 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggretriever: A Simple Approach to Aggregate Textual Representation for Robust Dense Passage Retrieval
Jul 31, 2022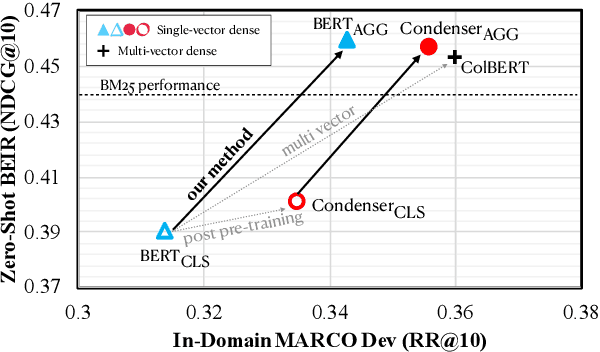
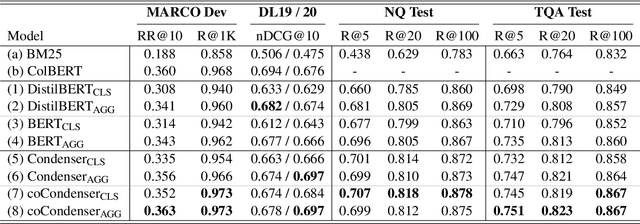
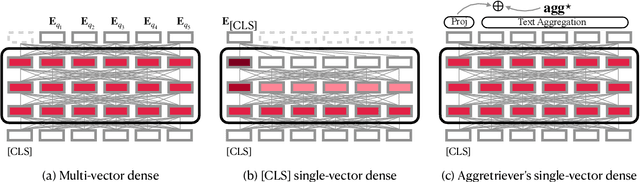
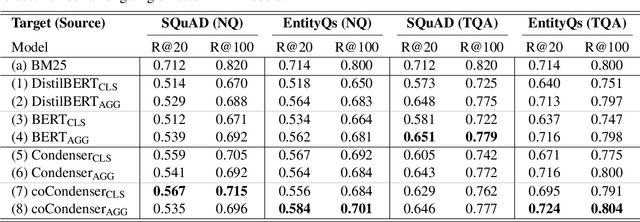
Pre-trained transformers has declared its success in many NLP tasks. One thread of work focuses on training bi-encoder models (i.e., dense retrievers) to effectively encode sentences or passages into single-vector dense vectors for efficient approximate nearest neighbor (ANN) search. However, recent work has demonstrated that transformers pre-trained with mask language modeling (MLM) are not capable of effectively aggregating text information into a single dense vector due to task-mismatch between pre-training and fine-tuning. Therefore, computationally expensive techniques have been adopted to train dense retrievers, such as large batch size, knowledge distillation or post pre-training. In this work, we present a simple approach to effectively aggregate textual representation from the pre-trained transformer into a dense vector. Extensive experiments show that our approach improves the robustness of the single-vector approach under both in-domain and zero-shot evaluations without any computationally expensive training techniques. Our work demonstrates that MLM pre-trained transformers can be used to effectively encode text information into a single-vector for dense retrieval. Code are available at: https://github.com/castorini/dhr
A Dense Representation Framework for Lexical and Semantic Matching
Jun 20, 2022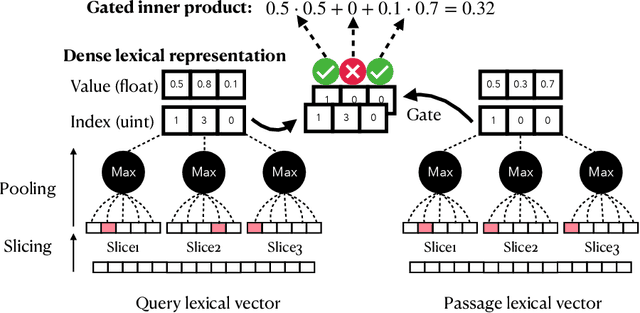

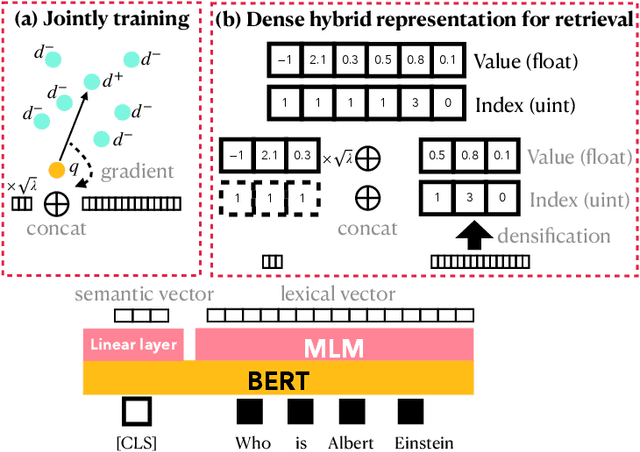

