 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Classifiers in Sentiment Analysis
Oct 20, 2021


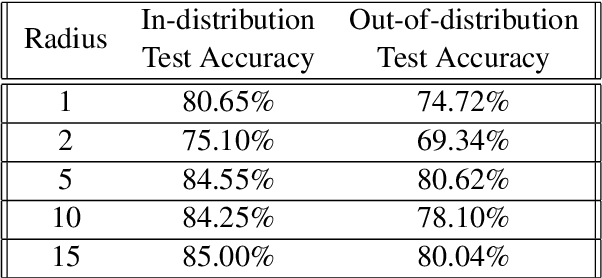
In this paper, we propose sentiment classification models based on BERT integrated with DRO (Distributionally Robust Classifiers) to improve model performance on datasets with distributional shifts. We added 2-Layer Bi-LSTM, projection layer (onto simplex or Lp ball), and linear layer on top of BERT to achieve distributionally robustness. We considered one form of distributional shift (from IMDb dataset to Rotten Tomatoes dataset). We have confirmed through experiments that our DRO model does improve performance on our test set with distributional shift from the training set.
Ensemble ALBERT on SQuAD 2.0
Oct 19, 2021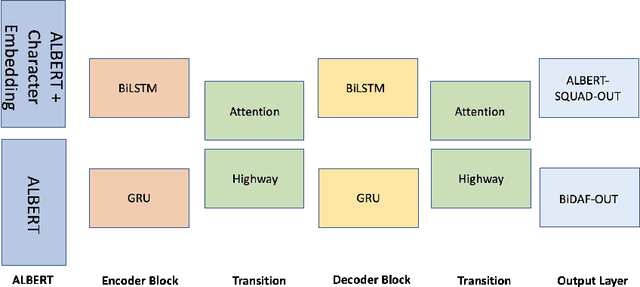

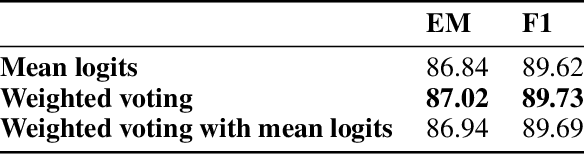
Machine question answering is an essential yet challenging task in natural language processing. Recently, Pre-trained Contextual Embeddings (PCE) models like Bidirectional Encoder Representations from Transformers (BERT) and A Lite BERT (ALBERT) have attracted lots of attention due to their great performance in a wide range of NLP tasks. In our Paper, we utilized the fine-tuned ALBERT models and implemented combinations of additional layers (e.g. attention layer, RNN layer) on top of them to improve model performance on Stanford Question Answering Dataset (SQuAD 2.0). We implemented four different models with different layers on top of ALBERT-base model, and two other models based on ALBERT-xlarge and ALBERT-xxlarge. We compared their performance to our baseline model ALBERT-base-v2 + ALBERT-SQuAD-out with details. Our best-performing individual model is ALBERT-xxlarge + ALBERT-SQuAD-out, which achieved an F1 score of 88.435 on the dev set. Furthermore, we have implemented three different ensemble algorithms to boost overall performance. By passing in several best-performing models' results into our weighted voting ensemble algorithm, our final result ranks first on the Stanford CS224N Test PCE SQuAD Leaderboard with F1 = 90.123.
Text Mining for Processing Interview Data in Computational Social Science
Nov 28, 2020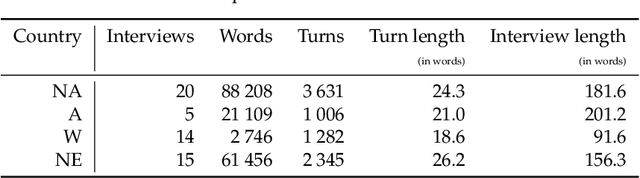
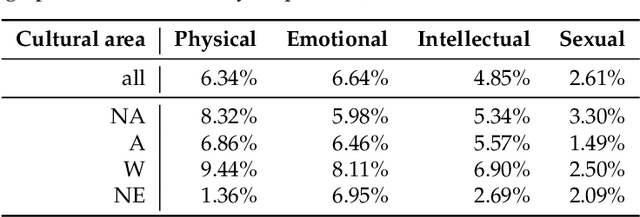
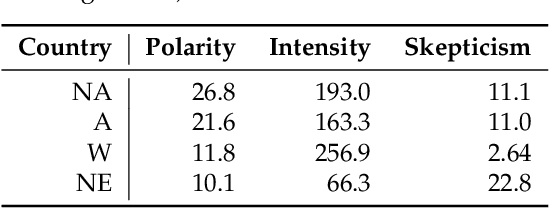
We use commercially available text analysis technology to process interview text data from a computational social science study. We find that topical clustering and terminological enrichment provide for convenient exploration and quantification of the responses. This makes it possible to generate and test hypotheses and to compare textual and non-textual variables, and saves analyst effort. We encourage studies in social science to use text analysis, especially for exploratory open-ended studies. We discuss how replicability requirements are met by text analysis technology. We note that the most recent learning models are not designed with transparency in mind, and that research requires a model to be editable and its decisions to be explainable. The tools available today, such as the one used in the present study, are not built for processing interview texts. While many of the variables under consideration are quantifiable using lexical statistics, we find that some interesting and potentially valuable features are difficult or impossible to automatise reliably at present. We note that there are some potentially interesting applications for traditional natural language processing mechanisms such as named entity recognition and anaphora resolution in this application area. We conclude with a suggestion for language technologists to investigate the challenge of processing interview data comprehensively, especially the interplay between question and response, and we encourage social science researchers not to hesitate to use text analysis tools, especially for the exploratory phase of processing interview data.?