 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Latent Reasoning with Decoupled Policy Optimization
Apr 22, 2026Chain-of-Thought (CoT) reasoning significantly elevates the complex problem-solving capabilities of multimodal large language models (MLLMs). However, adapting CoT to vision typically discretizes signals to fit LLM inputs, causing early semantic collapse and discarding fine-grained details. While external tools can mitigate this, they introduce a rigid bottleneck, confining reasoning to predefined operations. Although recent latent reasoning paradigms internalize visual states to overcome these limitations, optimizing the resulting hybrid discrete-continuous action space remains challenging. In this work, we propose HyLaR (Hybrid Latent Reasoning), a framework that seamlessly interleaves discrete text generation with continuous visual latent representations. Specifically, following an initial cold-start supervised fine-tuning (SFT), we introduce DePO (Decoupled Policy Optimization) to enable effective reinforcement learning within this hybrid space. DePO decomposes the policy gradient objective, applying independent trust-region constraints to the textual and latent components, alongside an exact closed-form von Mises-Fisher (vMF) KL regularizer. Extensive experiments demonstrate that HyLaR outperforms standard MLLMs and state-of-the-art latent reasoning approaches across fine-grained perception and general multimodal understanding benchmarks. Code is available at https://github.com/EthenCheng/HyLaR.
Conan-Embedding-v2: Training an LLM from Scratch for Text Embeddings
Sep 16, 2025Large language models (LLMs) have recently demonstrated excellent performance in text embedding tasks. Previous work usually use LoRA to fine-tune existing LLMs, which are limited by the data and training gap between LLMs and embedding models. In this work, we introduce Conan-embedding-v2, a new 1.4B-parameter LLM trained from scratch and fine-tuned as a text embedder. First, we add news data and multilingual pairs for LLM pretraining to bridge the data gap. Based on this, we propose a cross-lingual retrieval dataset that enables the LLM to better integrate embeddings across different languages. Second, whereas LLMs use a causal mask with token-level loss, embedding models use a bidirectional mask with sentence-level loss. This training gap makes full fine-tuning less effective than LoRA. We introduce a soft-masking mechanism to gradually transition between these two types of masks, enabling the model to learn more comprehensive representations. Based on this, we propose a dynamic hard negative mining method that exposes the model to more difficult negative examples throughout the training process. Being intuitive and effective, with only approximately 1.4B parameters, Conan-embedding-v2 achieves SOTA performance on both the Massive Text Embedding Benchmark (MTEB) and Chinese MTEB (May 19, 2025).
Deep Ranking for Person Re-identification via Joint Representation Learning
Mar 23, 2016

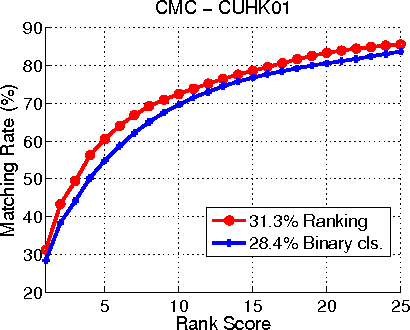
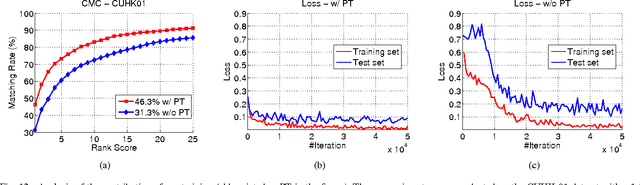
This paper proposes a novel approach to person re-identification, a fundamental task in distributed multi-camera surveillance systems. Although a variety of powerful algorithms have been presented in the past few years, most of them usually focus on designing hand-crafted features and learning metrics either individually or sequentially. Different from previous works, we formulate a unified deep ranking framework that jointly tackles both of these key components to maximize their strengths. We start from the principle that the correct match of the probe image should be positioned in the top rank within the whole gallery set. An effective learning-to-rank algorithm is proposed to minimize the cost corresponding to the ranking disorders of the gallery. The ranking model is solved with a deep convolutional neural network (CNN) that builds the relation between input image pairs and their similarity scores through joint representation learning directly from raw image pixels. The proposed framework allows us to get rid of feature engineering and does not rely on any assumption. An extensive comparative evaluation is given, demonstrating that our approach significantly outperforms all state-of-the-art approaches, including both traditional and CNN-based methods on the challenging VIPeR, CUHK-01 and CAVIAR4REID datasets. Additionally, our approach has better ability to generalize across datasets without fine-tuning.