 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Transfer Learning with Ridge Regression
Jun 11, 2020
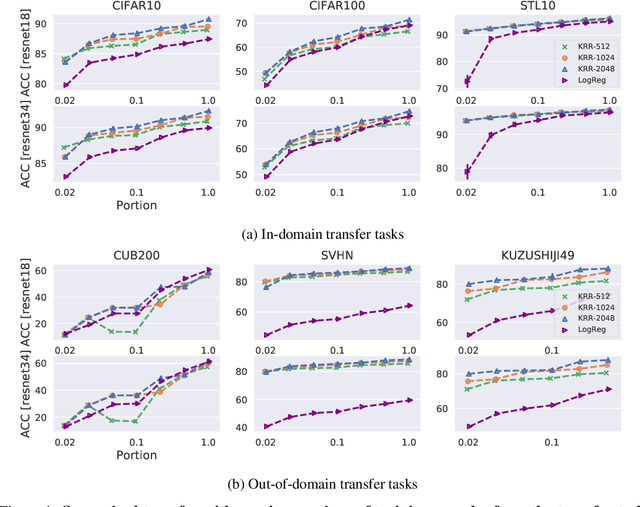

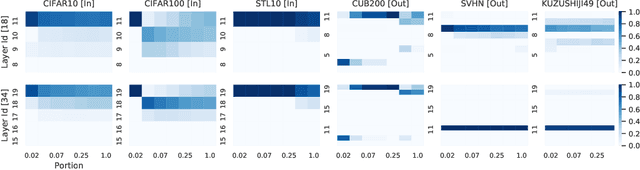
The large amount of online data and vast array of computing resources enable current researchers in both industry and academia to employ the power of deep learning with neural networks. While deep models trained with massive amounts of data demonstrate promising generalisation ability on unseen data from relevant domains, the computational cost of finetuning gradually becomes a bottleneck in transfering the learning to new domains. We address this issue by leveraging the low-rank property of learnt feature vectors produced from deep neural networks (DNNs) with the closed-form solution provided in kernel ridge regression (KRR). This frees transfer learning from finetuning and replaces it with an ensemble of linear systems with many fewer hyperparameters. Our method is successful on supervised and semi-supervised transfer learning tasks.
Similarity of Neural Networks with Gradients
Mar 25, 2020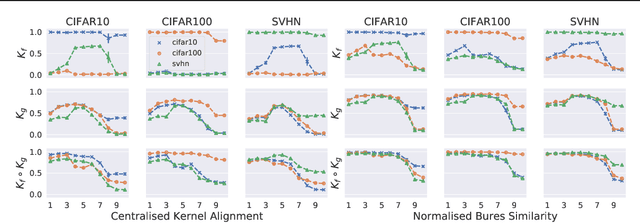
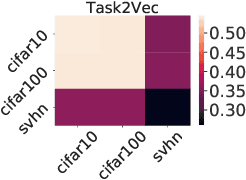
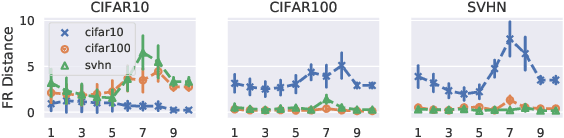
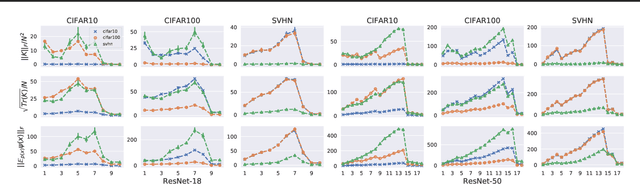
A suitable similarity index for comparing learnt neural networks plays an important role in understanding the behaviour of the highly-nonlinear functions, and can provide insights on further theoretical analysis and empirical studies. We define two key steps when comparing models: firstly, the representation abstracted from the learnt model, where we propose to leverage both feature vectors and gradient ones (which are largely ignored in prior work) into designing the representation of a neural network. Secondly, we define the employed similarity index which gives desired invariance properties, and we facilitate the chosen ones with sketching techniques for comparing various datasets efficiently. Empirically, we show that the proposed approach provides a state-of-the-art method for computing similarity of neural networks that are trained independently on different datasets and the tasks defined by the datasets.
