 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Power-Weighted Noncentral Complex Gaussian Distribution
Mar 27, 2026The complex Gaussian distribution has been widely used as a fundamental spectral and noise model in signal processing and communication. However, its Gaussian structure often limits its ability to represent the diverse amplitude characteristics observed in individual source signals. On the other hand, many existing non-Gaussian amplitude distributions derived from hyperspherical models achieve good empirical fit due to their power-law structures, while they do not explicitly account for the complex-plane geometry inherent in complex-valued observations. In this paper, we propose a new probabilistic model for complex-valued random variables, which can be interpreted as a power-weighted noncentral complex Gaussian distribution. Unlike conventional hyperspherical amplitude models, the proposed model is formulated directly on the complex plane and preserves the geometric structure of complex-valued observations while retaining a higher-dimensional interpretation. The model introduces a nonlinear phase diffusion through a single shape parameter, enabling continuous control of the distributional geometry from arc-shaped diffusion along the phase direction to concentration of probability mass toward the origin. We formulate the proposed distribution and analyze the statistical properties of the induced amplitude distribution. The derived amplitude and power distributions provide a unified framework encompassing several widely used distributions in signal modeling, including the Rice, Nakagami, and gamma distributions. Experimental results on speech power spectra demonstrate that the proposed model consistently outperforms conventional distributions in terms of log-likelihood.
Gamma Boltzmann Machine for Simultaneously Modeling Linear- and Log-amplitude Spectra
Jun 25, 2020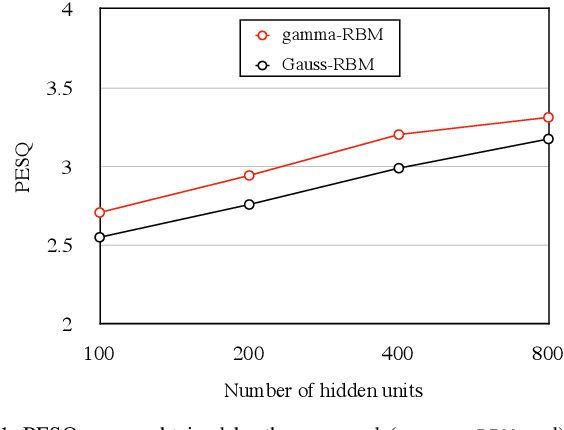
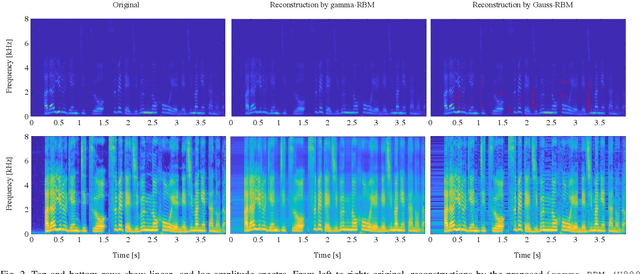
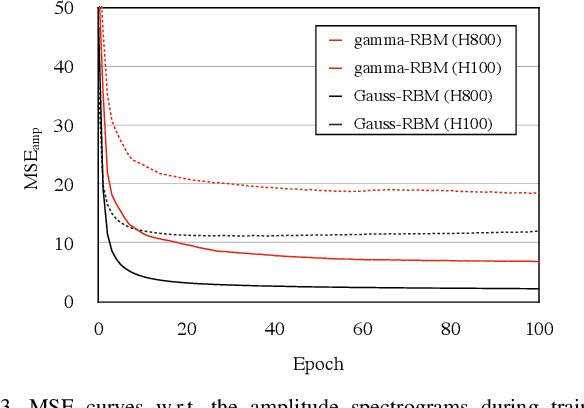
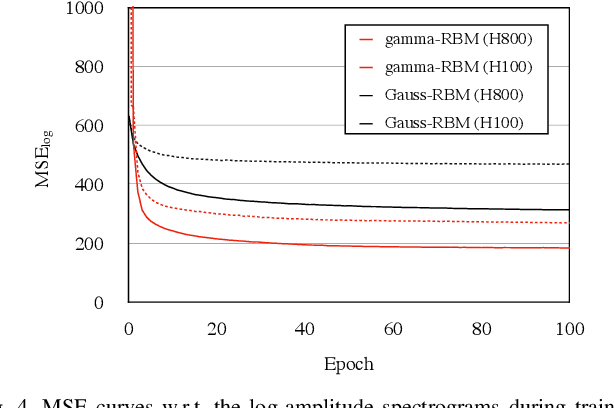
In audio applications, one of the most important representations of audio signals is the amplitude spectrogram. It is utilized in many machine-learning-based information processing methods including the ones using the restricted Boltzmann machines (RBM). However, the ordinary Gaussian-Bernoulli RBM (the most popular RBM among its variations) cannot directly handle amplitude spectra because the Gaussian distribution is a symmetric model allowing negative values which never appear in the amplitude. In this paper, after proposing a general gamma Boltzmann machine, we propose a practical model called the gamma-Bernoulli RBM that simultaneously handles both linear- and log-amplitude spectrograms. Its conditional distribution of the observable data is given by the gamma distribution, and thus the proposed RBM can naturally handle the data represented by positive numbers as the amplitude spectra. It can also treat amplitude in the logarithmic scale which is important for audio signals from the perceptual point of view. The advantage of the proposed model compared to the ordinary Gaussian-Bernoulli RBM was confirmed by PESQ and MSE in the experiment of representing the amplitude spectrograms of speech signals.