Lexical and semantic matching capture different successful approaches to text retrieval and the fusion of their results has proven to be more effective and robust than either alone. Prior work performs hybrid retrieval by conducting lexical and semantic text matching using different systems (e.g., Lucene and Faiss, respectively) and then fusing their model outputs. In contrast, our work integrates lexical representations with dense semantic representations by densifying high-dimensional lexical representations into what we call low-dimensional dense lexical representations (DLRs). Our experiments show that DLRs can effectively approximate the original lexical representations, preserving effectiveness while improving query latency. Furthermore, we can combine dense lexical and semantic representations to generate dense hybrid representations (DHRs) that are more flexible and yield faster retrieval compared to existing hybrid techniques. Finally, we explore {\it jointly} training lexical and semantic representations in a single model and empirically show that the resulting DHRs are able to combine the advantages of each individual component. Our best DHR model is competitive with state-of-the-art single-vector and multi-vector dense retrievers in both in-domain and zero-shot evaluation settings. Furthermore, our model is both faster and requires smaller indexes, making our dense representation framework an attractive approach to text retrieval. Our code is available at https://github.com/castorini/dhr.
Densifying Sparse Representations for Passage Retrieval by Representational Slicing
Dec 09, 2021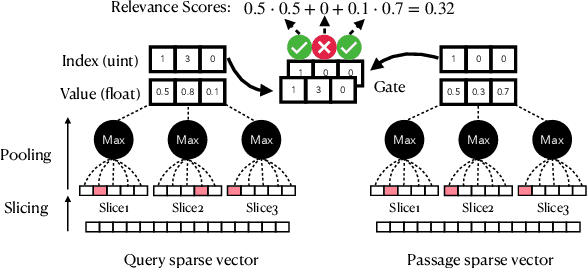
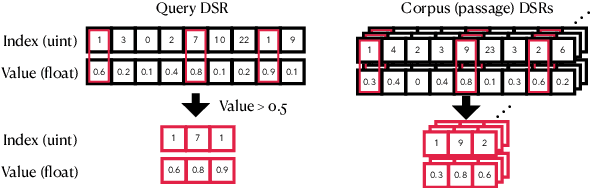
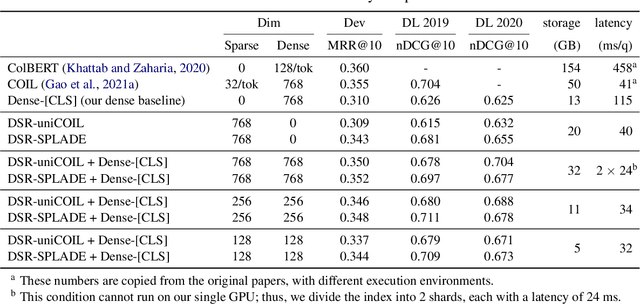
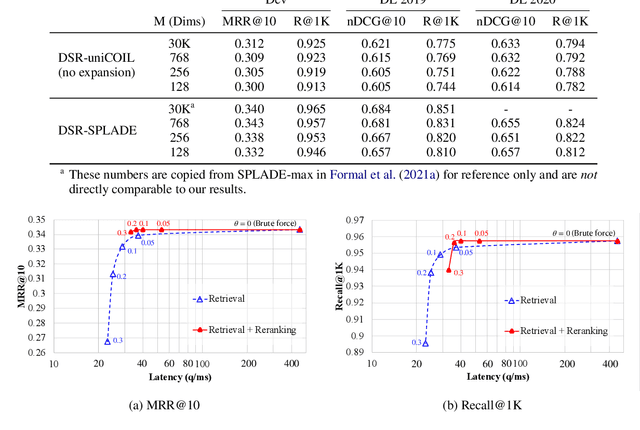