Improving Style Transfer with Calibrated Metrics
Oct 21, 2019
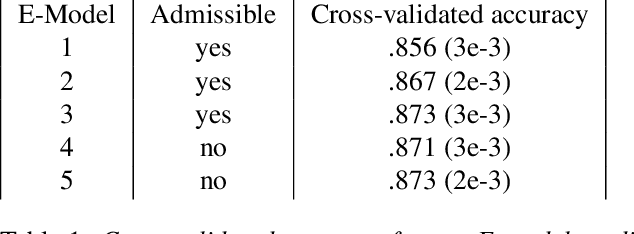


Style transfer methods produce a transferred image which is a rendering of a content image in the manner of a style image. We seek to understand how to improve style transfer. To do so requires quantitative evaluation procedures, but the current evaluation is qualitative, mostly involving user studies. We describe a novel quantitative evaluation procedure. Our procedure relies on two statistics: the Effectiveness (E) statistic measures the extent that a given style has been transferred to the target, and the Coherence (C) statistic measures the extent to which the original image's content is preserved. Our statistics are calibrated to human preference: targets with larger values of E (resp C) will reliably be preferred by human subjects in comparisons of style (resp. content). We use these statistics to investigate the relative performance of a number of Neural Style Transfer(NST) methods, revealing several intriguing properties. Admissible methods lie on a Pareto frontier (i.e. improving E reduces C or vice versa). Three methods are admissible: Universal style transfer produces very good C but weak E; modifying the optimization used for Gatys' loss produces a method with strong E and strong C; and a modified cross-layer method has slightly better E at strong cost in C. While the histogram loss improves the E statistics of Gatys' method, it does not make the method admissible. Surprisingly, style weights have relatively little effect in improving EC scores, and most variability in the transfer is explained by the style itself (meaning experimenters can be misguided by selecting styles).
An Empirical Study on Post-processing Methods for Word Embeddings
May 28, 2019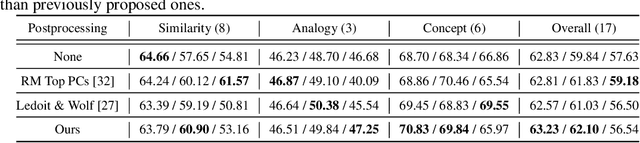
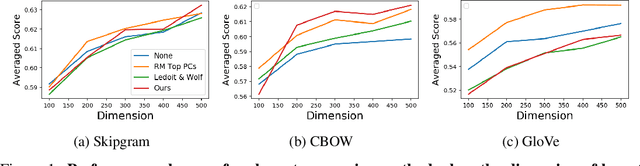
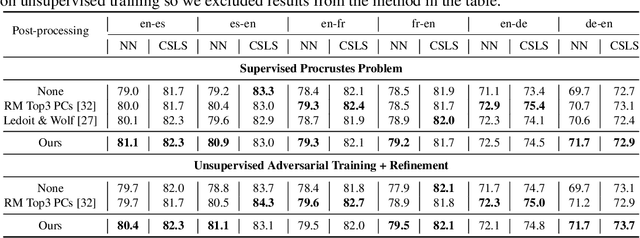
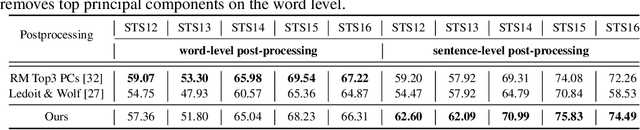
Word embeddings learnt from large corpora have been adopted in various applications in natural language processing and served as the general input representations to learning systems. Recently, a series of post-processing methods have been proposed to boost the performance of word embeddings on similarity comparison and analogy retrieval tasks, and some have been adapted to compose sentence representations. The general hypothesis behind these methods is that by enforcing the embedding space to be more isotropic, the similarity between words can be better expressed. We view these methods as an approach to shrink the covariance/gram matrix, which is estimated by learning word vectors, towards a scaled identity matrix. By optimising an objective in the semi-Riemannian manifold with Centralised Kernel Alignment (CKA), we are able to search for the optimal shrinkage parameter, and provide a post-processing method to smooth the spectrum of learnt word vectors which yields improved performance on downstream tasks.
