 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Human Activity Recognition Through Ranking and Re-ranking
Dec 11, 2015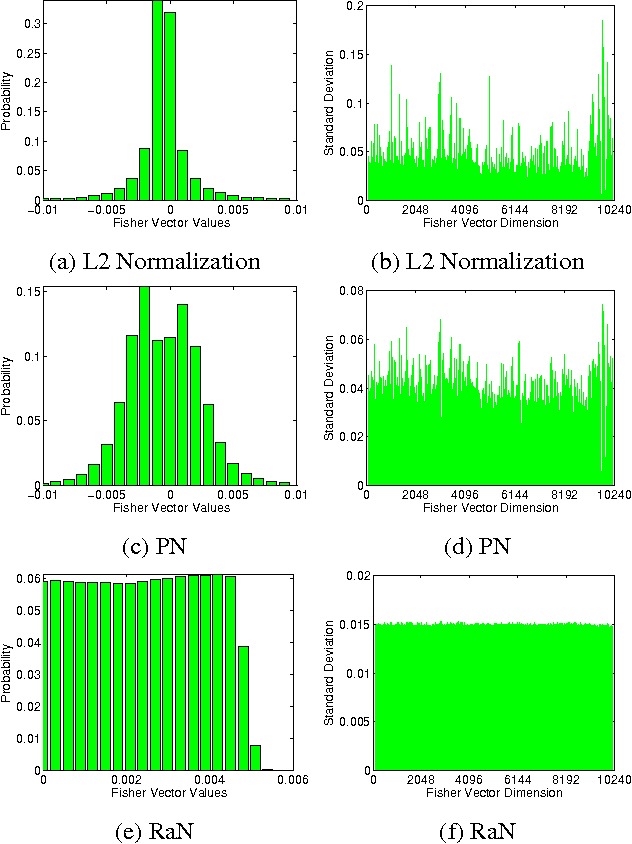
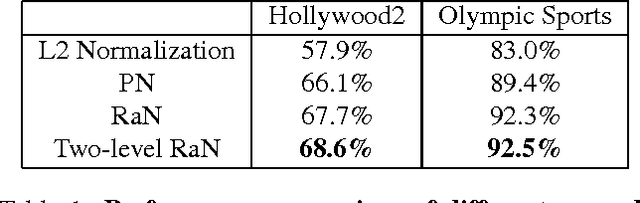
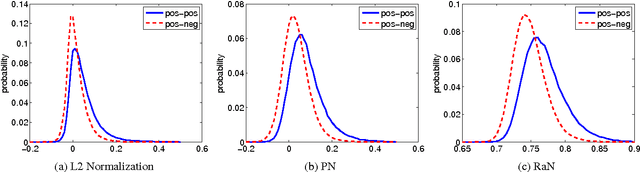
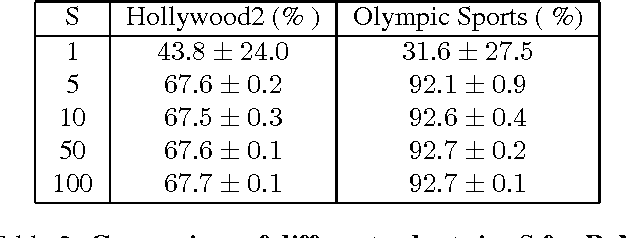
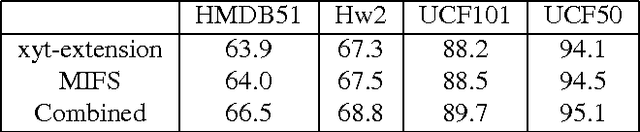
We propose two well-motivated ranking-based methods to enhance the performance of current state-of-the-art human activity recognition systems. First, as an improvement over the classic power normalization method, we propose a parameter-free ranking technique called rank normalization (RaN). RaN normalizes each dimension of the video features to address the sparse and bursty distribution problems of Fisher Vectors and VLAD. Second, inspired by curriculum learning, we introduce a training-free re-ranking technique called multi-class iterative re-ranking (MIR). MIR captures relationships among action classes by separating easy and typical videos from difficult ones and re-ranking the prediction scores of classifiers accordingly. We demonstrate that our methods significantly improve the performance of state-of-the-art motion features on six real-world datasets.