Learned sparse and dense representations capture different successful approaches to text retrieval and the fusion of their results has proven to be more effective and robust. Prior work combines dense and sparse retrievers by fusing their model scores. As an alternative, this paper presents a simple approach to densifying sparse representations for text retrieval that does not involve any training. Our densified sparse representations (DSRs) are interpretable and can be easily combined with dense representations for end-to-end retrieval. We demonstrate that our approach can jointly learn sparse and dense representations within a single model and then combine them for dense retrieval. Experimental results suggest that combining our DSRs and dense representations yields a balanced tradeoff between effectiveness and efficiency.
Contextualized Query Embeddings for Conversational Search
Apr 18, 2021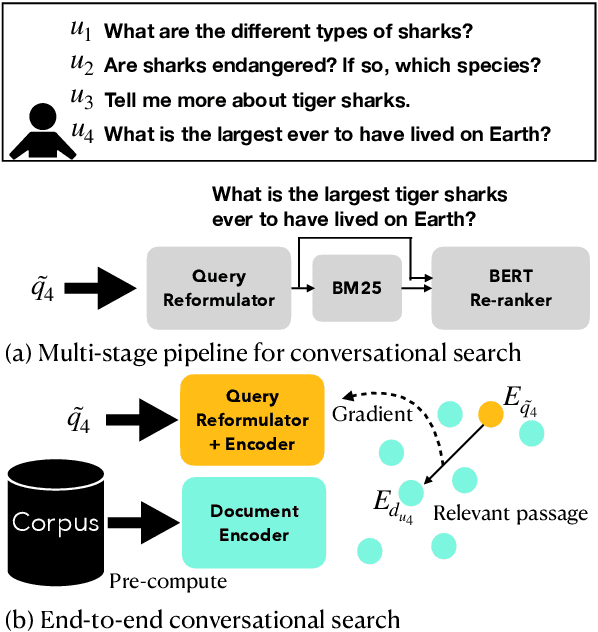
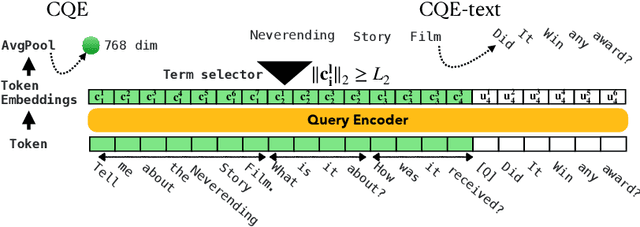
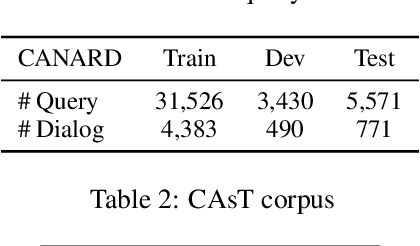
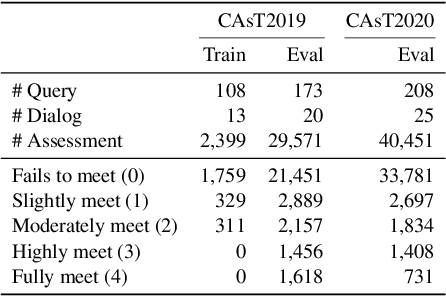
Conversational search (CS) plays a vital role in information retrieval. The current state of the art approaches the task using a multi-stage pipeline comprising conversational query reformulation and information seeking modules. Despite of its effectiveness, such a pipeline often comprises multiple neural models and thus requires long inference times. In addition, independently optimizing the effectiveness of each module does not consider the relation between modules in the pipeline. Thus, in this paper, we propose a single-stage design, which supports end-to-end training and low-latency inference. To aid in this goal, we create a synthetic dataset for CS to overcome the lack of training data and explore different training strategies using this dataset. Experiments demonstrate that our model yields competitive retrieval effectiveness against state-of-the-art multi-stage approaches but with lower latency. Furthermore, we show that improved retrieval effectiveness benefits the downstream task of conversational question answering.