Learning Distributed Representations of Symbolic Structure Using Binding and Unbinding Operations
Nov 03, 2018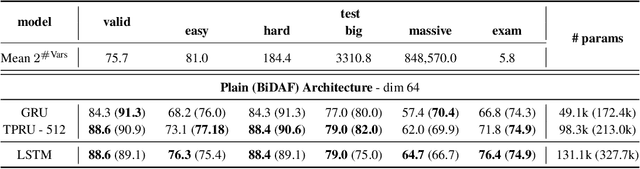
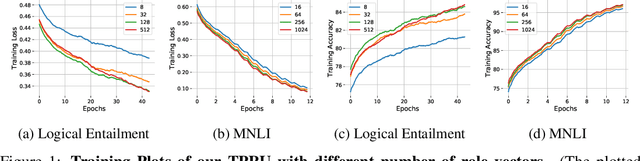
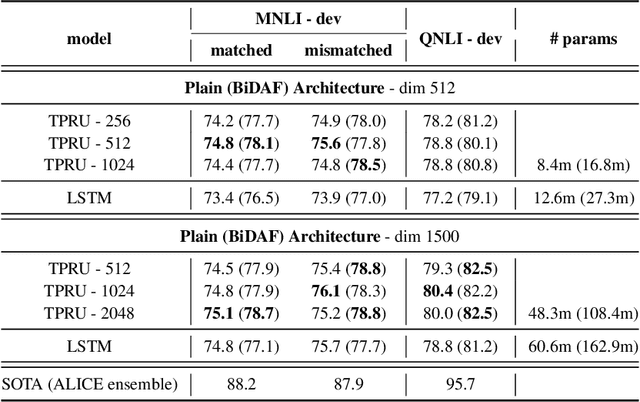
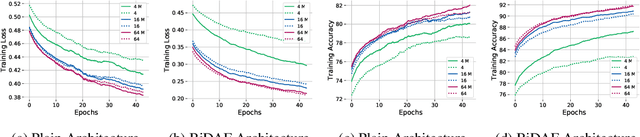
Widely used recurrent units, including Long-short Term Memory (LSTM) and Gated Recurrent Unit (GRU), perform well on natural language tasks, but their ability to learn structured representations is still questionable. Exploiting Tensor Product Representations (TPRs) --- distributed representations of symbolic structure in which vector-embedded symbols are bound to vector-embedded structural positions --- we propose the TPRU, a recurrent unit that, at each time step, explicitly executes structural-role binding and unbinding operations to incorporate structural information into learning. Experiments are conducted on both the Logical Entailment task and the Multi-genre Natural Language Inference (MNLI) task, and our TPR-derived recurrent unit provides strong performance with significantly fewer parameters than LSTM and GRU baselines. Furthermore, our learnt TPRU trained on MNLI demonstrates solid generalisation ability on downstream tasks.
Improving Sentence Representations with Multi-view Frameworks
Oct 02, 2018
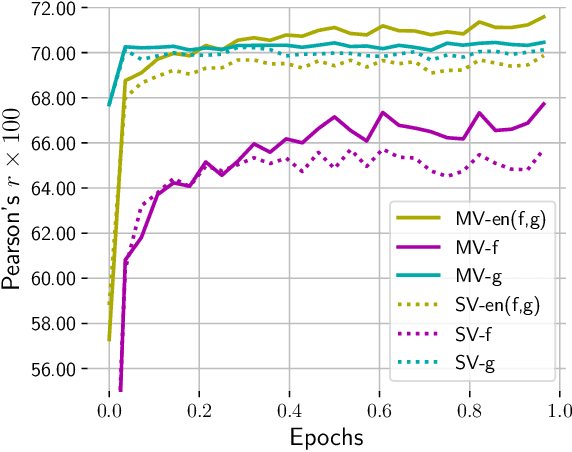
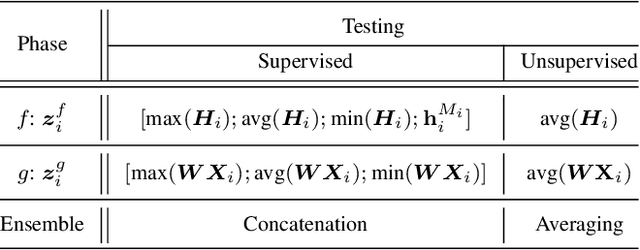
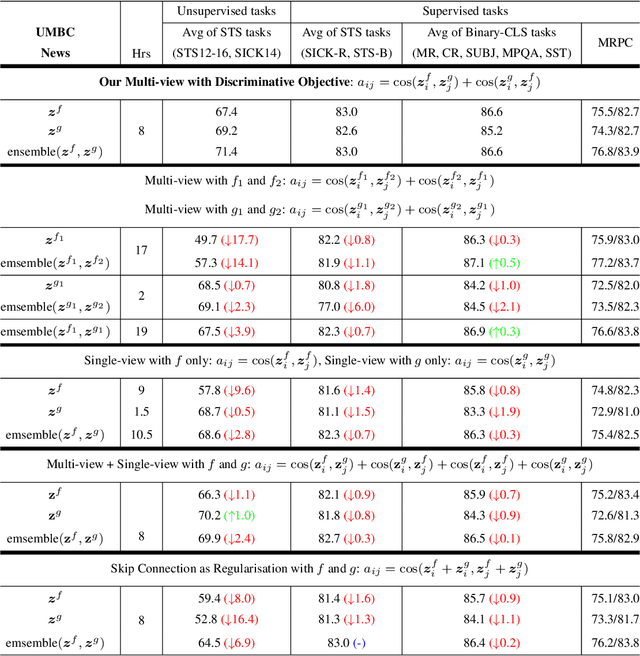
Multi-view learning can provide self-supervision when different views are available of the same data. Distributional hypothesis provides another form of useful self-supervision from adjacent sentences which are plentiful in large unlabelled corpora. Motivated by the asymmetry in the two hemispheres of the human brain as well as the observation that different learning architectures tend to emphasise different aspects