 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESTANet: Efficient Online Error Detection in Procedural Videos via Prediction Inconsistency
Jun 24, 2026An efficient and accurate system for detecting errors in procedural tasks is crucial for supporting human needs in daily life, as it can provide instant notifications and guide people to correct mistakes. In this work, we study real-time online error detection in procedural videos from a simple but overlooked perspective: the prediction behavior of action detectors themselves. Instead of designing complex architectures or specialized supervision, we observe that action detectors naturally exhibit different prediction characteristics depending on their sensitivity to input dynamics and temporal context. We therefore propose ESTANet (Error-Sensitive and Temporally-vArying Network), a lightweight framework that detects errors by exploiting inconsistencies among action predictions produced by a small set of action detectors. We construct standard and error-sensitive action detectors that behave similarly on correct executions but respond differently when errors occur. Meanwhile, detectors operating with different temporal contexts further amplify prediction inconsistencies when the procedure deviates from the intended sequence. During inference, we detect errors by aggregating mismatches between standard and error-sensitive predictions through majority voting to flag frames that contain errors. Extensive experiments on EgoPER, Assembly-101-O, and EPIC-Tent-O demonstrate that ESTANet achieves state-of-the-art performance in online error detection while maintaining real-time efficiency with a lightweight architecture. Our results highlight that leveraging the intrinsic properties of action detectors can yield a powerful and practical solution for online error detection without increasing architectural design complexity.
HuPR: A Benchmark for Human Pose Estimation Using Millimeter Wave Radar
Oct 22, 2022This paper introduces a novel human pose estimation benchmark, Human Pose with Millimeter Wave Radar (HuPR), that includes synchronized vision and radio signal components. This dataset is created using cross-calibrated mmWave radar sensors and a monocular RGB camera for cross-modality training of radar-based human pose estimation. There are two advantages of using mmWave radar to perform human pose estimation. First, it is robust to dark and low-light conditions. Second, it is not visually perceivable by humans and thus, can be widely applied to applications with privacy concerns, e.g., surveillance systems in patient rooms. In addition to the benchmark, we propose a cross-modality training framework that leverages the ground-truth 2D keypoints representing human body joints for training, which are systematically generated from the pre-trained 2D pose estimation network based on a monocular camera input image, avoiding laborious manual label annotation efforts. The framework consists of a new radar pre-processing method that better extracts the velocity information from radar data, Cross- and Self-Attention Module (CSAM), to fuse multi-scale radar features, and Pose Refinement Graph Convolutional Networks (PRGCN), to refine the predicted keypoint confidence heatmaps. Our intensive experiments on the HuPR benchmark show that the proposed scheme achieves better human pose estimation performance with only radar data, as compared to traditional pre-processing solutions and previous radio-frequency-based methods.
Weakly-Supervised Image Semantic Segmentation Using Graph Convolutional Networks
Apr 01, 2021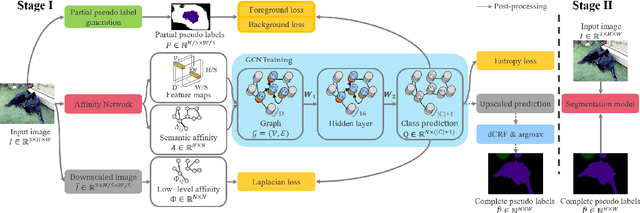
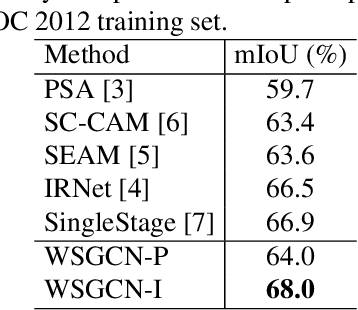


This work addresses weakly-supervised image semantic segmentation based on image-level class labels. One common approach to this task is to propagate the activation scores of Class Activation Maps (CAMs) using a random-walk mechanism in order to arrive at complete pseudo labels for training a semantic segmentation network in a fully-supervised manner. However, the feed-forward nature of the random walk imposes no regularization on the quality of the resulting complete pseudo labels. To overcome this issue, we propose a Graph Convolutional Network (GCN)-based feature propagation framework. We formulate the generation of complete pseudo labels as a semi-supervised learning task and learn a 2-layer GCN separately for every training image by back-propagating a Laplacian and an entropy regularization loss. Experimental results on the PASCAL VOC 2012 dataset confirm the superiority of our scheme to several state-of-the-art baselines. Our code is available at https://github.com/Xavier-Pan/WSGCN.
