 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA model for interpreting social interactions in local image regions
Dec 26, 2017
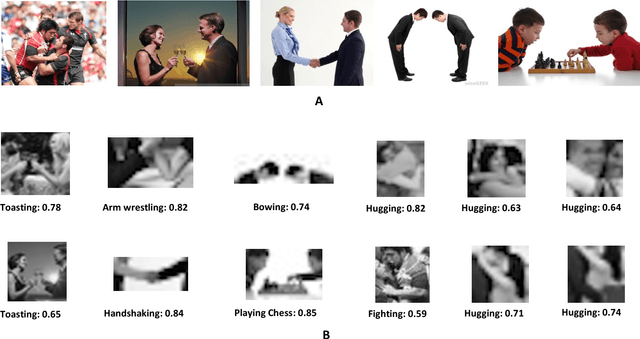


Understanding social interactions (such as 'hug' or 'fight') is a basic and important capacity of the human visual system, but a challenging and still open problem for modeling. In this work we study visual recognition of social interactions, based on small but recognizable local regions. The approach is based on two novel key components: (i) A given social interaction can be recognized reliably from reduced images (called 'minimal images'). (ii) The recognition of a social interaction depends on identifying components and relations within the minimal image (termed 'interpretation'). We show psychophysics data for minimal images and modeling results for their interpretation. We discuss the integration of minimal configurations in recognizing social interactions in a detailed, high-resolution image.
Structured learning and detailed interpretation of minimal object images
Nov 29, 2017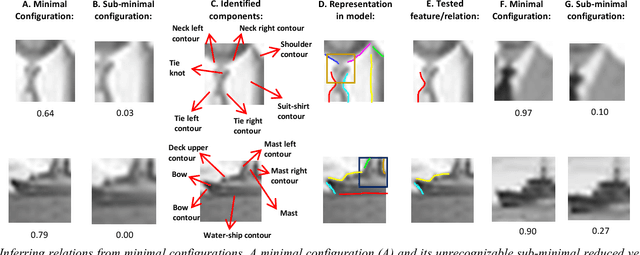



We model the process of human full interpretation of object images, namely the ability to identify and localize all semantic features and parts that are recognized by human observers. The task is approached by dividing the interpretation of the complete object to the interpretation of multiple reduced but interpretable local regions. We model interpretation by a structured learning framework, in which there are primitive components and relations that play a useful role in local interpretation by humans. To identify useful components and relations used in the interpretation process, we consider the interpretation of minimal configurations, namely reduced local regions that are minimal in the sense that further reduction will turn them unrecognizable and uninterpretable. We show experimental results of our model, and results of predicting and testing relations that were useful to the model via transformed minimal images.
Measuring and modeling the perception of natural and unconstrained gaze in humans and machines
Nov 29, 2016
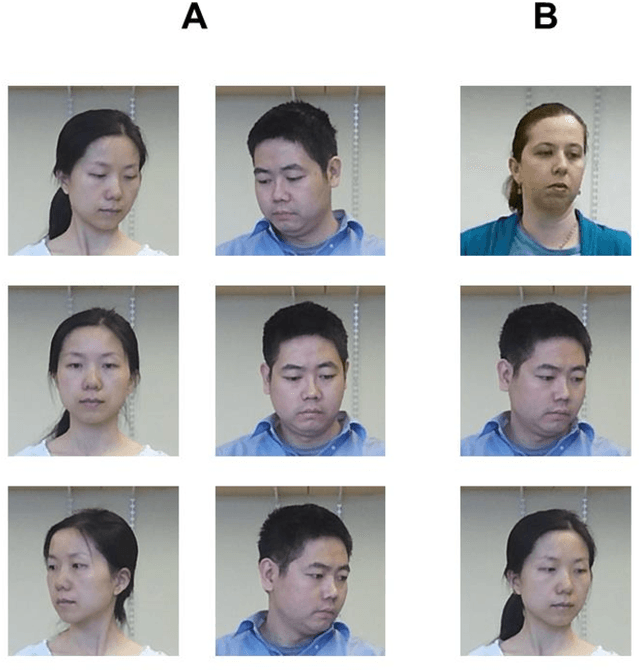
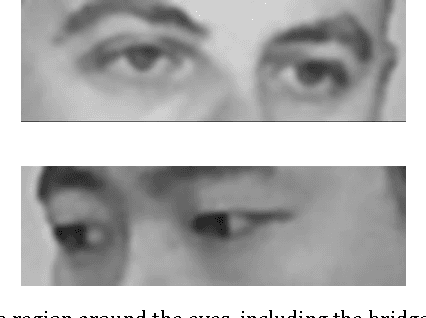