of sentence meaning, we present two multi-view frameworks for learning sentence representations in an unsupervised fashion. One framework uses a generative objective and the other a discriminative one. In both frameworks, the final representation is an ensemble of two views, in which, one view encodes the input sentence with a Recurrent Neural Network (RNN), and the other view encodes it with a simple linear model. We show that, after learning, the vectors produced by our multi-view frameworks provide improved representations over their single-view learned counterparts, and the combination of different views gives representational improvement over each view and demonstrates solid transferability on standard downstream tasks.
Exploiting Invertible Decoders for Unsupervised Sentence Representation Learning
Sep 08, 2018
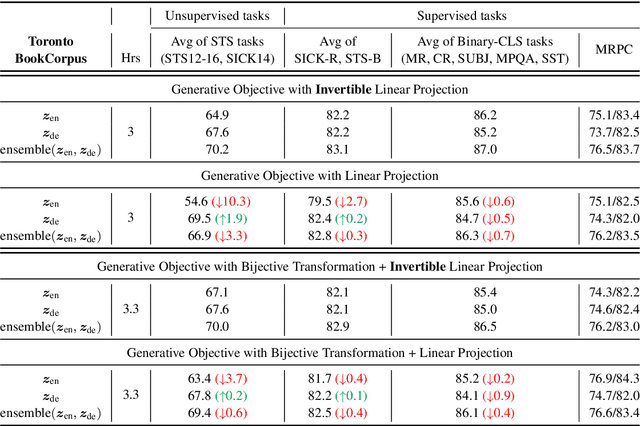
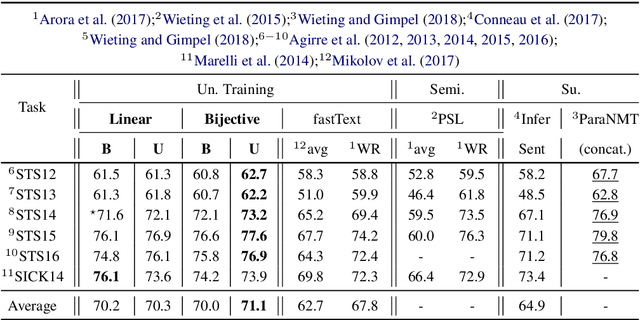
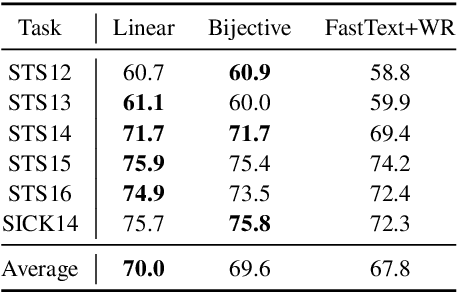
The encoder-decoder models for unsupervised sentence representation learning tend to discard the decoder after being trained on a large unlabelled corpus, since only the encoder is needed to map the input sentence into a vector representation. However, parameters learnt in the decoder also contain useful information about language. In order to utilise the decoder after learning, we present two types of decoding functions whose inverse can be easily derived without expensive inverse calculation. Therefore, the inverse of the decoding function serves as another encoder that produces sentence representations. We show that, with careful design of the decoding functions, the model learns good sentence representations, and the ensemble of the representations produced from the encoder and the inverse of the decoder demonstrate even better generalisation ability and solid transferability.
