 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Options
Feb 09, 2018
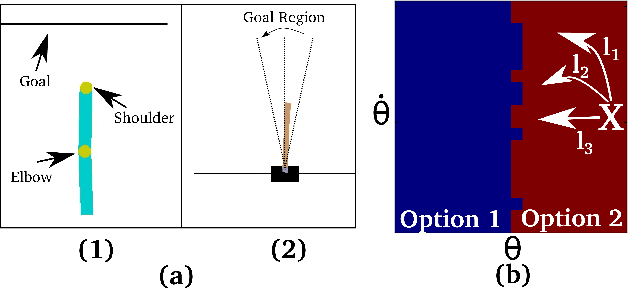
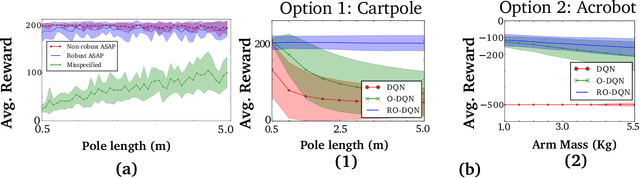
Robust reinforcement learning aims to produce policies that have strong guarantees even in the face of environments/transition models whose parameters have strong uncertainty. Existing work uses value-based methods and the usual primitive action setting. In this paper, we propose robust methods for learning temporally abstract actions, in the framework of options. We present a Robust Options Policy Iteration (ROPI) algorithm with convergence guarantees, which learns options that are robust to model uncertainty. We utilize ROPI to learn robust options with the Robust Options Deep Q Network (RO-DQN) that solves multiple tasks and mitigates model misspecification due to model uncertainty. We present experimental results which suggest that policy iteration with linear features may have an inherent form of robustness when using coarse feature representations. In addition, we present experimental results which demonstrate that robustness helps policy iteration implemented on top of deep neural networks to generalize over a much broader range of dynamics than non-robust policy iteration.
Finite Sample Analyses for TD with Function Approximation
Dec 11, 2017
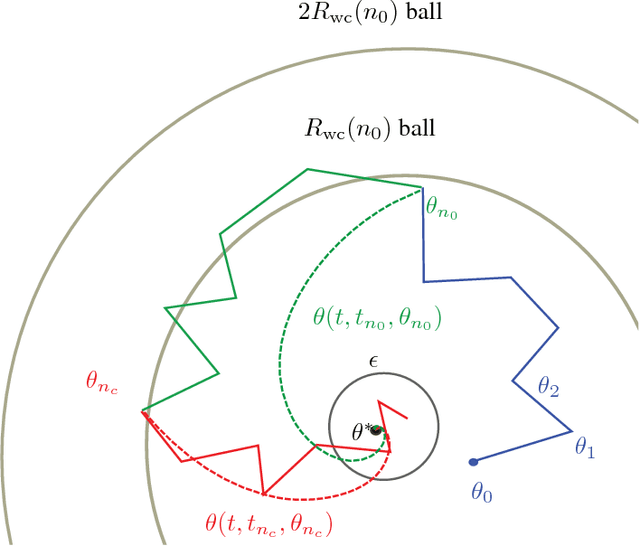
TD(0) is one of the most commonly used algorithms in reinforcement learning. Despite this, there is no existing finite sample analysis for TD(0) with function approximation, even for the linear case. Our work is the first to provide such results. Existing convergence rates for Temporal Difference (TD) methods apply only to somewhat modified versions, e.g., projected variants or ones where stepsizes depend on unknown problem parameters. Our analyses obviate these artificial alterations by exploiting strong properties of TD(0). We provide convergence rates both in expectation and with high-probability. The two are obtained via different approaches that use relatively unknown, recently developed stochastic approximation techniques.