Efficiently Teaching an Effective Dense Retriever with Balanced Topic Aware Sampling
Apr 14, 2021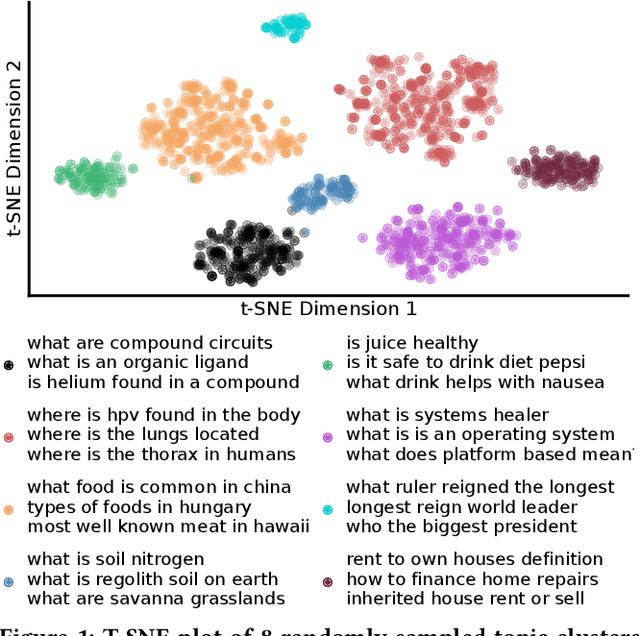
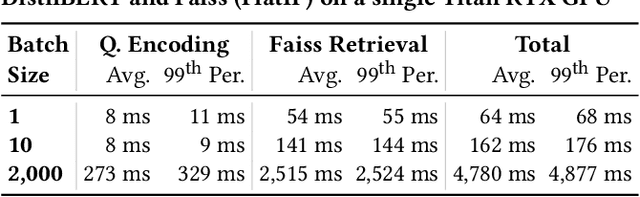
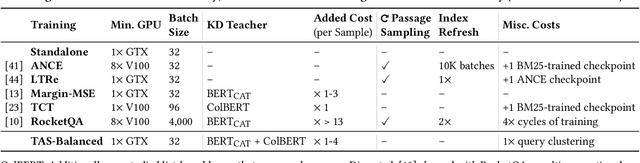
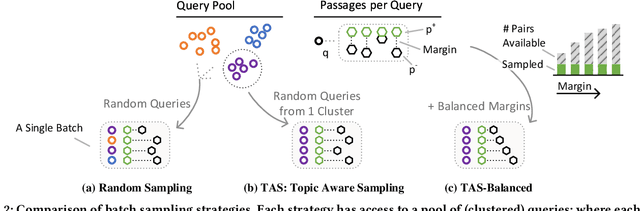
A vital step towards the widespread adoption of neural retrieval models is their resource efficiency throughout the training, indexing and query workflows. The neural IR community made great advancements in training effective dual-encoder dense retrieval (DR) models recently. A dense text retrieval model uses a single vector representation per query and passage to score a match, which enables low-latency first stage retrieval with a nearest neighbor search. Increasingly common, training approaches require enormous compute power, as they either conduct negative passage sampling out of a continuously updating refreshing index or require very large batch sizes for in-batch negative sampling. Instead of relying on more compute capability, we introduce an efficient topic-aware query and balanced margin sampling technique, called TAS-Balanced. We cluster queries once before training and sample queries out of a cluster per batch. We train our lightweight 6-layer DR model with a novel dual-teacher supervision that combines pairwise and in-batch negative teachers. Our method is trainable on a single consumer-grade GPU in under 48 hours (as opposed to a common configuration of 8x V100s). We show that our TAS-Balanced training method achieves