Speeding up Context-based Sentence Representation Learning with Non-autoregressive Convolutional Decoding
Jun 01, 2018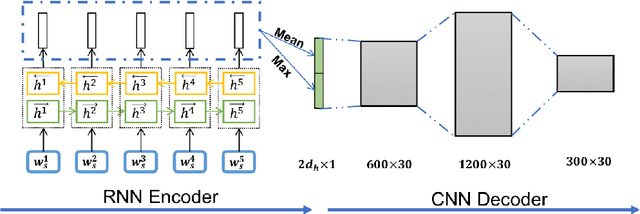
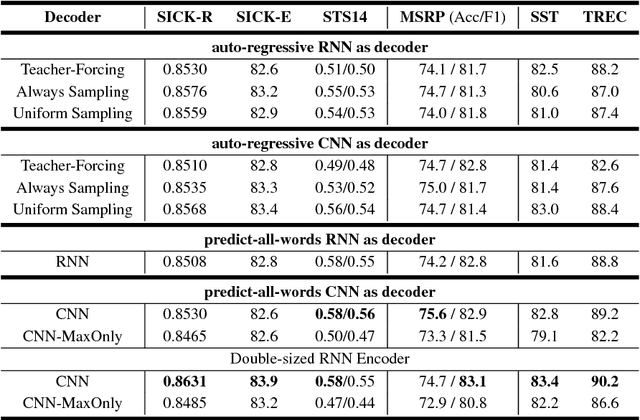
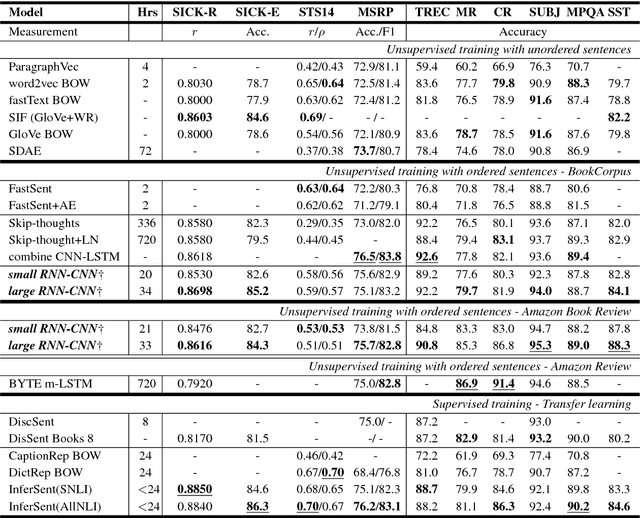
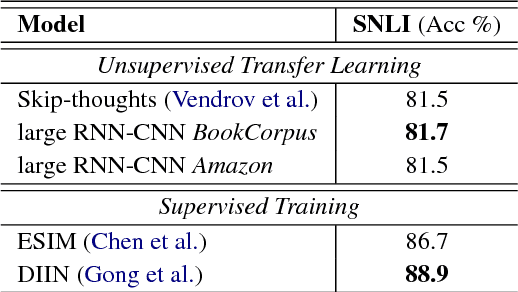
Context plays an important role in human language understanding, thus it may also be useful for machines learning vector representations of language. In this paper, we explore an asymmetric encoder-decoder structure for unsupervised context-based sentence representation learning. We carefully designed experiments to show that neither an autoregressive decoder nor an RNN decoder is required. After that, we designed a model which still keeps an RNN as the encoder, while using a non-autoregressive convolutional decoder. We further combine a suite of effective designs to significantly improve model efficiency while also achieving better performance. Our model is trained on two different large unlabelled corpora, and in both cases the transferability is evaluated on a set of downstream NLP tasks. We empirically show that our model is simple and fast while producing rich sentence representations that excel in downstream tasks.
