 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Federated Multi-View Learning for Private Medical Data Integration and Analysis
May 04, 2021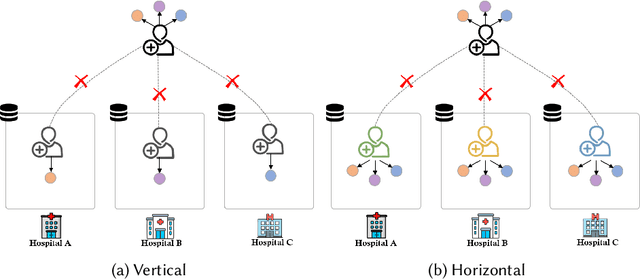
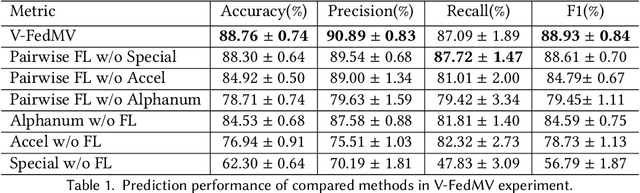
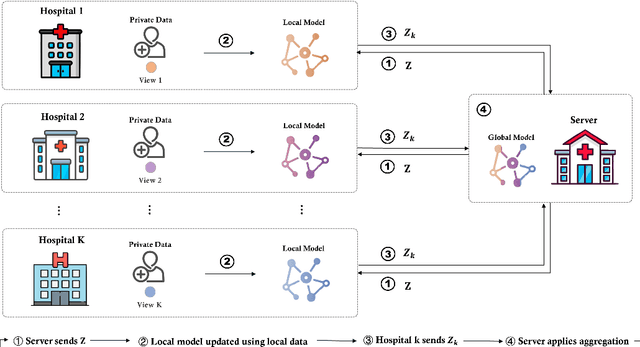
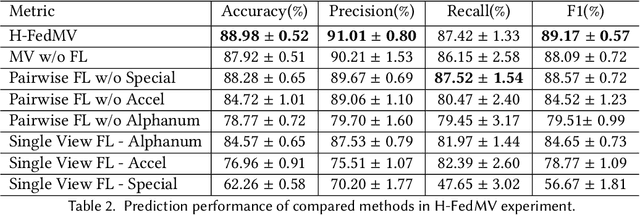
Along with the rapid expansion of information technology and digitalization of health data, there is an increasing concern on maintaining data privacy while garnering the benefits in medical field. Two critical challenges are identified: Firstly, medical data is naturally distributed across multiple local sites, making it difficult to collectively train machine learning models without data leakage. Secondly, in medical applications, data are often collected from different sources and views, resulting in heterogeneity and complexity that requires reconciliation. This paper aims to provide a generic Federated Multi-View Learning (FedMV) framework for multi-view data leakage prevention, which is based on different types of local data availability and enables to accommodate two types of problems: Vertical Federated Multi-View Learning (V-FedMV) and Horizontal Federated Multi-View Learning (H-FedMV). We experimented with real-world keyboard data collected from BiAffect study. The results demonstrated that the proposed FedMV approach can make full use of multi-view data in a privacy-preserving way, and both V-FedMV and H-FedMV methods perform better than their single-view and pairwise counterparts. Besides, the proposed model can be easily adapted to deal with multi-view sequential data in a federated environment, which has been modeled and experimentally studied. To the best of our knowledge, this framework is the first to consider both vertical and horizontal diversification in the multi-view setting, as well as their sequential federated learning.