The Stochastic Firefighter Problem
Nov 22, 2017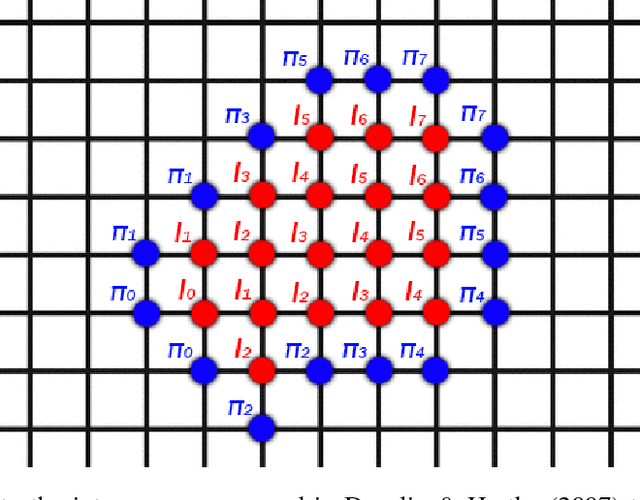

The dynamics of infectious diseases spread is crucial in determining their risk and offering ways to contain them. We study sequential vaccination of individuals in networks. In the original (deterministic) version of the Firefighter problem, a fire breaks out at some node of a given graph. At each time step, b nodes can be protected by a firefighter and then the fire spreads to all unprotected neighbors of the nodes on fire. The process ends when the fire can no longer spread. We extend the Firefighter problem to a probabilistic setting, where the infection is stochastic. We devise a simple policy that only vaccinates neighbors of infected nodes and is optimal on regular trees and on general graphs for a sufficiently large budget. We derive methods for calculating upper and lower bounds of the expected number of infected individuals, as well as provide estimates on the budget needed for containment in expectation. We calculate these explicitly on trees, d-dimensional grids, and Erd\H{o}s R\'{e}nyi graphs. Finally, we construct a state-dependent budget allocation strategy and demonstrate its superiority over constant budget allocation on real networks following a first order acquaintance vaccination policy.
Situationally Aware Options
Nov 20, 2017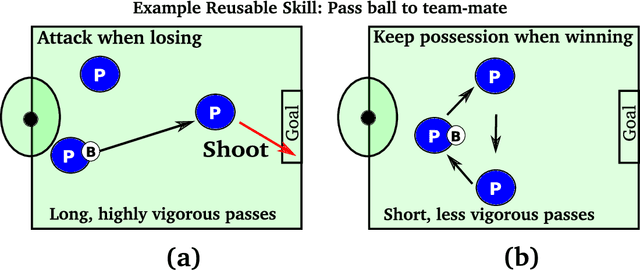
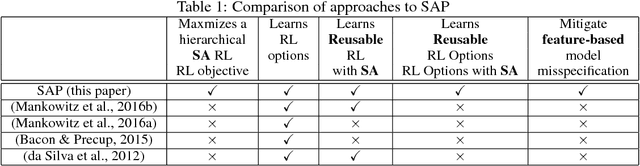
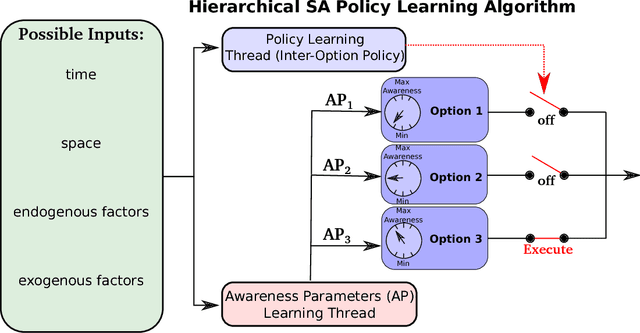
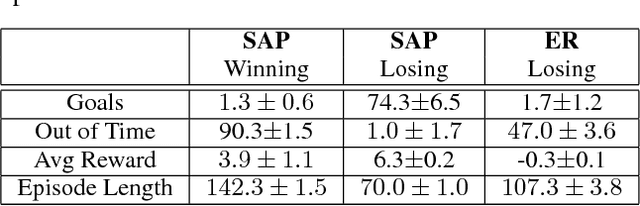
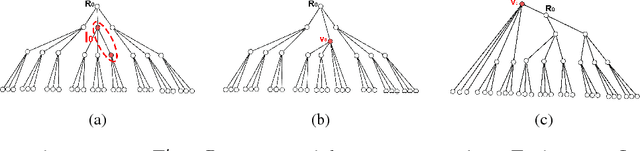
Hierarchical abstractions, also known as options -- a type of temporally extended action (Sutton et. al. 1999) that enables a reinforcement learning agent to plan at a higher level, abstracting away from the lower-level details. In this work, we learn reusable options whose parameters can vary, encouraging different behaviors, based on the current situation. In principle, these behaviors can include vigor, defence or even risk-averseness. These are some examples of what we refer to in the broader context as Situational Awareness (SA). We incorporate SA, in the form of vigor, into hierarchical RL by defining and learning situationally aware options