STFT spectral loss for training a neural speech waveform model
Oct 30, 2018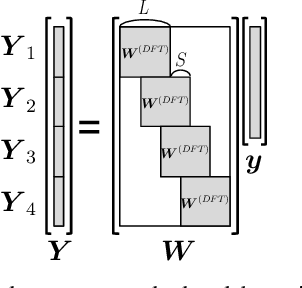
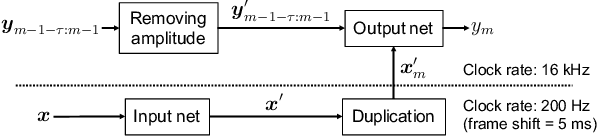
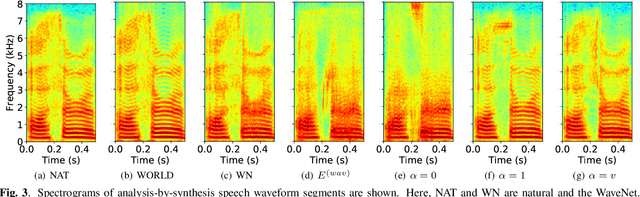
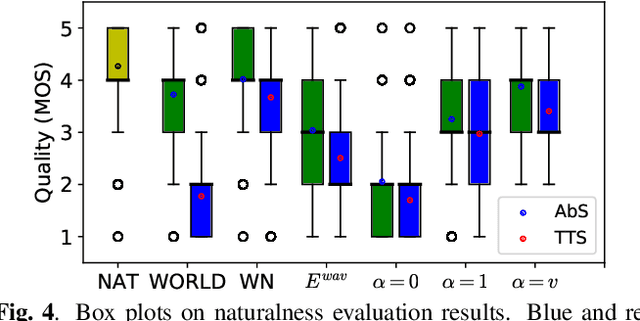
This paper proposes a new loss using short-time Fourier transform (STFT) spectra for the aim of training a high-performance neural speech waveform model that predicts raw continuous speech waveform samples directly. Not only amplitude spectra but also phase spectra obtained from generated speech waveforms are used to calculate the proposed loss. We also mathematically show that training of the waveform model on the basis of the proposed loss can be interpreted as maximum likelihood training that assumes the amplitude and phase spectra of generated speech waveforms following Gaussian and von Mises distributions, respectively. Furthermore, this paper presents a simple network architecture as the speech waveform model, which is composed of uni-directional long short-term memories (LSTMs) and an auto-regressive structure. Experimental results showed that the proposed neural model synthesized high-quality speech waveforms.
