 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Morph: Human Motion Priors for Scalable Robot Learning Across Morphologies
Jun 29, 2026Recent progress in humanoid behavior models has been driven in large part by abundant human motion data, but comparable motion data is scarce for non-humanoid legged robots such as quadrupeds, hexapods, and quadruped manipulators. A promising alternative is to repurpose human motion across embodiments; however, direct retargeting often produces motions that are visually plausible yet physically inconsistent or difficult to track under robot dynamics. We present X-Morph, a human-motion-to-robot-behavior pipeline that converts human motion into deployable locomotion and loco-manipulation policies for diverse non-humanoid legged morphologies. A cross-morphology retargeting stage converts human motions into kinematically plausible, intent-preserving robot references, which are then tracked by a privileged RL policy and distilled into a causal student policy. We evaluate X-Morph on three morphologically distinct platforms: a quadruped, a hexapod, and a quadruped equipped with a manipulator. The resulting policies track diverse retargeted motions, generalize to unseen human motions, and support downstream use cases including video-based teleoperation, behavior-prior control, and text-conditioned motion generation. These results suggest that large-scale human motion can serve as a substrate for learning broad, reusable behavior priors beyond humanoid robots. Project page: https://maker-rat.github.io/morph/
APEX: Action Priors Enable Efficient Exploration for Skill Imitation on Articulated Robots
May 15, 2025Learning by imitation provides an effective way for robots to develop well-regulated complex behaviors and directly benefit from natural demonstrations. State-of-the-art imitation learning (IL) approaches typically leverage Adversarial Motion Priors (AMP), which, despite their impressive results, suffer from two key limitations. They are prone to mode collapse, which often leads to overfitting to the simulation environment and thus increased sim-to-real gap, and they struggle to learn diverse behaviors effectively. To overcome these limitations, we introduce APEX (Action Priors enable Efficient eXploration): a simple yet versatile imitation learning framework that integrates demonstrations directly into reinforcement learning (RL), maintaining high exploration while grounding behavior with expert-informed priors. We achieve this through a combination of decaying action priors, which initially bias exploration toward expert demonstrations but gradually allow the policy to explore independently. This is complemented by a multi-critic RL framework that effectively balances stylistic consistency with task performance. Our approach achieves sample-efficient imitation learning and enables the acquisition of diverse skills within a single policy. APEX generalizes to varying velocities and preserves reference-like styles across complex tasks such as navigating rough terrain and climbing stairs, utilizing only flat-terrain kinematic motion data as a prior. We validate our framework through extensive hardware experiments on the Unitree Go2 quadruped. There, APEX yields diverse and agile locomotion gaits, inherent gait transitions, and the highest reported speed for the platform to the best of our knowledge (peak velocity of ~3.3 m/s on hardware). Our results establish APEX as a compelling alternative to existing IL methods, offering better efficiency, adaptability, and real-world performance.
DecAP: Decaying Action Priors for Accelerated Learning of Torque-Based Legged Locomotion Policies
Oct 09, 2023



Optimal Control for legged robots has gone through a paradigm shift from position-based to torque-based control, owing to the latter's compliant and robust nature. In parallel to this shift, the community has also turned to Deep Reinforcement Learning (DRL) as a promising approach to directly learn locomotion policies for complex real-life tasks. However, most end-to-end DRL approaches still operate in position space, mainly because learning in torque space is often sample-inefficient and does not consistently converge to natural gaits. To address these challenges, we introduce Decaying Action Priors (DecAP), a novel three-stage framework to learn and deploy torque policies for legged locomotion. In the first stage, we generate our own imitation data by training a position policy, eliminating the need for expert knowledge in designing optimal controllers. The second stage incorporates decaying action priors to enhance the exploration of torque-based policies aided by imitation rewards. We show that our approach consistently outperforms imitation learning alone and is significantly robust to the scaling of these rewards. Finally, our third stage facilitates safe sim-to-real transfer by directly deploying our learned torques, alongside low-gain PID control from our trained position policy. We demonstrate the generality of our approach by training torque-based locomotion policies for a biped, a quadruped, and a hexapod robot in simulation, and experimentally demonstrate our learned policies on a quadruped (Unitree Go1).