in a Probabilistic Goal Semi-Markov Decision Process (PG-SMDP). This is achieved using our Situationally Aware oPtions (SAP) policy gradient algorithm which comes with a theoretical convergence guarantee. We learn reusable options in different scenarios in a RoboCup soccer domain (i.e., winning/losing). These options learn to execute with different levels of vigor resulting in human-like behaviours such as `time-wasting' in the winning scenario. We show the potential of the agent to exit bad local optima using reusable options in RoboCup. Finally, using SAP, the agent mitigates feature-based model misspecification in a Bottomless Pit of Death domain.
Ensemble Robustness and Generalization of Stochastic Deep Learning Algorithms
Nov 05, 2017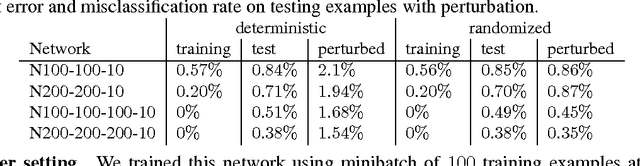
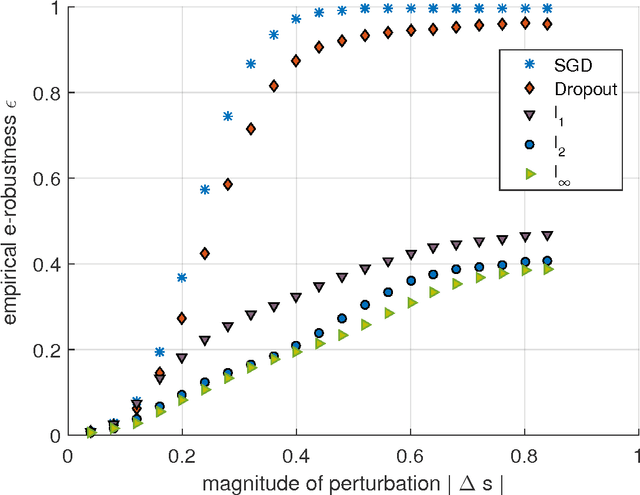
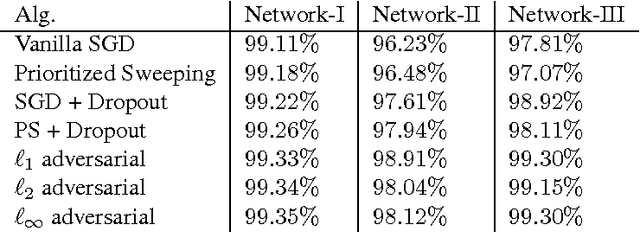

The question why deep learning algorithms generalize so well has attracted increasing research interest. However, most of the well-established approaches, such as hypothesis capacity, stability or sparseness, have not provided complete explanations (Zhang et al., 2016; Kawaguchi et al., 2017). In this work, we focus on the robustness approach (Xu & Mannor, 2012), i.e., if the error of a hypothesis will not change much due to perturbations of its training examples, then it will also generalize well. As most deep learning algorithms are stochastic (e.g., Stochastic Gradient Descent, Dropout, and Bayes-by-backprop), we revisit the robustness arguments of Xu & Mannor, and introduce a new approach, ensemble robustness, that concerns the robustness of a population of hypotheses. Through the lens of ensemble robustness, we reveal that a stochastic learning algorithm can generalize well as long as its sensitiveness to adversarial perturbations is bounded in average over training examples. Moreover, an algorithm may be sensitive to some adversarial examples (Goodfellow et al., 2015) but still generalize well. To support our claims, we provide extensive simulations for different deep learning algorithms and different network architectures exhibiting a strong correlation between ensemble robustness and the ability to generalize.