state-of-the-art low-latency (64ms per query) results on two TREC Deep Learning Track query sets. Evaluated on NDCG@10, we outperform BM25 by 44%, a plainly trained DR by 19%, docT5query by 11%, and the previous best DR model by 5%. Additionally, TAS-Balanced produces the first dense retriever that outperforms every other method on recall at any cutoff on TREC-DL and allows more resource intensive re-ranking models to operate on fewer passages to improve results further.
Pyserini: An Easy-to-Use Python Toolkit to Support Replicable IR Research with Sparse and Dense Representations
Feb 19, 2021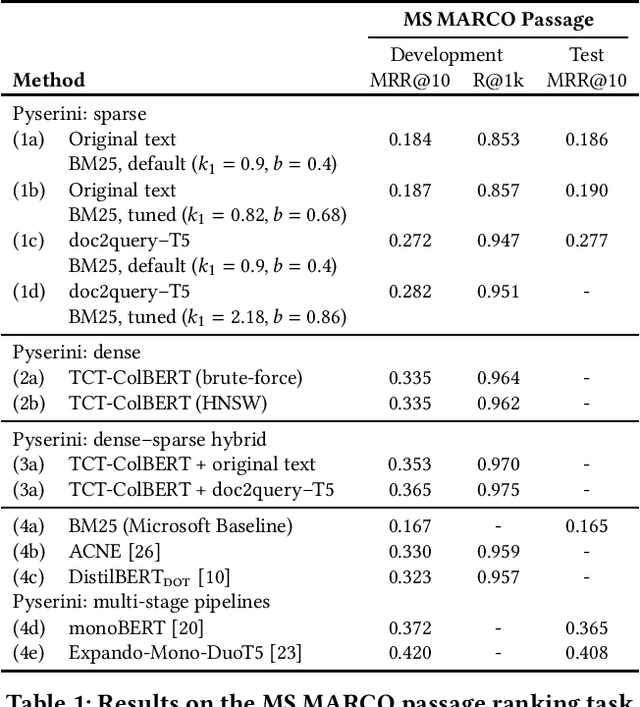
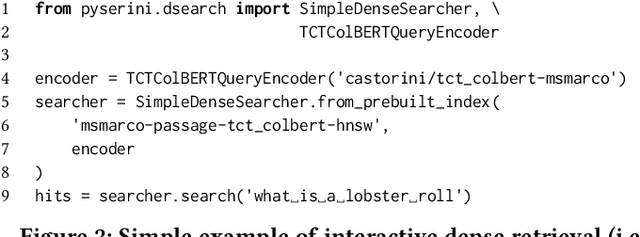
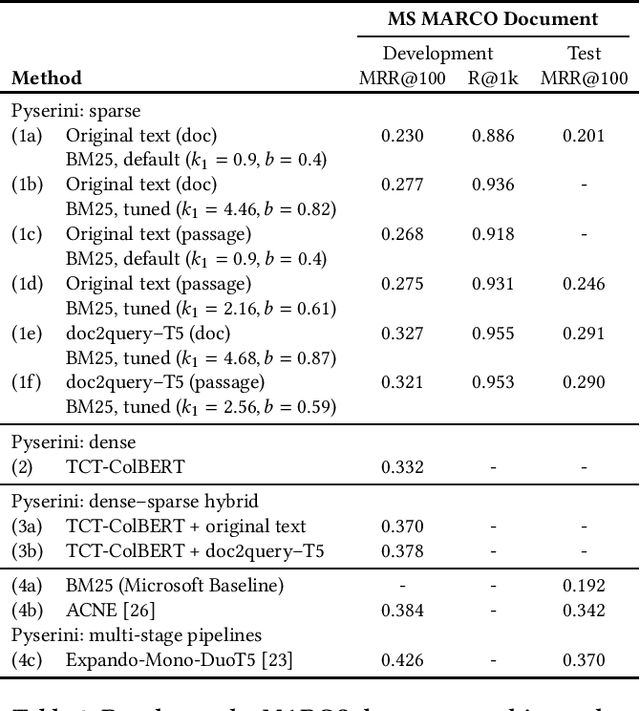
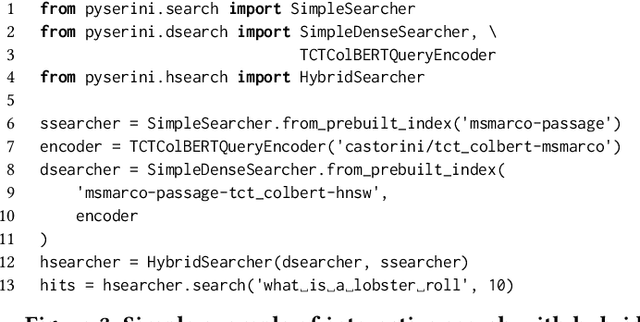
Pyserini is an easy-to-use Python toolkit that supports replicable IR research by providing effective first-stage retrieval in a multi-stage ranking architecture. Our toolkit is self-contained as a standard Python package and comes with queries, relevance judgments, pre-built indexes, and evaluation scripts for many commonly used IR test collections. We aim to support, out of the box, the entire research lifecycle of efforts aimed at improving ranking with modern neural approaches. In particular, Pyserini supports sparse retrieval (e.g., BM25 scoring using bag-of-words representations), dense retrieval (e.g., nearest-neighbor search on transformer-encoded representations), as well as hybrid retrieval that integrates both approaches. This