Humans are remarkably adept at interpreting the gaze direction of other individuals in their surroundings. This skill is at the core of the ability to engage in joint visual attention, which is essential for establishing social interactions. How accurate are humans in determining the gaze direction of others in lifelike scenes, when they can move their heads and eyes freely, and what are the sources of information for the underlying perceptual processes? These questions pose a challenge from both empirical and computational perspectives, due to the complexity of the visual input in real-life situations. Here we measure empirically human accuracy in perceiving the gaze direction of others in lifelike scenes, and study computationally the sources of information and representations underlying this cognitive capacity. We show that humans perform better in face-to-face conditions compared with recorded conditions, and that this advantage is not due to the availability of input dynamics. We further show that humans are still performing well when only the eyes-region is visible, rather than the whole face. We develop a computational model, which replicates the pattern of human performance, including the finding that the eyes-region contains on its own, the required information for estimating both head orientation and direction of gaze. Consistent with neurophysiological findings on task-specific face regions in the brain, the learned computational representations reproduce perceptual effects such as the Wollaston illusion, when trained to estimate direction of gaze, but not when trained to recognize objects or faces.
Discovering containment: from infants to machines
Oct 30, 2016
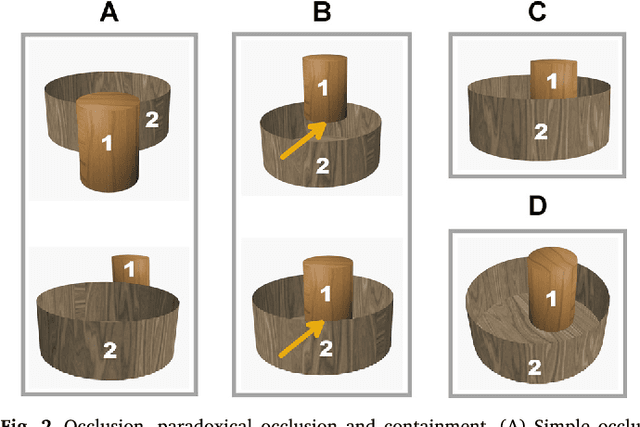
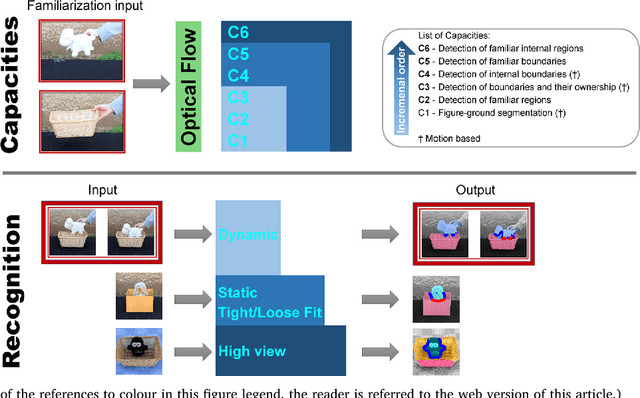

Current artificial learning systems can recognize thousands of visual categories, or play Go at a champion"s level, but cannot explain infants learning, in particular the ability to learn complex concepts without guidance, in a specific order. A notable example is the category of 'containers' and the notion of containment, one of the earliest spatial relations to be learned, starting already at 2.5 months, and preceding other common relations (e.g., support). Such spontaneous unsupervised learning stands in contrast with current highly successful computational models, which learn in a supervised manner, that is, by using large data sets of labeled examples. How can meaningful concepts be learned without guidance, and what determines the trajectory of infant learning, making some notions appear consistently earlier than others?
