 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Dense Representations for Ranking using Tightly-Coupled Teachers
Paper and Code
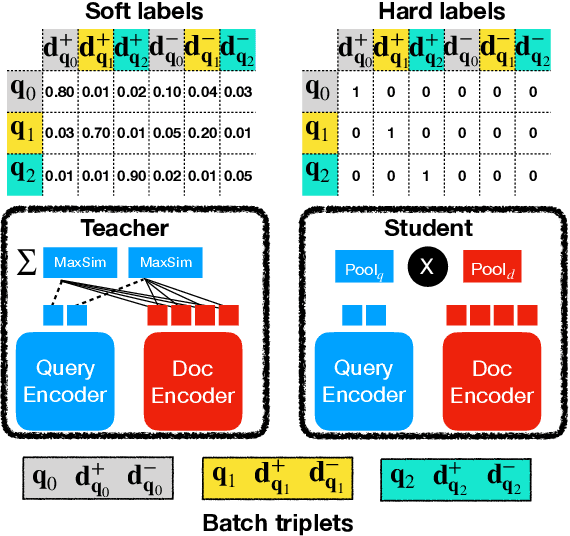
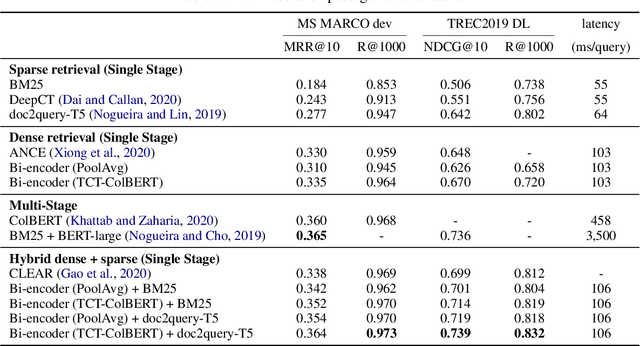

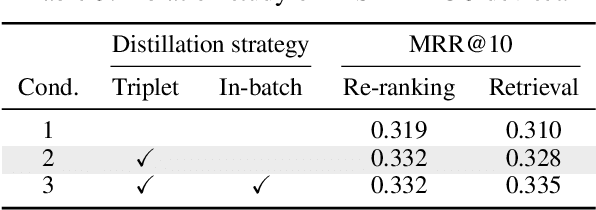
We present an approach to ranking with dense representations that applies knowledge distillation to improve the recently proposed late-interaction ColBERT model. Specifically, we distill the knowledge from ColBERT's expressive MaxSim operator for computing relevance scores into a simple dot product, thus enabling single-step ANN search. Our key insight is that during distillation, tight coupling between the teacher model and the student model enables more flexible distillation strategies and yields better learned representations. We empirically show that our approach improves query latency and greatly reduces the onerous storage requirements of ColBERT, while only making modest sacrifices in terms of effectiveness. By combining our dense representations with sparse representations derived from document expansion, we are able to approach the effectiveness of a standard cross-encoder reranker using BERT that is orders of magnitude slower.