 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Hyper-Parameter Optimization Methods for Retrieval Augmented Generation
May 06, 2025Finding the optimal Retrieval-Augmented Generation (RAG) configuration for a given use case can be complex and expensive. Motivated by this challenge, frameworks for RAG hyper-parameter optimization (HPO) have recently emerged, yet their effectiveness has not been rigorously benchmarked. To address this gap, we present a comprehensive study involving 5 HPO algorithms over 5 datasets from diverse domains, including a new one collected for this work on real-world product documentation. Our study explores the largest HPO search space considered to date, with two optimized evaluation metrics. Analysis of the results shows that RAG HPO can be done efficiently, either greedily or with iterative random search, and that it significantly boosts RAG performance for all datasets. For greedy HPO approaches, we show that optimizing models first is preferable to the prevalent practice of optimizing sequentially according to the RAG pipeline order.
Label Sleuth: From Unlabeled Text to a Classifier in a Few Hours
Aug 02, 2022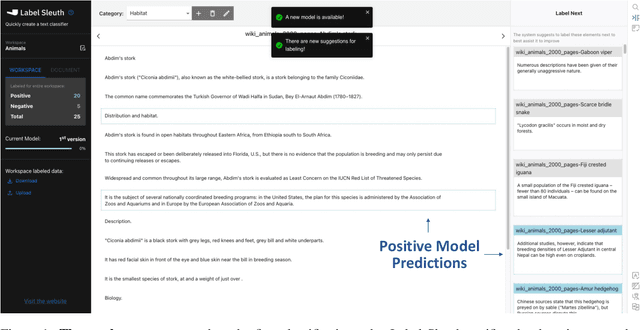


Text classification can be useful in many real-world scenarios, saving a lot of time for end users. However, building a custom classifier typically requires coding skills and ML knowledge, which poses a significant barrier for many potential users. To lift this barrier, we introduce Label Sleuth, a free open source system for labeling and creating text classifiers. This system is unique for (a) being a no-code system, making NLP accessible to non-experts, (b) guiding users through the entire labeling process until they obtain a custom classifier, making the process efficient -- from cold start to classifier in a few hours, and (c) being open for configuration and extension by developers. By open sourcing Label Sleuth we hope to build a community of users and developers that will broaden the utilization of NLP models.