Visual Concept Recognition and Localization via Iterative Introspection
May 25, 2016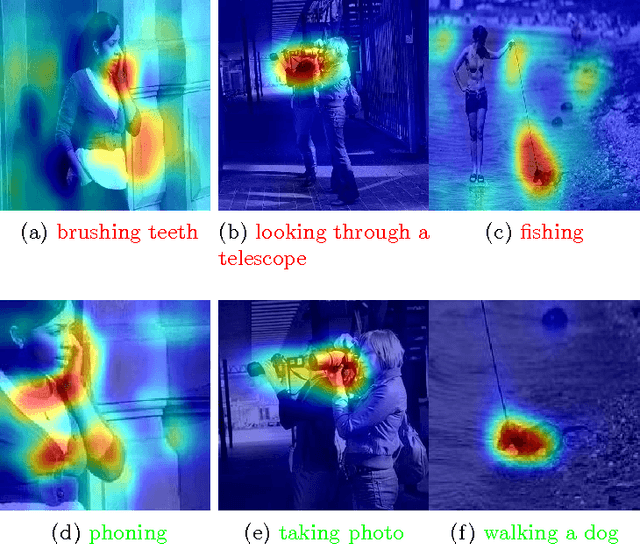
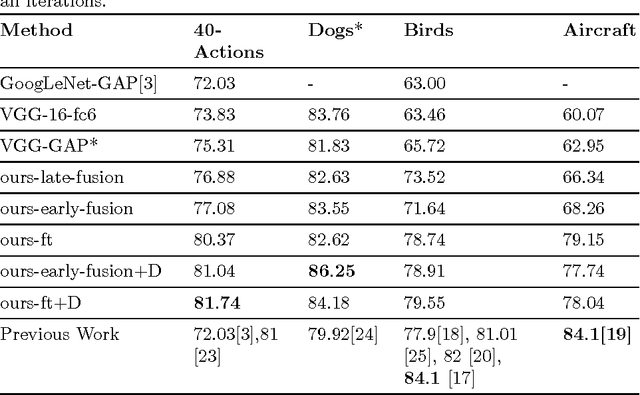
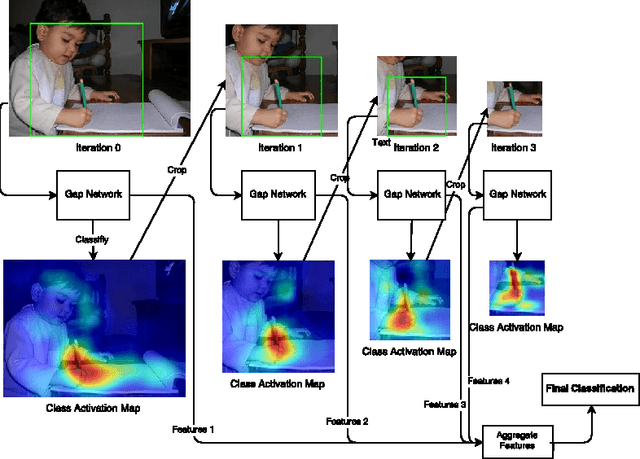
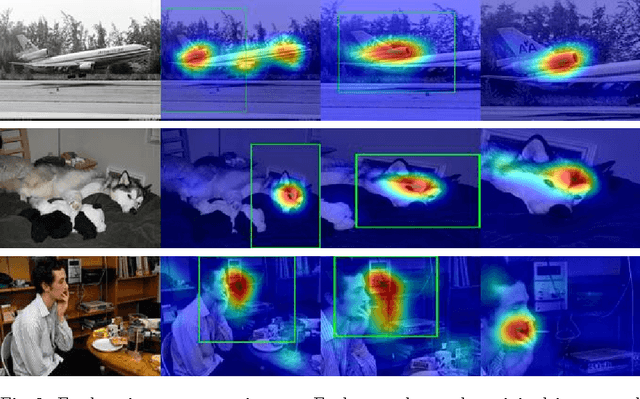
Convolutional neural networks have been shown to develop internal representations, which correspond closely to semantically meaningful objects and parts, although trained solely on class labels. Class Activation Mapping (CAM) is a recent method that makes it possible to easily highlight the image regions contributing to a network's classification decision. We build upon these two developments to enable a network to re-examine informative image regions, which we term introspection. We propose a weakly-supervised iterative scheme, which shifts its center of attention to increasingly discriminative regions as it progresses, by alternating stages of classification and introspection. We evaluate our method and show its effectiveness over a range of several datasets, where we obtain competitive or state-of-the-art results: on Stanford-40 Actions, we set a new state-of the art of 81.74%. On FGVC-Aircraft and the Stanford Dogs dataset, we show consistent improvements over baselines, some of which include significantly more supervision.
