 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-Driven Amodal Completion: Collaborative Agents and Perceptual Evaluation
Dec 24, 2025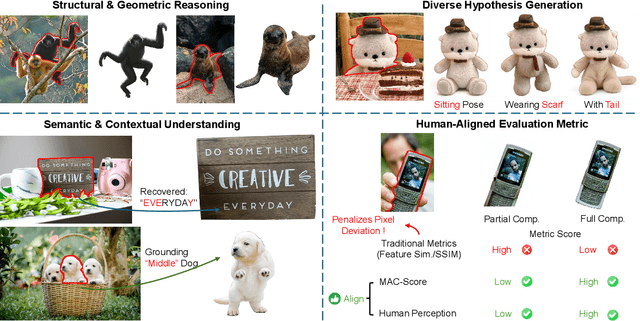

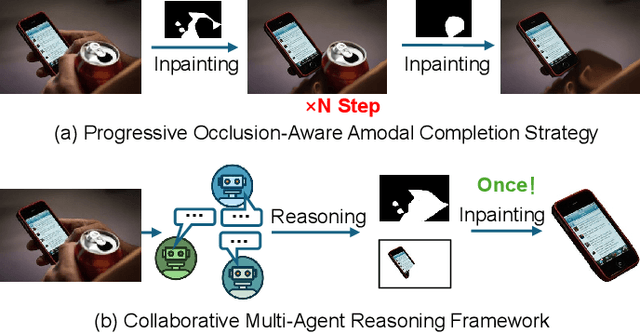
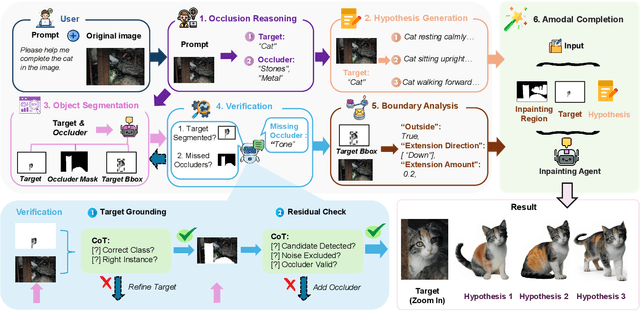
Amodal completion, the task of inferring invisible object parts, faces significant challenges in maintaining semantic consistency and structural integrity. Prior progressive approaches are inherently limited by inference instability and error accumulation. To tackle these limitations, we present a Collaborative Multi-Agent Reasoning Framework that explicitly decouples Semantic Planning from Visual Synthesis. By employing specialized agents for upfront reasoning, our method generates a structured, explicit plan before pixel generation, enabling visually and semantically coherent single-pass synthesis. We integrate this framework with two critical mechanisms: (1) a self-correcting Verification Agent that employs Chain-of-Thought reasoning to rectify visible region segmentation and identify residual occluders strictly within the Semantic Planning phase, and (2) a Diverse Hypothesis Generator that addresses the ambiguity of invisible regions by offering diverse, plausible semantic interpretations, surpassing the limited pixel-level variations of standard random seed sampling. Furthermore, addressing the limitations of traditional metrics in assessing inferred invisible content, we introduce the MAC-Score (MLLM Amodal Completion Score), a novel human-aligned evaluation metric. Validated against human judgment and ground truth, these metrics establish a robust standard for assessing structural completeness and semantic consistency with visible context. Extensive experiments demonstrate that our framework significantly outperforms state-of-the-art methods across multiple datasets. Our project is available at: https://fanhongxing.github.io/remac-page.
Long-term Cross Adversarial Training: A Robust Meta-learning Method for Few-shot Classification Tasks
Jul 01, 2021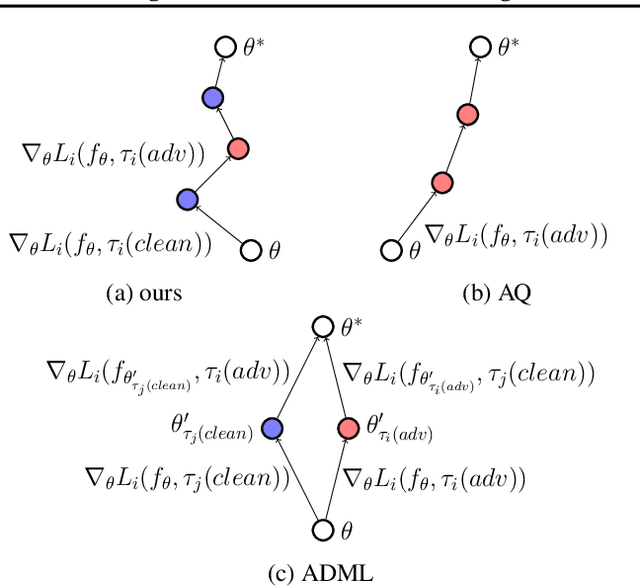

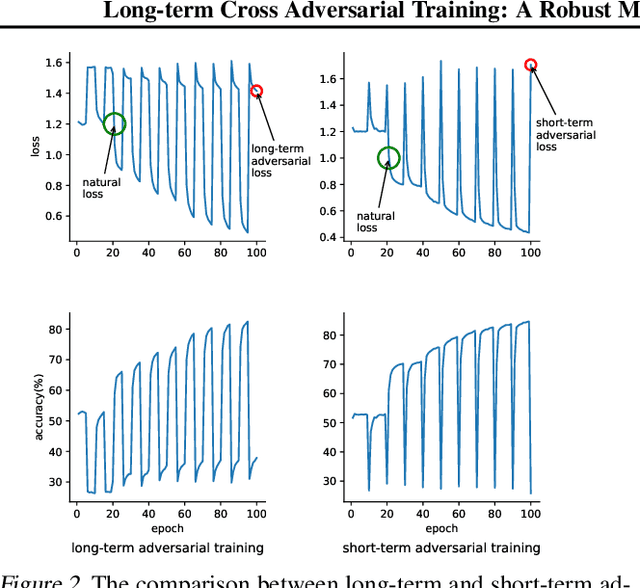
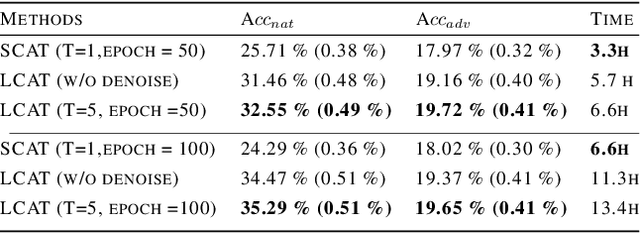
Meta-learning model can quickly adapt to new tasks using few-shot labeled data. However, despite achieving good generalization on few-shot classification tasks, it is still challenging to improve the adversarial robustness of the meta-learning model in few-shot learning. Although adversarial training (AT) methods such as Adversarial Query (AQ) can improve the adversarially robust performance of meta-learning models, AT is still computationally expensive training. On the other hand, meta-learning models trained with AT will drop significant accuracy on the original clean images. This paper proposed a meta-learning method on the adversarially robust neural network called Long-term Cross Adversarial Training (LCAT). LCAT will update meta-learning model parameters cross along the natural and adversarial sample distribution direction with long-term to improve both adversarial and clean few-shot classification accuracy. Due to cross-adversarial training, LCAT only needs half of the adversarial training epoch than AQ, resulting in a low adversarial training computation. Experiment results show that LCAT achieves superior performance both on the clean and adversarial few-shot classification accuracy than SOTA adversarial training methods for meta-learning models.