Multi-view Sentence Representation Learning
May 18, 2018
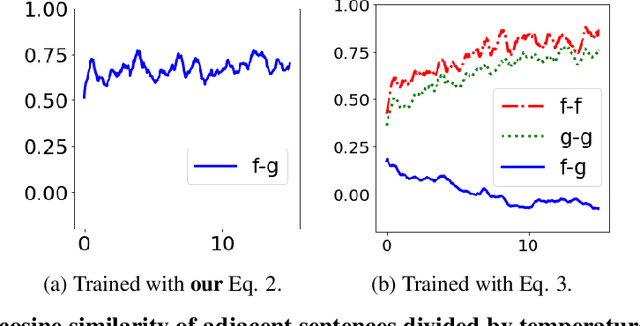
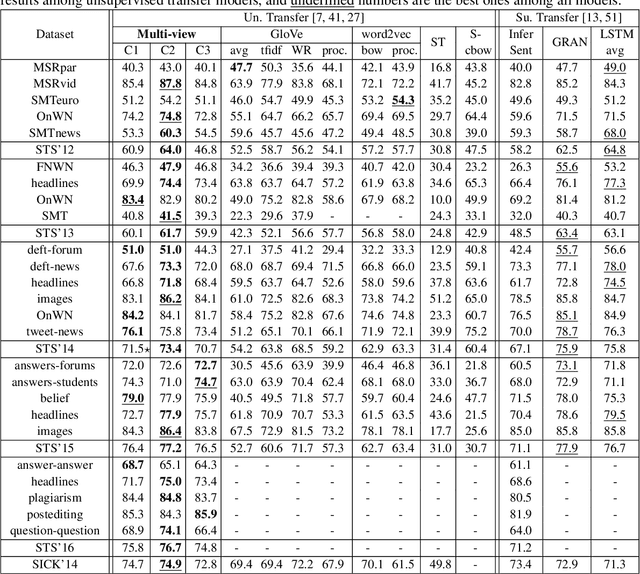

Multi-view learning can provide self-supervision when different views are available of the same data. The distributional hypothesis provides another form of useful self-supervision from adjacent sentences which are plentiful in large unlabelled corpora. Motivated by the asymmetry in the two hemispheres of the human brain as well as the observation that different learning architectures tend to emphasise different aspects of sentence meaning, we create a unified multi-view sentence representation learning framework, in which, one view encodes the input sentence with a Recurrent Neural Network (RNN), and the other view encodes it with a simple linear model, and the training objective is to maximise the agreement specified by the adjacent context information between two views. We show that, after training, the vectors produced from our multi-view training provide improved representations over the single-view training, and the combination of different views gives further representational improvement and demonstrates solid transferability on standard downstream tasks.
Quantitative Evaluation of Style Transfer
Mar 31, 2018

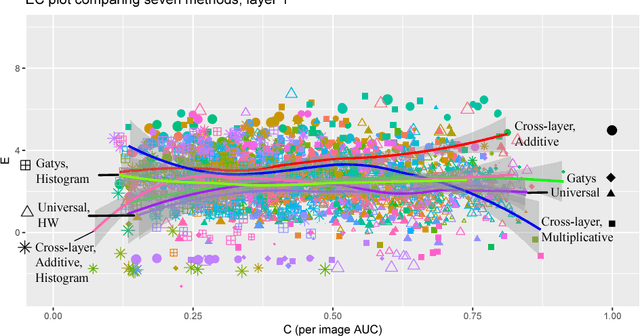
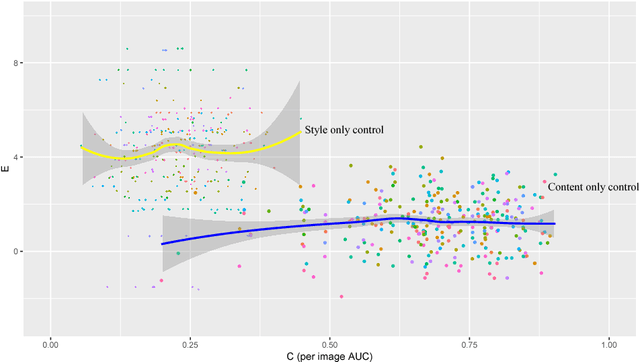
Style transfer methods produce a transferred image which is a rendering of a content image in the manner of a style image. There is a rich literature of variant methods. However, evaluation procedures are qualitative, mostly involving user studies. We describe a novel quantitative evaluation procedure. One plots effectiveness (a measure of the extent to which the style was transferred) against coherence (a measure of the extent to which the transferred image decomposes into objects in the same way that the content image does) to obtain an EC plot. We construct EC plots comparing a number of recent style transfer methods. Most methods control within-layer gram matrices, but we also investigate a method that controls cross-layer gram matrices. These EC plots reveal a number of intriguing properties of recent style transfer methods. The style used has a strong effect on the outcome, for all methods. Using large style weights does not necessarily improve effectiveness, and can produce worse results. Cross-layer gram matrices easily beat all other methods, but some styles remain difficult for all methods. Ensemble methods show real promise. It is likely that, for current methods, each style requires a different choice of weights to obtain the best results, so that automated weight setting methods are desirable. Finally, we show evidence comparing our EC evaluations to human evaluations.