Handcrafted Local Features are Convolutional Neural Networks
Nov 19, 2015



Image and video classification research has made great progress through the development of handcrafted local features and learning based features. These two architectures were proposed roughly at the same time and have flourished at overlapping stages of history. However, they are typically viewed as distinct approaches. In this paper, we emphasize their structural similarities and show how such a unified view helps us in designing features that balance efficiency and effectiveness. As an example, we study the problem of designing efficient video feature learning algorithms for action recognition. We approach this problem by first showing that local handcrafted features and Convolutional Neural Networks (CNNs) share the same convolution-pooling network structure. We then propose a two-stream Convolutional ISA (ConvISA) that adopts the convolution-pooling structure of the state-of-the-art handcrafted video feature with greater modeling capacities and a cost-effective training algorithm. Through custom designed network structures for pixels and optical flow, our method also reflects distinctive characteristics of these two data sources. Our experimental results on standard action recognition benchmarks show that by focusing on the structure of CNNs, rather than end-to-end training methods, we are able to design an efficient and powerful video feature learning algorithm.
The Best of Both Worlds: Combining Data-independent and Data-driven Approaches for Action Recognition
May 17, 2015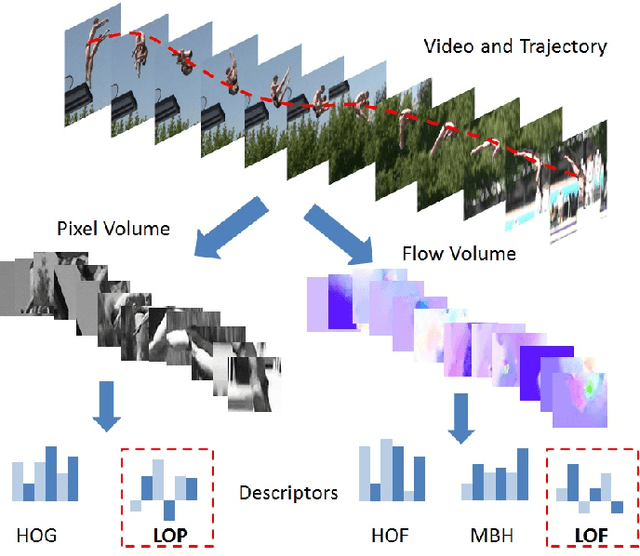
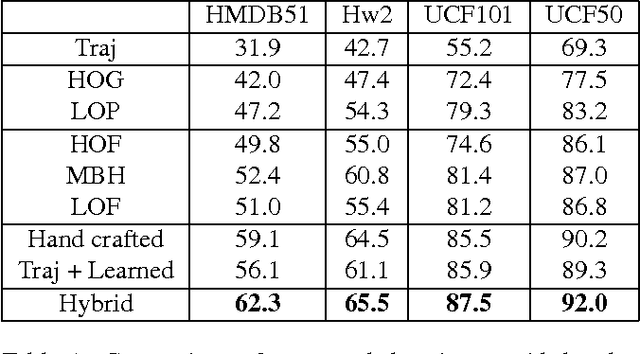

Motivated by the success of data-driven convolutional neural networks (CNNs) in object recognition on static images, researchers are working hard towards developing CNN equivalents for learning video features. However, learning video features globally has proven to be quite a challenge due to its high dimensionality, the lack of labelled data and the difficulty in processing large-scale video data. Therefore, we propose to leverage effective techniques from both data-driven and data-independent approaches to improve action recognition system. Our contribution is three-fold. First, we propose a two-stream Stacked Convolutional Independent Subspace Analysis (ConvISA) architecture to show that unsupervised learning methods can significantly boost the performance of traditional local features extracted from data-independent models. Second, we demonstrate that by learning on video volumes detected by Improved Dense Trajectory (IDT), we can seamlessly combine our novel local descriptors with hand-crafted descriptors. Thus we can utilize available feature enhancing techniques developed for hand-crafted descriptors. Finally, similar to multi-class classification framework in CNNs, we propose a training-free re-ranking technique that exploits the relationship among action classes to improve the overall performance. Our experimental results on four benchmark action recognition datasets show significantly improved performance.