Complex-Valued Restricted Boltzmann Machine for Direct Speech Parameterization from Complex Spectra
Mar 27, 2018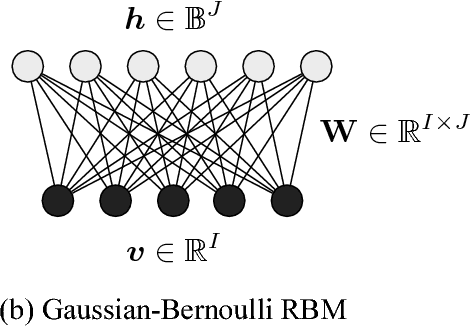
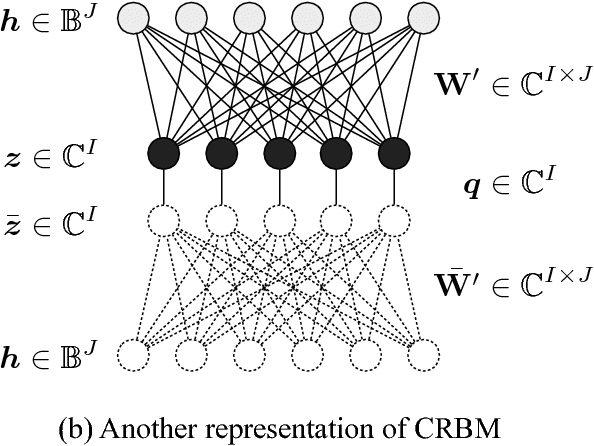
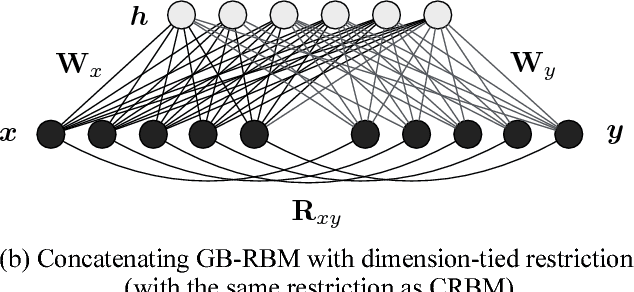
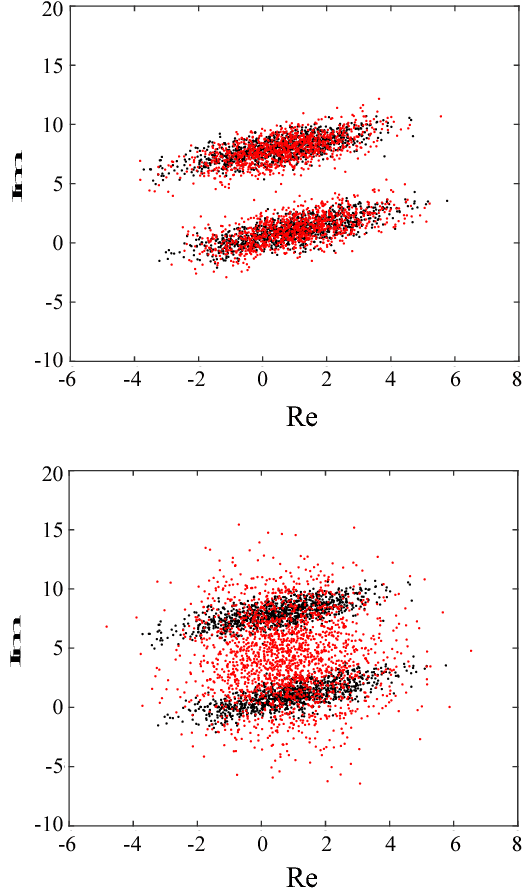
This paper describes a novel energy-based probabilistic distribution that represents complex-valued data and explains how to apply it to direct feature extraction from complex-valued spectra. The proposed model, the complex-valued restricted Boltzmann machine (CRBM), is designed to deal with complex-valued visible units as an extension of the well-known restricted Boltzmann machine (RBM). Like the RBM, the CRBM learns the relationships between visible and hidden units without having connections between units in the same layer, which dramatically improves training efficiency by using Gibbs sampling or contrastive divergence (CD). Another important characteristic is that the CRBM also has connections between real and imaginary parts of each of the complex-valued visible units that help represent the data distribution in the complex domain. In speech signal processing, classification and generation features are often based on amplitude spectra (e.g., MFCC, cepstra, and mel-cepstra) even if they are calculated from complex spectra, and they ignore phase information. In contrast, the proposed feature extractor using the CRBM directly encodes the complex spectra (or another complex-valued representation of the complex spectra) into binary-valued latent features (hidden units). Since the visible-hidden connections are undirected, we can also recover (decode) the complex spectra from the latent features directly. Our speech coding experiments demonstrated that the CRBM outperformed other speech coding methods, such as methods using the conventional RBM, the mel-log spectrum approximate (MLSA) decoder, etc.