 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Machine Co-Boosted Bug Report Identification with Mutualistic Neural Active Learning
Apr 20, 2026Bug reports, encompassing a wide range of bug types, are crucial for maintaining software quality. However, the increasing complexity and volume of bug reports pose a significant challenge in sole manual identification and assignment to the appropriate teams for resolution, as dealing with all the reports is time-consuming and resource-intensive. In this paper, we introduce a cross-project framework, dubbed Mutualistic Neural Active Learning (MNAL), designed for automated and more effective identification of bug reports from GitHub repositories boosted by human-machine collaboration. MNAL utilizes a neural language model that learns and generalizes reports across different projects, coupled with active learning to form neural active learning. A distinctive feature of MNAL is the purposely crafted mutualistic relation between the machine learners (neural language model) and human labelers (developers) when enriching the knowledge learned. That is, the most informative human-labeled reports and their corresponding pseudo-labeled ones are used to update the model while those reports that need to be labeled by developers are more readable and identifiable, thereby enhancing the human-machine teaming therein. We evaluate MNAL using a large scale dataset against the SOTA approaches, baselines, and different variants. The results indicate that MNAL achieves up to 95.8% and 196.0% effort reduction in terms of readability and identifiability during human labeling, respectively, while resulting in a better performance in bug report identification. Additionally, our MNAL is model-agnostic since it is capable of improving the model performance with various underlying neural language models. To further verify the efficacy of our approach, we conducted a qualitative case study involving 10 human participants, who rate MNAL as being more effective while saving more time and monetary resources.
Light over Heavy: Automated Performance Requirements Quantification with Linguistic Inducement
Nov 05, 2025Elicited performance requirements need to be quantified for compliance in different engineering tasks, e.g., configuration tuning and performance testing. Much existing work has relied on manual quantification, which is expensive and error-prone due to the imprecision. In this paper, we present LQPR, a highly efficient automatic approach for performance requirements quantification.LQPR relies on a new theoretical framework that converts quantification as a classification problem. Despite the prevalent applications of Large Language Models (LLMs) for requirement analytics, LQPR takes a different perspective to address the classification: we observed that performance requirements can exhibit strong patterns and are often short/concise, therefore we design a lightweight linguistically induced matching mechanism. We compare LQPR against nine state-of-the-art learning-based approaches over diverse datasets, demonstrating that it is ranked as the sole best for 75% or more cases with two orders less cost. Our work proves that, at least for performance requirement quantification, specialized methods can be more suitable than the general LLM-driven approaches.
Transfer-Learning Oriented Class Imbalance Learning for Cross-Project Defect Prediction
Jan 24, 2019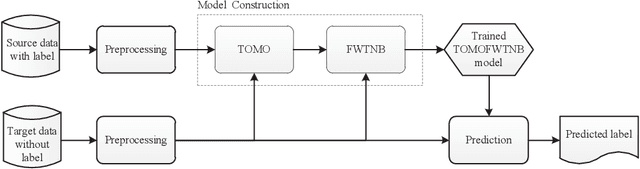
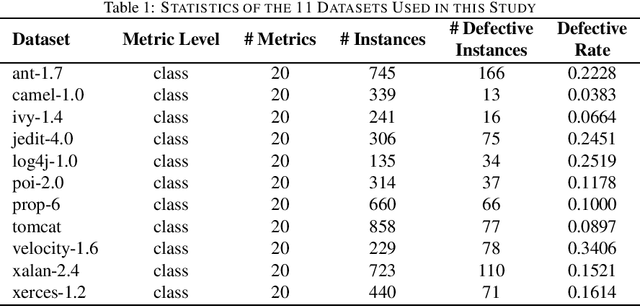
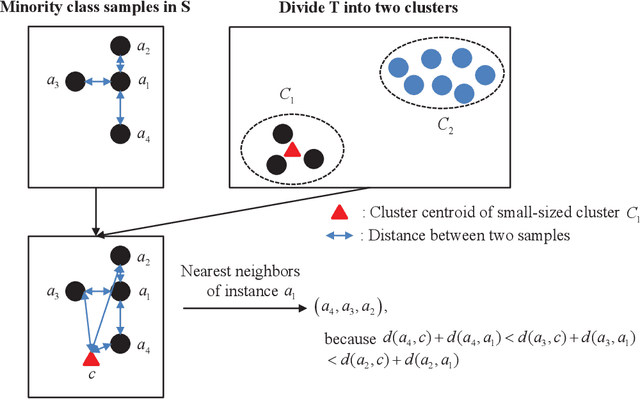
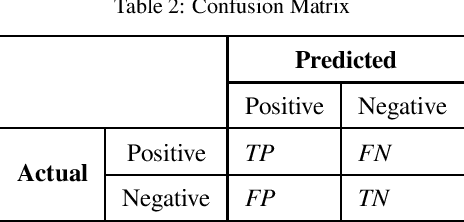
Cross-project defect prediction (CPDP) aims to predict defects of projects lacking training data by using prediction models trained on historical defect data from other projects. However, since the distribution differences between datasets from different projects, it is still a challenge to build high-quality CPDP models. Unfortunately, class imbalanced nature of software defect datasets further increases the difficulty. In this paper, we propose a transferlearning oriented minority over-sampling technique (TOMO) based feature weighting transfer naive Bayes (FWTNB) approach (TOMOFWTNB) for CPDP by considering both classimbalance and feature importance problems. Differing from traditional over-sampling techniques, TOMO not only can balance the data but reduce the distribution difference. And then FWTNB is used to further increase the similarity of two distributions. Experiments are performed on 11 public defect datasets. The experimental results show that (1) TOMO improves the average G-Measure by 23.7\%$\sim$41.8\%, and the average MCC by 54.2\%$\sim$77.8\%. (2) feature weighting (FW) strategy improves the average G-Measure by 11\%, and the average MCC by 29.2\%. (3) TOMOFWTNB improves the average G-Measure value by at least 27.8\%, and the average MCC value by at least 71.5\%, compared with existing state-of-theart CPDP approaches. It can be concluded that (1) TOMO is very effective for addressing class-imbalance problem in CPDP scenario; (2) our FW strategy is helpful for CPDP; (3) TOMOFWTNB outperforms previous state-of-the-art CPDP approaches.