Shallow Updates for Deep Reinforcement Learning
Nov 02, 2017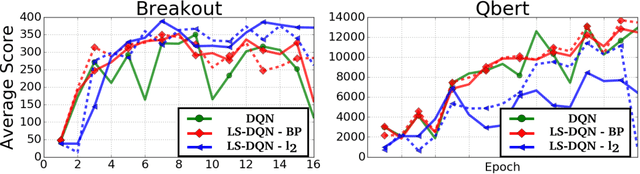


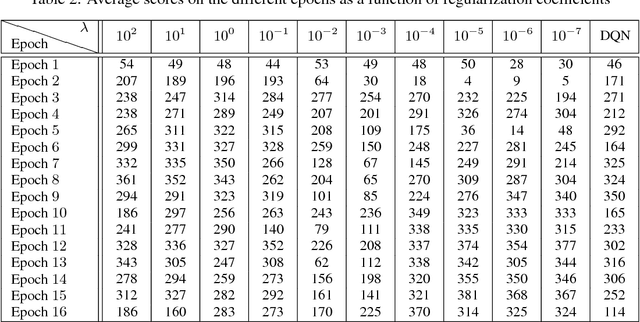
Deep reinforcement learning (DRL) methods such as the Deep Q-Network (DQN) have achieved state-of-the-art results in a variety of challenging, high-dimensional domains. This success is mainly attributed to the power of deep neural networks to learn rich domain representations for approximating the value function or policy. Batch reinforcement learning methods with linear representations, on the other hand, are more stable and require less hyper parameter tuning. Yet, substantial feature engineering is necessary to achieve good results. In this work we propose a hybrid approach -- the Least Squares Deep Q-Network (LS-DQN), which combines rich feature representations learned by a DRL algorithm with the stability of a linear least squares method. We do this by periodically re-training the last hidden layer of a DRL network with a batch least squares update. Key to our approach is a Bayesian regularization term for the least squares update, which prevents over-fitting to the more recent data. We tested LS-DQN on five Atari games and demonstrate significant improvement over vanilla DQN and Double-DQN. We also investigated the reasons for the superior performance of our method. Interestingly, we found that the performance improvement can be attributed to the large batch size used by the LS method when optimizing the last layer.