Human Pose Estimation using Deep Consensus Voting
Mar 27, 2016
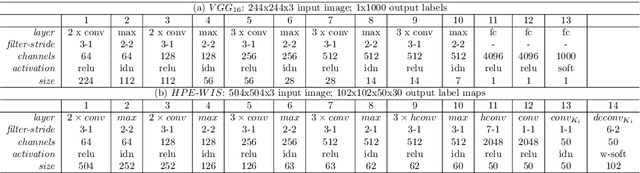
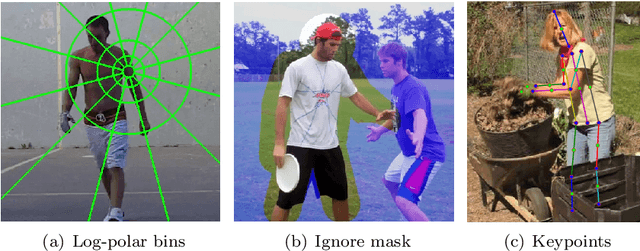
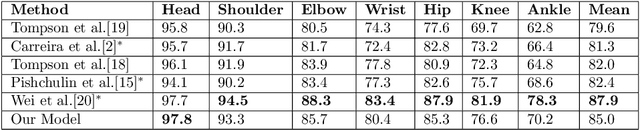
In this paper we consider the problem of human pose estimation from a single still image. We propose a novel approach where each location in the image votes for the position of each keypoint using a convolutional neural net. The voting scheme allows us to utilize information from the whole image, rather than rely on a sparse set of keypoint locations. Using dense, multi-target votes, not only produces good keypoint predictions, but also enables us to compute image-dependent joint keypoint probabilities by looking at consensus voting. This differs from most previous methods where joint probabilities are learned from relative keypoint locations and are independent of the image. We finally combine the keypoints votes and joint probabilities in order to identify the optimal pose configuration. We show our competitive performance on the MPII Human Pose and Leeds Sports Pose datasets.
Do You See What I Mean? Visual Resolution of Linguistic Ambiguities
Mar 26, 2016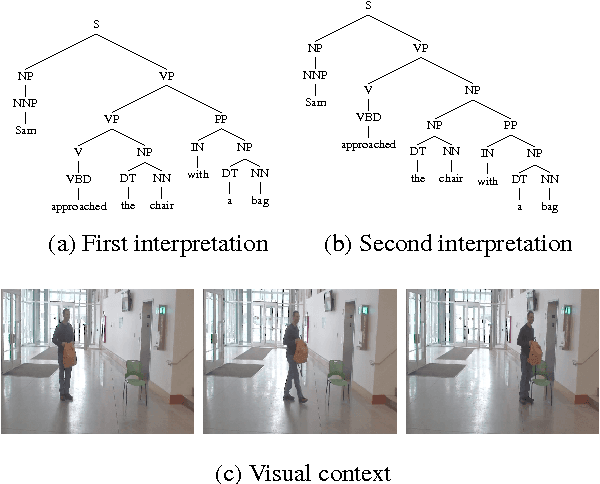
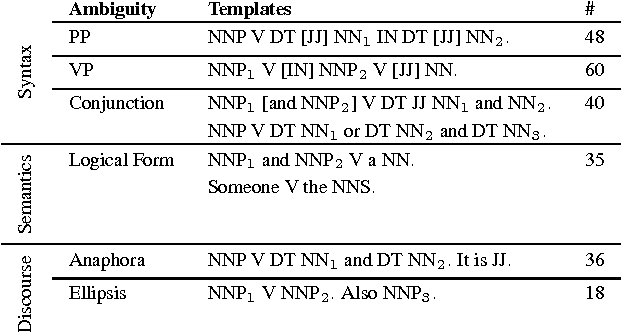
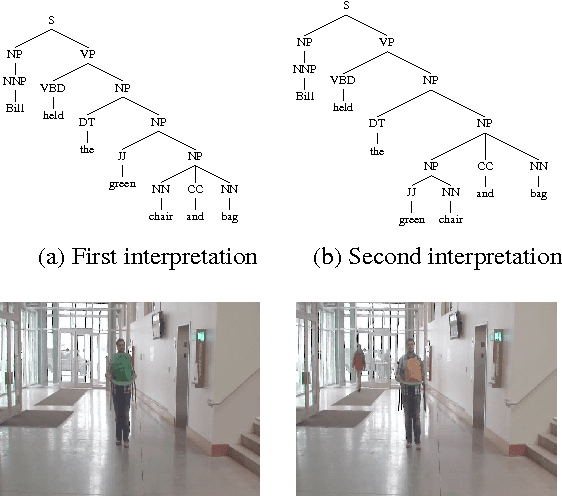

Understanding language goes hand in hand with the ability to integrate complex contextual information obtained via perception. In this work, we present a novel task for grounded language understanding: disambiguating a sentence given a visual scene which depicts one of the possible interpretations of that sentence. To this end, we introduce a new multimodal corpus containing ambiguous sentences, representing a wide range of syntactic, semantic and discourse ambiguities, coupled with videos that visualize the different interpretations for each sentence. We address this task by extending a vision model which determines if a sentence is depicted by a video. We demonstrate how such a model can be adjusted to recognize different interpretations of the same underlying sentence, allowing to disambiguate sentences in a unified fashion across the different ambiguity types.
