 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-text Retrieval: A Survey on Recent Research and Development
Mar 28, 2022
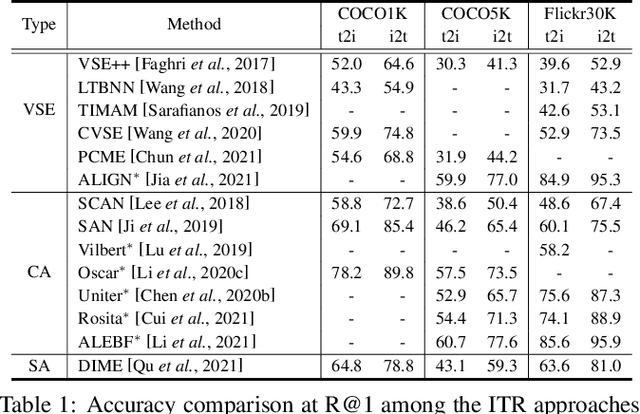
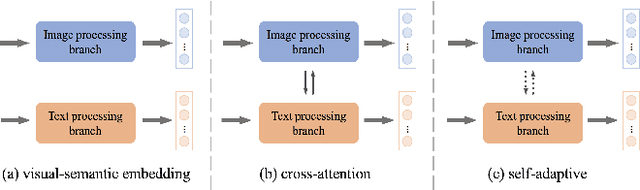
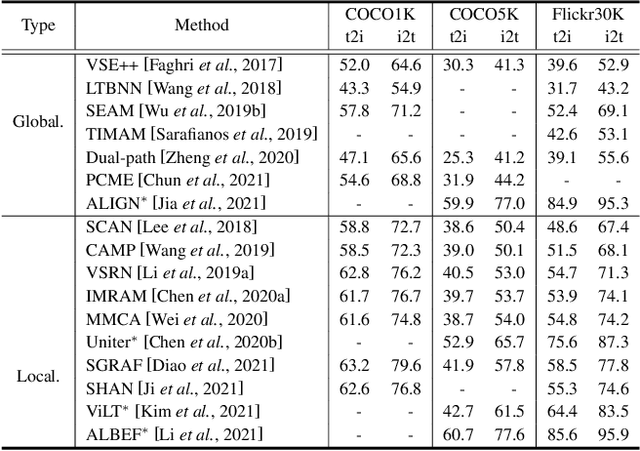
In the past few years, cross-modal image-text retrieval (ITR) has experienced increased interest in the research community due to its excellent research value and broad real-world application. It is designed for the scenarios where the queries are from one modality and the retrieval galleries from another modality. This paper presents a comprehensive and up-to-date survey on the ITR approaches from four perspectives. By dissecting an ITR system into two processes: feature extraction and feature alignment, we summarize the recent advance of the ITR approaches from these two perspectives. On top of this, the efficiency-focused study on the ITR system is introduced as the third perspective. To keep pace with the times, we also provide a pioneering overview of the cross-modal pre-training ITR approaches as the fourth perspective. Finally, we outline the common benchmark datasets and valuation metric for ITR, and conduct the accuracy comparison among the representative ITR approaches. Some critical yet less studied issues are discussed at the end of the paper.
Learning Semantic-Aligned Feature Representation for Text-based Person Search
Dec 13, 2021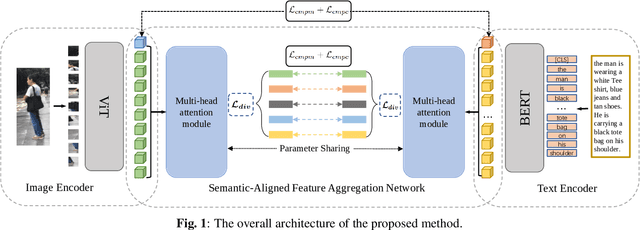



Text-based person search aims to retrieve images of a certain pedestrian by a textual description. The key challenge of this task is to eliminate the inter-modality gap and achieve the feature alignment across modalities. In this paper, we propose a semantic-aligned embedding method for text-based person search, in which the feature alignment across modalities is achieved by automatically learning the semantic-aligned visual features and textual features. First, we introduce two Transformer-based backbones to encode robust feature representations of the images and texts. Second, we design a semantic-aligned feature aggregation network to adaptively select and aggregate features with the same semantics into part-aware features, which is achieved by a multi-head attention module constrained by a cross-modality part alignment loss and a diversity loss. Experimental results on the CUHK-PEDES and Flickr30K datasets show that our method achieves state-of-the-art performances.