 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2I-Eval-R1: Reinforcement Learning-Driven Reasoning for Interpretable Text-to-Image Evaluation
May 23, 2025The rapid progress in diffusion-based text-to-image (T2I) generation has created an urgent need for interpretable automatic evaluation methods that can assess the quality of generated images, therefore reducing the human annotation burden. To reduce the prohibitive cost of relying on commercial models for large-scale evaluation, and to improve the reasoning capabilities of open-source models, recent research has explored supervised fine-tuning (SFT) of multimodal large language models (MLLMs) as dedicated T2I evaluators. However, SFT approaches typically rely on high-quality critique datasets, which are either generated by proprietary LLMs-with potential issues of bias and inconsistency-or annotated by humans at high cost, limiting their scalability and generalization. To address these limitations, we propose T2I-Eval-R1, a novel reinforcement learning framework that trains open-source MLLMs using only coarse-grained quality scores, thereby avoiding the need for annotating high-quality interpretable evaluation rationale. Our approach integrates Group Relative Policy Optimization (GRPO) into the instruction-tuning process, enabling models to generate both scalar scores and interpretable reasoning chains with only easy accessible annotated judgment scores or preferences. Furthermore, we introduce a continuous reward formulation that encourages score diversity and provides stable optimization signals, leading to more robust and discriminative evaluation behavior. Experimental results on three established T2I meta-evaluation benchmarks demonstrate that T2I-Eval-R1 achieves significantly higher alignment with human assessments and offers more accurate interpretable score rationales compared to strong baseline methods.
Hammer PDF: An Intelligent PDF Reader for Scientific Papers
Apr 06, 2022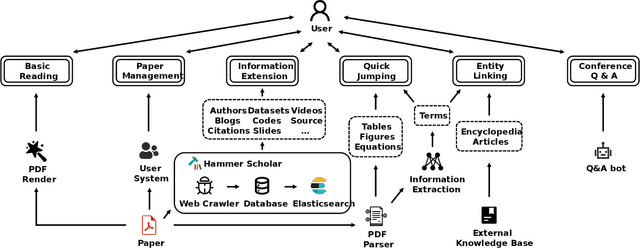
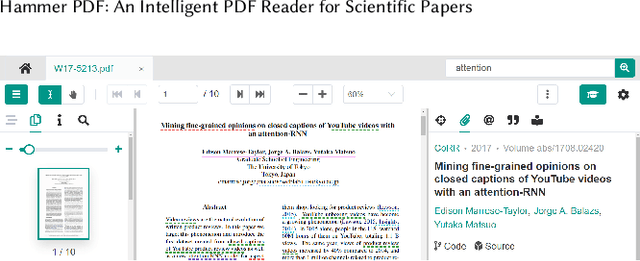


Reading scientific papers has been an essential way for researchers to acquire academic knowledge, and most papers are in PDF format. However, existing PDF Readers only support reading, editing, annotating and other basic functions, and lack of multi-granularity analysis for academic papers. Specifically, taking a paper as a whole, these PDF Readers cannot access extended information of the paper, such as related videos, blogs, codes, etc.; meanwhile, for the content of a paper, these PDF Readers also cannot extract and display academic details of the paper, such as terms, authors, citations, etc. In this paper, we introduce Hammer PDF, a novel intelligent PDF Reader for scientific papers. Beyond basic reading functions, Hammer PDF comes with four innovative features: (1) locate, mark and interact with spans (e.g., terms) obtained by information extraction; (2) citation, reference, code, video, blog, and other extended information are displayed with a paper; (3) built-in Hammer Scholar, an academic search engine that uses academic information collected from major academic databases; (4) built-in Q\&A bot to support asking for interested conference information. Our product helps researchers, especially those who study computer science, to improve the efficiency and experience of reading scientific papers. We release Hammer PDF, available for download at https://pdf.hammerscholar.net/face.