Rotting Bandits
Nov 02, 2017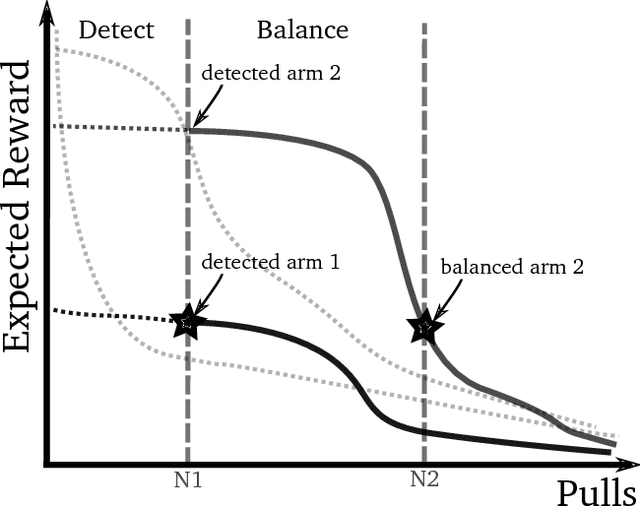
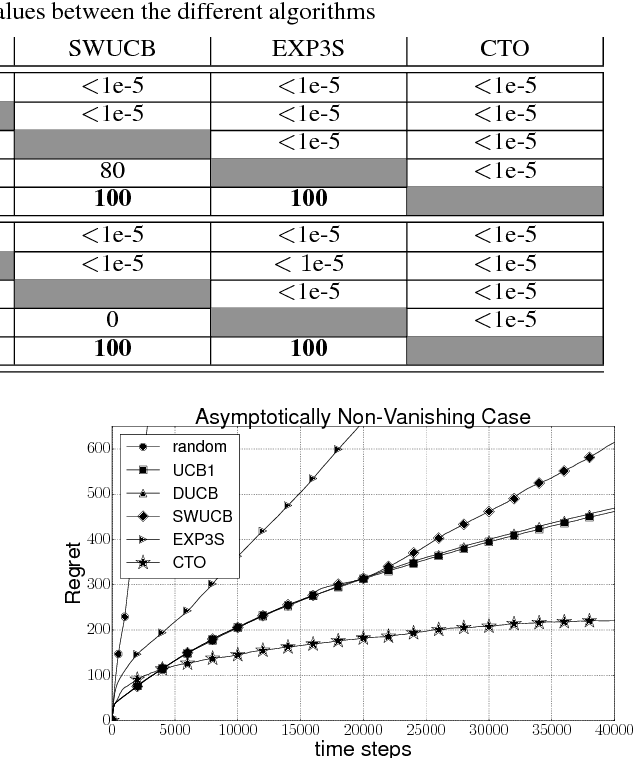
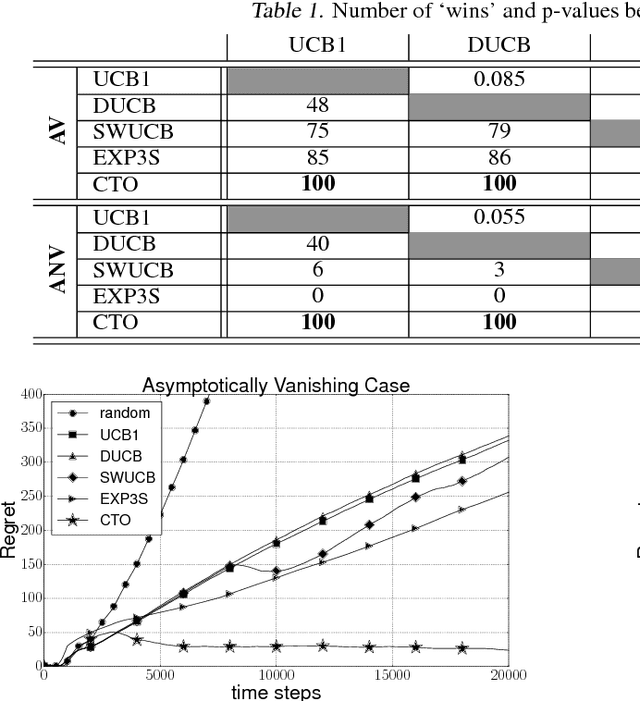
The Multi-Armed Bandits (MAB) framework highlights the tension between acquiring new knowledge (Exploration) and leveraging available knowledge (Exploitation). In the classical MAB problem, a decision maker must choose an arm at each time step, upon which she receives a reward. The decision maker's objective is to maximize her cumulative expected reward over the time horizon. The MAB problem has been studied extensively, specifically under the assumption of the arms' rewards distributions being stationary, or quasi-stationary, over time. We consider a variant of the MAB framework, which we termed Rotting Bandits, where each arm's expected reward decays as a function of the number of times it has been pulled. We are motivated by many real-world scenarios such as online advertising, content recommendation, crowdsourcing, and more. We present algorithms, accompanied by simulations, and derive theoretical guarantees.