paper provides an overview of toolkit features and presents empirical results that illustrate its effectiveness on two popular ranking tasks. We also describe how our group has built a culture of replicability through shared norms and tools that enable rigorous automated testing.
Optical Wavelength Guided Self-Supervised Feature Learning For Galaxy Cluster Richness Estimate
Dec 04, 2020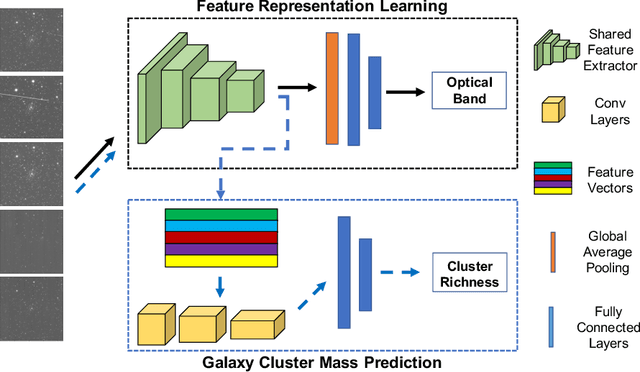
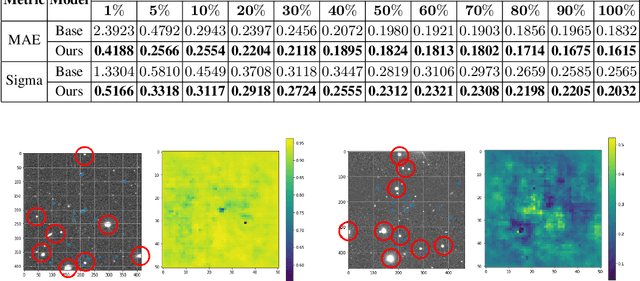
Most galaxies in the nearby Universe are gravitationally bound to a cluster or group of galaxies. Their optical contents, such as optical richness, are crucial for understanding the co-evolution of galaxies and large-scale structures in modern astronomy and cosmology. The determination of optical richness can be challenging. We propose a self-supervised approach for estimating optical richness from multi-band optical images. The method uses the data properties of the multi-band optical images for pre-training, which enables learning feature representations from a large but unlabeled dataset. We apply the proposed method to the Sloan Digital Sky Survey. The result shows our estimate of optical richness lowers the mean absolute error and intrinsic scatter by 11.84% and 20.78%, respectively, while reducing the need for labeled training data by up to 60%. We believe the proposed method will benefit astronomy and cosmology, where a large number of unlabeled multi-band images are available, but acquiring image labels is costly.
