) performs automatic human posture recognition, 2) provides personalized posture correction feedback at each instant which is crucial in Yoga, and 3) offers a lightweight and robust posture correction model feasible for deploying on edge devices in real-world environments.
Saliency-guided Emotion Modeling: Predicting Viewer Reactions from Video Stimuli
May 25, 2025Understanding the emotional impact of videos is crucial for applications in content creation, advertising, and Human-Computer Interaction (HCI). Traditional affective computing methods rely on self-reported emotions, facial expression analysis, and biosensing data, yet they often overlook the role of visual saliency -- the naturally attention-grabbing regions within a video. In this study, we utilize deep learning to introduce a novel saliency-based approach to emotion prediction by extracting two key features: saliency area and number of salient regions. Using the HD2S saliency model and OpenFace facial action unit analysis, we examine the relationship between video saliency and viewer emotions. Our findings reveal three key insights: (1) Videos with multiple salient regions tend to elicit high-valence, low-arousal emotions, (2) Videos with a single dominant salient region are more likely to induce low-valence, high-arousal responses, and (3) Self-reported emotions often misalign with facial expression-based emotion detection, suggesting limitations in subjective reporting. By leveraging saliency-driven insights, this work provides a computationally efficient and interpretable alternative for emotion modeling, with implications for content creation, personalized media experiences, and affective computing research.
Driver Hand Localization and Grasp Analysis: A Vision-based Real-time Approach
Feb 22, 2018
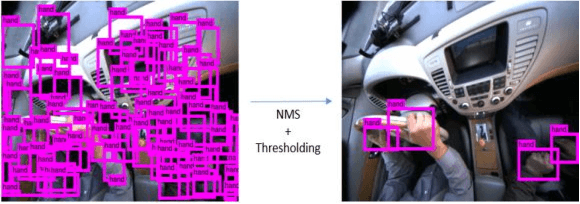
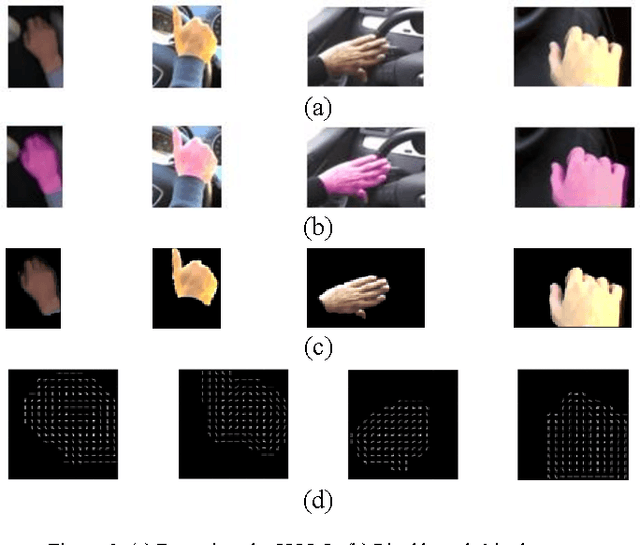

Extracting hand regions and their grasp information from images robustly in real-time is critical for occupants' safety and in-vehicular infotainment applications. It must however, be noted that naturalistic driving scenes suffer from rapidly changing illumination and occlusion. This is aggravated by the fact that hands are highly deformable objects, and change in appearance frequently. This work addresses the task of accurately localizing driver hands and classifying the grasp state of each hand. We use a fast ConvNet to first detect likely hand regions. Next, a pixel-based skin classifier that takes into account the global illumination changes is used to refine the hand detections and remove false positives. This step generates a pixel-level mask for each hand. Finally, we study each such masked regions and detect if the driver is grasping the wheel, or in some cases a mobile phone. Through evaluation we demonstrate that our method can outperform state-of-the-art pixel based hand detectors, while running faster (at 35 fps) than other deep ConvNet based frameworks even for grasp analysis. Hand mask cues are shown to be crucial when analyzing a set of driver hand gestures (wheel/mobile phone grasp and no-grasp) in naturalistic driving settings. The proposed detection and localization pipeline hence can act as a general framework for real-time hand detection and gesture classification.