A nonparametric sequential test for online randomized experiments
Jun 26, 2017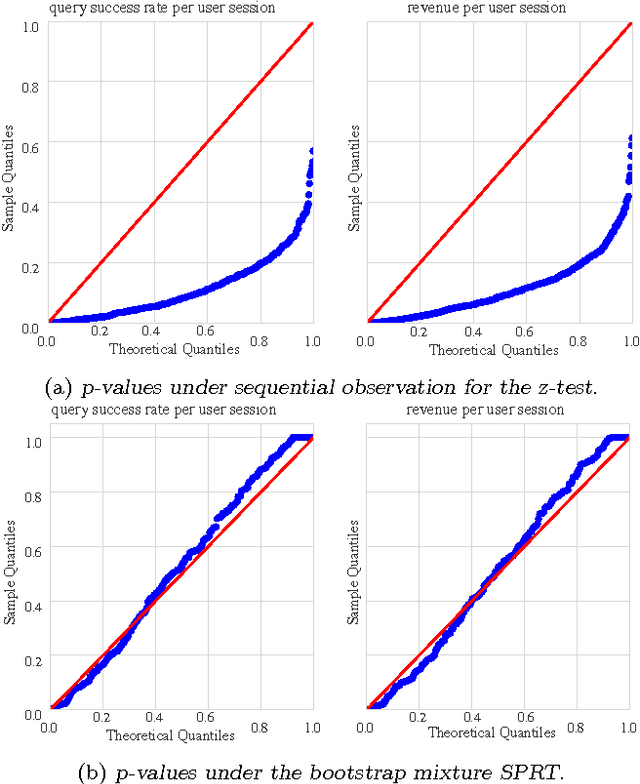
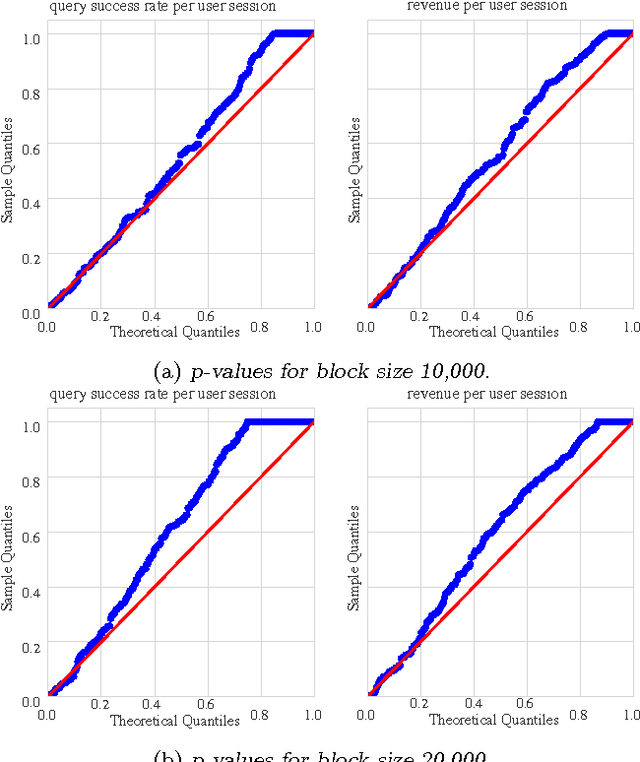
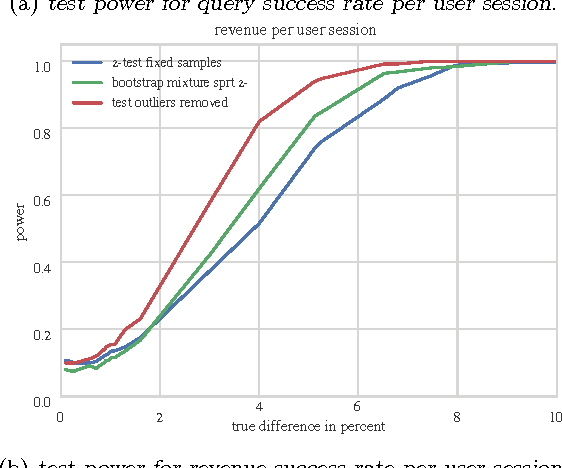
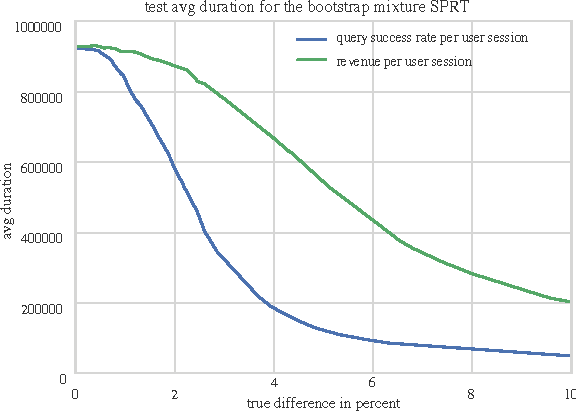
We propose a nonparametric sequential test that aims to address two practical problems pertinent to online randomized experiments: (i) how to do a hypothesis test for complex metrics; (ii) how to prevent type $1$ error inflation under continuous monitoring. The proposed test does not require knowledge of the underlying probability distribution generating the data. We use the bootstrap to estimate the likelihood for blocks of data followed by mixture sequential probability ratio test. We validate this procedure on data from a major online e-commerce website. We show that the proposed test controls type $1$ error at any time, has good power, is robust to misspecification in the distribution generating the data, and allows quick inference in online randomized experiments.