Distilling Dense Representations for Ranking using Tightly-Coupled Teachers
Oct 22, 2020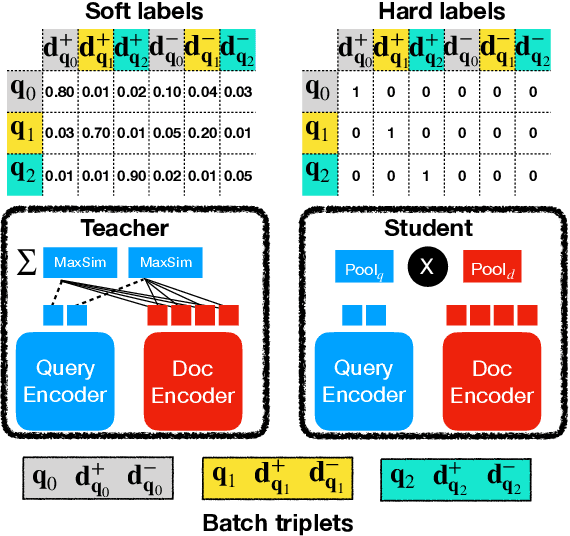
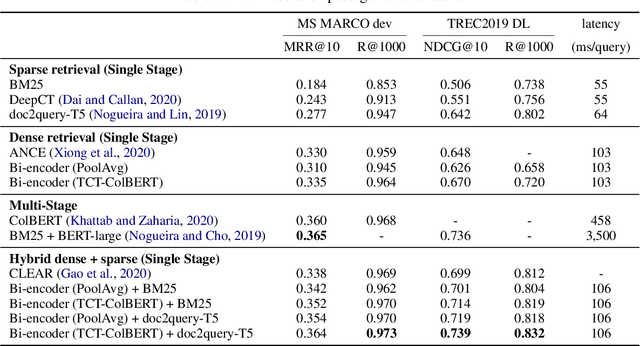

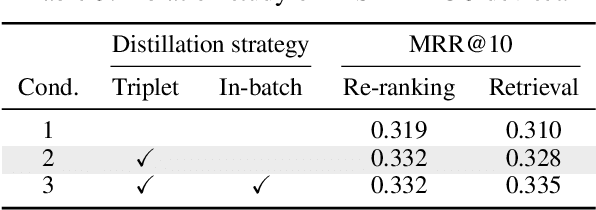
We present an approach to ranking with dense representations that applies knowledge distillation to improve the recently proposed late-interaction ColBERT model. Specifically, we distill the knowledge from ColBERT's expressive MaxSim operator for computing relevance scores into a simple dot product, thus enabling single-step ANN search. Our key insight is that during distillation, tight coupling between the teacher model and the student model enables more flexible distillation strategies and yields better learned representations. We empirically show that our approach improves query latency and greatly reduces the onerous storage requirements of ColBERT, while only making modest sacrifices in terms of effectiveness. By combining our dense representations with sparse representations derived from document expansion, we are able to approach the effectiveness of a standard cross-encoder reranker using BERT that is orders of magnitude slower.