* EMNLP 2015
Hand-Object Interaction and Precise Localization in Transitive Action Recognition
Feb 24, 2016
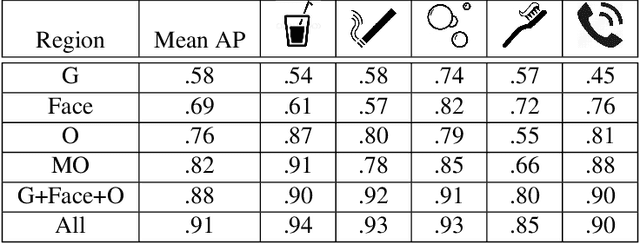
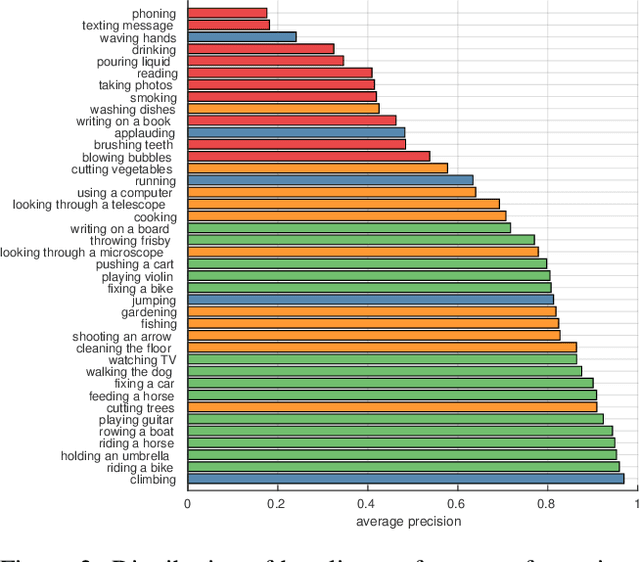
Action recognition in still images has seen major improvement in recent years due to advances in human pose estimation, object recognition and stronger feature representations produced by deep neural networks. However, there are still many cases in which performance remains far from that of humans. A major difficulty arises in distinguishing between transitive actions in which the overall actor pose is similar, and recognition therefore depends on details of the grasp and the object, which may be largely occluded. In this paper we demonstrate how recognition is improved by obtaining precise localization of the action-object and consequently extracting details of the object shape together with the actor-object interaction. To obtain exact localization of the action object and its interaction with the actor, we employ a coarse-to-fine approach which combines semantic segmentation and contextual features, in successive stages. We focus on (but are not limited) to face-related actions, a set of actions that includes several currently challenging categories. We present an average relative improvement of 35% over state-of-the art and validate through experimentation the effectiveness of our approach.