Multi-objective Bandits: Optimizing the Generalized Gini Index
Jun 15, 2017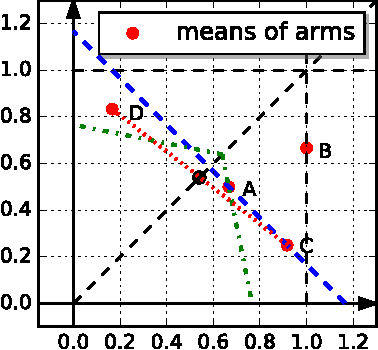
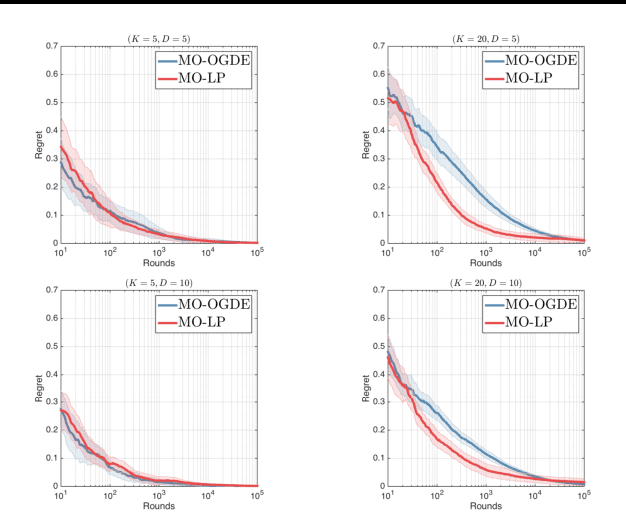
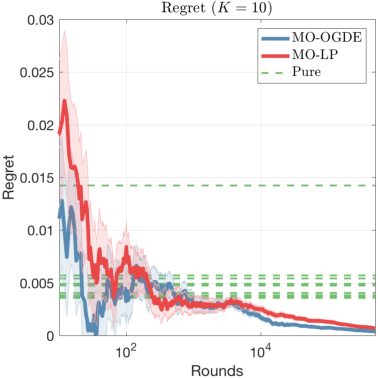
We study the multi-armed bandit (MAB) problem where the agent receives a vectorial feedback that encodes many possibly competing objectives to be optimized. The goal of the agent is to find a policy, which can optimize these objectives simultaneously in a fair way. This multi-objective online optimization problem is formalized by using the Generalized Gini Index (GGI) aggregation function. We propose an online gradient descent algorithm which exploits the convexity of the GGI aggregation function, and controls the exploration in a careful way achieving a distribution-free regret $\tilde{\bigO} (T^{-1/2} )$ with high probability. We test our algorithm on synthetic data as well as on an electric battery control problem where the goal is to trade off the use of the different cells of a battery in order to balance their respective degradation rates.