Multiple Waypoint Navigation in Unknown Indoor Environments
Sep 18, 2022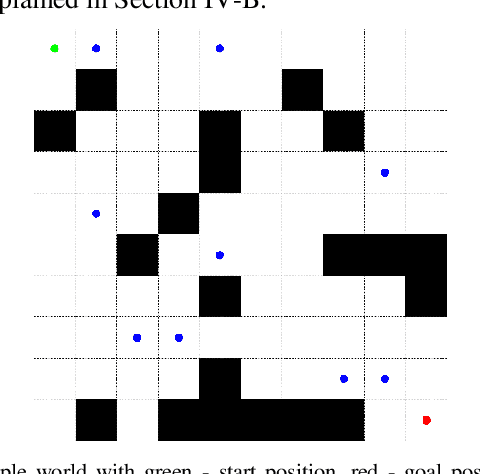
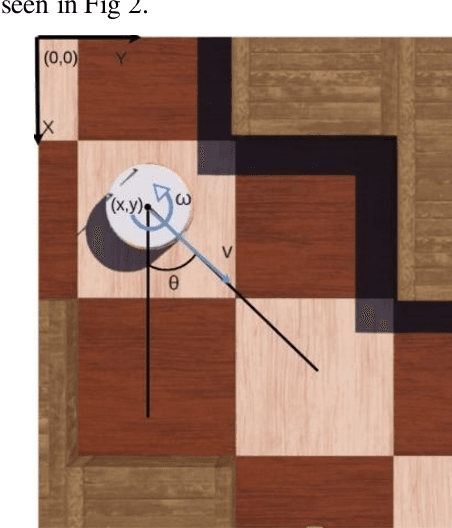
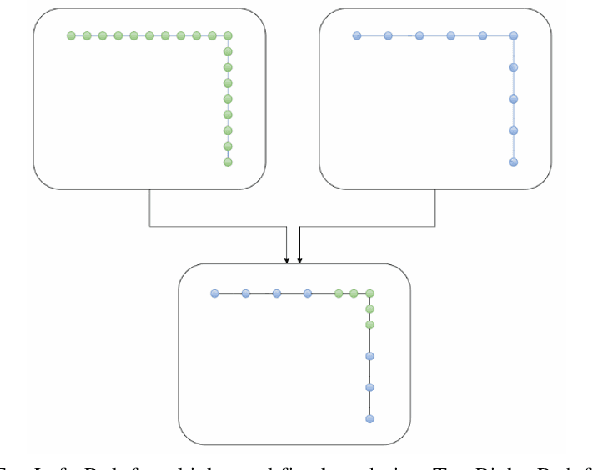
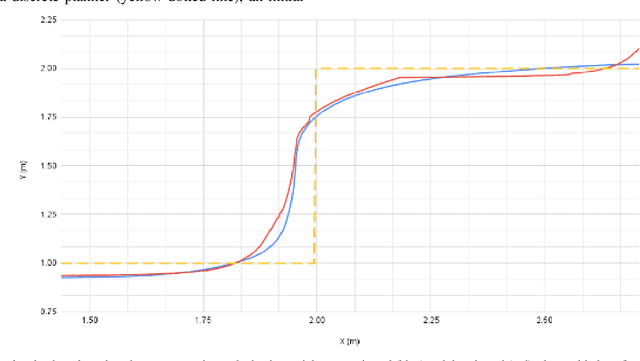
Indoor motion planning focuses on solving the problem of navigating an agent through a cluttered environment. To date, quite a lot of work has been done in this field, but these methods often fail to find the optimal balance between computationally inexpensive online path planning, and optimality of the path. Along with this, these works often prove optimality for single-start single-goal worlds. To address these challenges, we present a multiple waypoint path planner and controller stack for navigation in unknown indoor environments where waypoints include the goal along with the intermediary points that the robot must traverse before reaching the goal. Our approach makes use of a global planner (to find the next best waypoint at any instant), a local planner (to plan the path to a specific waypoint), and an adaptive Model Predictive Control strategy (for robust system control and faster maneuvers). We evaluate our algorithm on a set of randomly generated obstacle maps, intermediate waypoints, and start-goal pairs, with results indicating a significant reduction in computational costs, with high accuracies and robust control.