GSVNet: Guided Spatially-Varying Convolution for Fast Semantic Segmentation on Video
Mar 16, 2021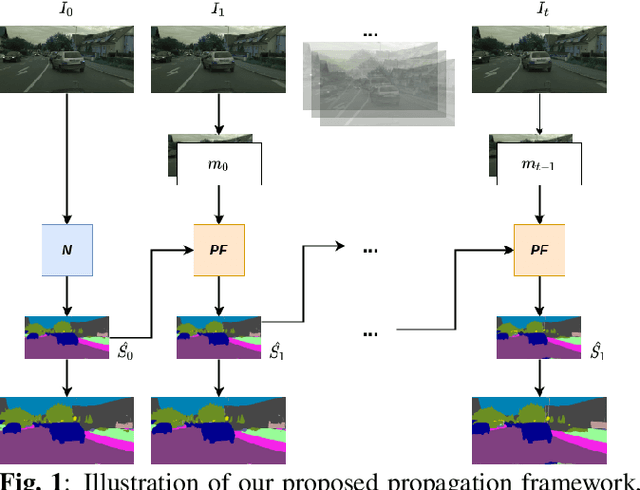
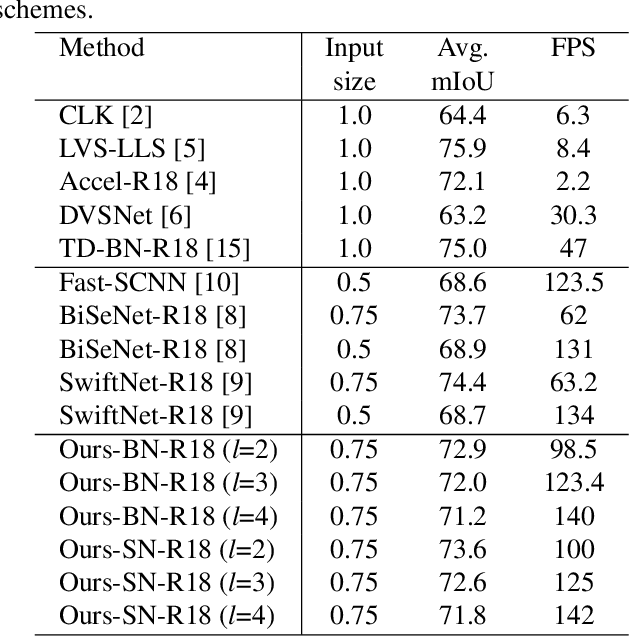
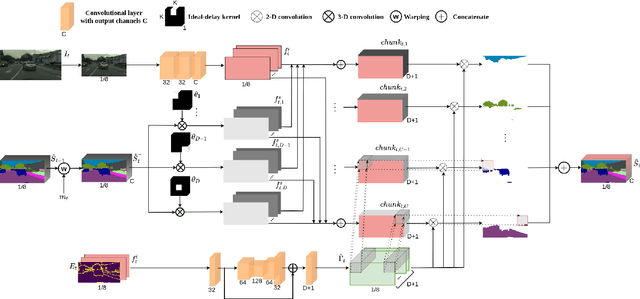
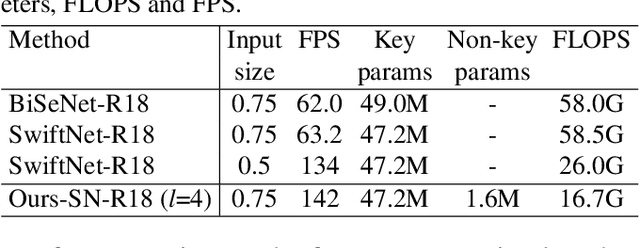
This paper addresses fast semantic segmentation on video.Video segmentation often calls for real-time, or even fasterthan real-time, processing. One common recipe for conserving computation arising from feature extraction is to propagate features of few selected keyframes. However, recent advances in fast image segmentation make these solutions less attractive. To leverage fast image segmentation for furthering video segmentation, we propose a simple yet efficient propagation framework. Specifically, we perform lightweight flow estimation in 1/8-downscaled image space for temporal warping in segmentation outpace space. Moreover, we introduce a guided spatially-varying convolution for fusing segmentations derived from the previous and current frames, to mitigate propagation error and enable lightweight feature extraction on non-keyframes. Experimental results on Cityscapes and CamVid show that our scheme achieves the state-of-the-art accuracy-throughput trade-off on video segmentation.