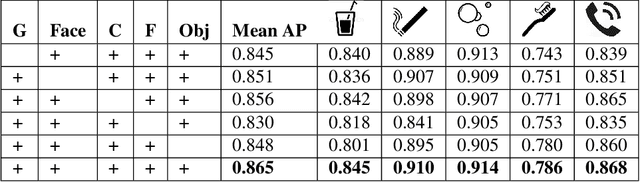
Face-space Action Recognition by Face-Object Interactions
Jan 17, 2016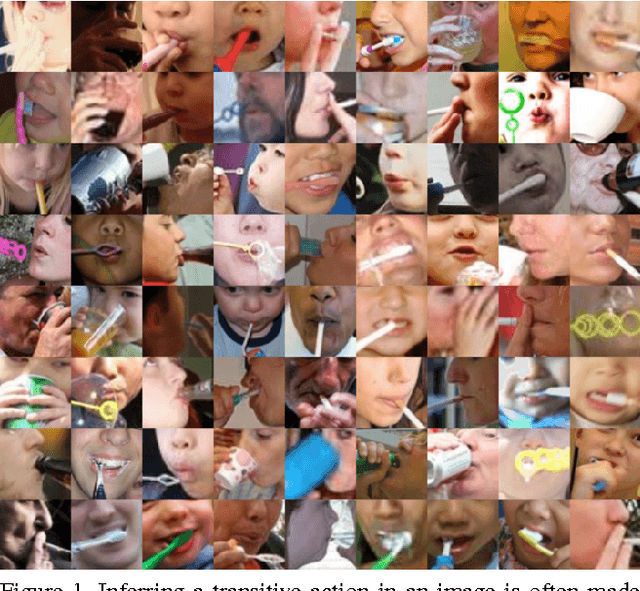

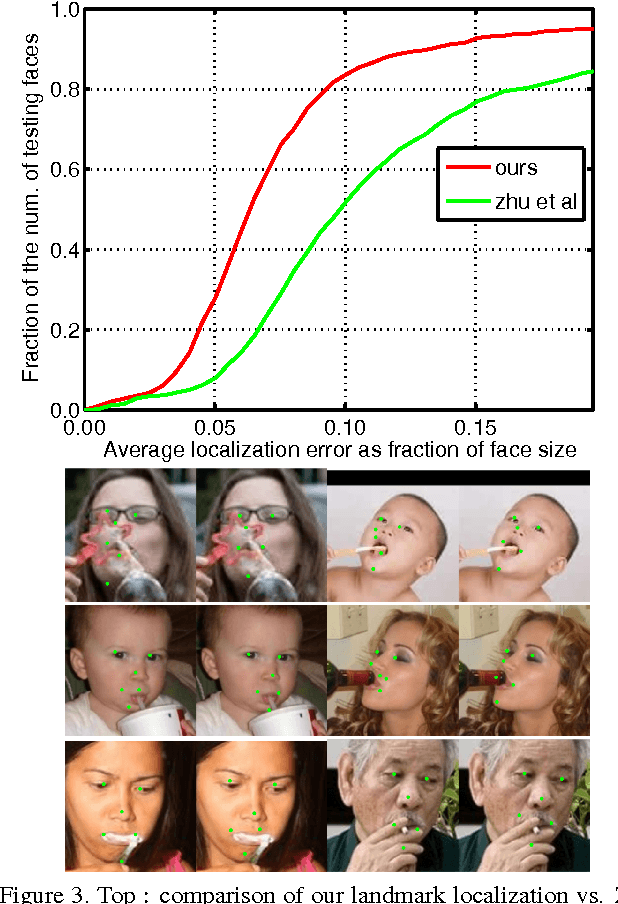

Action recognition in still images has seen major improvement in recent years due to advances in human pose estimation, object recognition and stronger feature representations. However, there are still many cases in which performance remains far from that of humans. In this paper, we approach the problem by learning explicitly, and then integrating three components of transitive actions: (1) the human body part relevant to the action (2) the object being acted upon and (3) the specific form of interaction between the person and the object. The process uses class-specific features and relations not used in the past for action recognition and which use inherently two cycles in the process unlike most standard approaches. We focus on face-related actions (FRA), a subset of actions that includes several currently challenging categories. We present an average relative improvement of 52% over state-of-the art. We also make a new benchmark publicly available.
Learning Local Invariant Mahalanobis Distances
Feb 04, 2015


For many tasks and data types, there are natural transformations to which the data should be invariant or insensitive. For instance, in visual recognition, natural images should be insensitive to rotation and translation. This requirement and its implications have been important in many machine learning applications, and tolerance for image transformations was primarily achieved by using robust feature vectors. In this paper we propose a novel and computationally efficient way to learn a local Mahalanobis metric per datum, and show how we can learn a local invariant metric to any transformation in order to improve performance.