Graying the black box: Understanding DQNs
Apr 24, 2017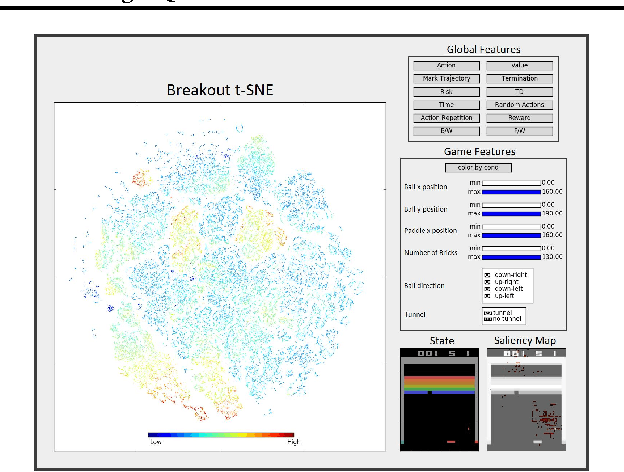
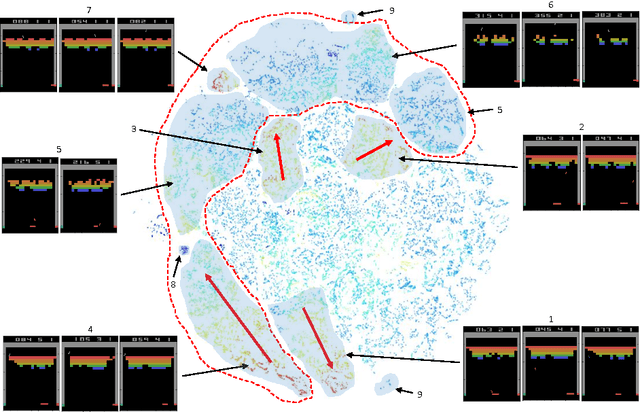

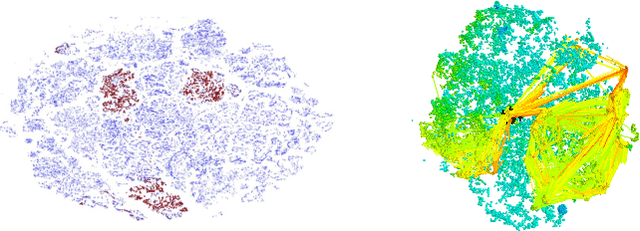
In recent years there is a growing interest in using deep representations for reinforcement learning. In this paper, we present a methodology and tools to analyze Deep Q-networks (DQNs) in a non-blind matter. Moreover, we propose a new model, the Semi Aggregated Markov Decision Process (SAMDP), and an algorithm that learns it automatically. The SAMDP model allows us to identify spatio-temporal abstractions directly from features and may be used as a sub-goal detector in future work. Using our tools we reveal that the features learned by DQNs aggregate the state space in a hierarchical fashion, explaining its success. Moreover, we are able to understand and describe the policies learned by DQNs for three different Atari2600 games and suggest ways to interpret, debug and optimize deep neural networks in reinforcement learning.