Personalized TV Recommendation: Fusing User Behavior and Preferences
Aug 30, 2020
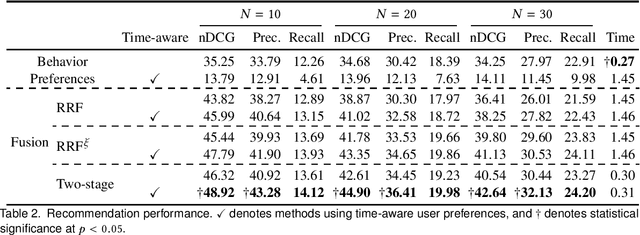
In this paper, we propose a two-stage ranking approach for recommending linear TV programs. The proposed approach first leverages user viewing patterns regarding time and TV channels to identify potential candidates for recommendation and then further leverages user preferences to rank these candidates given textual information about programs. To evaluate the method, we conduct empirical studies on a real-world TV dataset, the results of which demonstrate the superior performance of our model in terms of both recommendation accuracy and time efficiency.
Query Reformulation using Query History for Passage Retrieval in Conversational Search
May 05, 2020
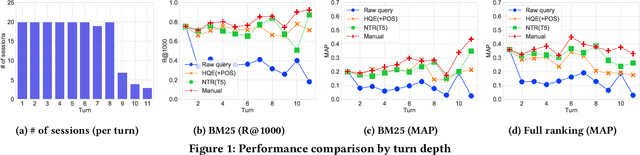
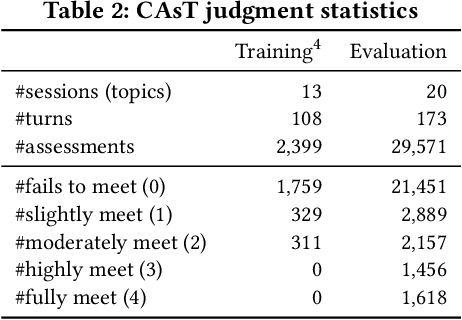
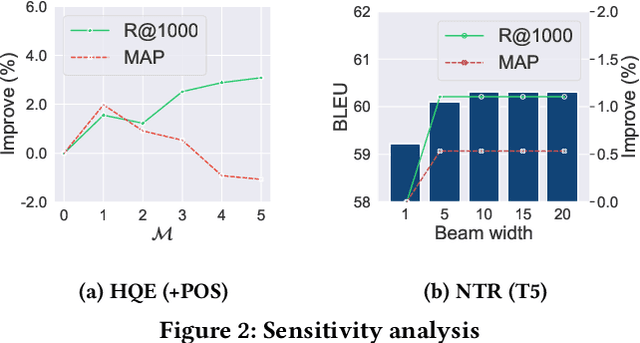
Passage retrieval in a conversational context is essential for many downstream applications; it is however extremely challenging due to limited data resources. To address this problem, we present an effective multi-stage pipeline for passage ranking in conversational search that integrates a widely-used IR system with a conversational query reformulation module. Along these lines, we propose two simple yet effective query reformulation approaches: historical query expansion (HQE) and neural transfer reformulation (NTR). Whereas HQE applies query expansion, a traditional IR query reformulation technique, NTR transfers human knowledge of conversational query understanding to a neural query reformulation model. The proposed HQE method was the top-performing submission of automatic systems in CAsT Track at TREC 2019. Building on this, our NTR approach improves an additional 18% over that best entry in terms of NDCG@3. We further analyze the distinct behaviors of the two approaches, and show that fusing their output reduces the performance gap (measured in NDCG@3) between the manually-rewritten and automatically-generated queries to 4 from 22 points when compared with the best CAsT submission.