 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Social Explanations for Stochastic Sequential Multi-Agent Decision-Making
Feb 21, 2023We present a novel framework to generate causal explanations for the decisions of agents in stochastic sequential multi-agent environments. Explanations are given via natural language conversations answering a wide range of user queries and requiring associative, interventionist, or counterfactual causal reasoning. Instead of assuming any specific causal graph, our method relies on a generative model of interactions to simulate counterfactual worlds which are used to identify the salient causes behind decisions. We implement our method for motion planning for autonomous driving and test it in simulated scenarios with coupled interactions. Our method correctly identifies and ranks the relevant causes and delivers concise explanations to the users' queries.
BERT is not The Count: Learning to Match Mathematical Statements with Proofs
Feb 18, 2023We introduce a task consisting in matching a proof to a given mathematical statement. The task fits well within current research on Mathematical Information Retrieval and, more generally, mathematical article analysis (Mathematical Sciences, 2014). We present a dataset for the task (the MATcH dataset) consisting of over 180k statement-proof pairs extracted from modern mathematical research articles. We find this dataset highly representative of our task, as it consists of relatively new findings useful to mathematicians. We propose a bilinear similarity model and two decoding methods to match statements to proofs effectively. While the first decoding method matches a proof to a statement without being aware of other statements or proofs, the second method treats the task as a global matching problem. Through a symbol replacement procedure, we analyze the "insights" that pre-trained language models have in such mathematical article analysis and show that while these models perform well on this task with the best performing mean reciprocal rank of 73.7, they follow a relatively shallow symbolic analysis and matching to achieve that performance.
Abstractive Summarization Guided by Latent Hierarchical Document Structure
Nov 17, 2022Sequential abstractive neural summarizers often do not use the underlying structure in the input article or dependencies between the input sentences. This structure is essential to integrate and consolidate information from different parts of the text. To address this shortcoming, we propose a hierarchy-aware graph neural network (HierGNN) which captures such dependencies through three main steps: 1) learning a hierarchical document structure through a latent structure tree learned by a sparse matrix-tree computation; 2) propagating sentence information over this structure using a novel message-passing node propagation mechanism to identify salient information; 3) using graph-level attention to concentrate the decoder on salient information. Experiments confirm HierGNN improves strong sequence models such as BART, with a 0.55 and 0.75 margin in average ROUGE-1/2/L for CNN/DM and XSum. Further human evaluation demonstrates that summaries produced by our model are more relevant and less redundant than the baselines, into which HierGNN is incorporated. We also find HierGNN synthesizes summaries by fusing multiple source sentences more, rather than compressing a single source sentence, and that it processes long inputs more effectively.
Understanding Domain Learning in Language Models Through Subpopulation Analysis
Oct 22, 2022



We investigate how different domains are encoded in modern neural network architectures. We analyze the relationship between natural language domains, model size, and the amount of training data used. The primary analysis tool we develop is based on subpopulation analysis with Singular Vector Canonical Correlation Analysis (SVCCA), which we apply to Transformer-based language models (LMs). We compare the latent representations of such a language model at its different layers from a pair of models: a model trained on multiple domains (an experimental model) and a model trained on a single domain (a control model). Through our method, we find that increasing the model capacity impacts how domain information is stored in upper and lower layers differently. In addition, we show that larger experimental models simultaneously embed domain-specific information as if they were conjoined control models. These findings are confirmed qualitatively, demonstrating the validity of our method.
A Human-Centric Method for Generating Causal Explanations in Natural Language for Autonomous Vehicle Motion Planning
Jun 27, 2022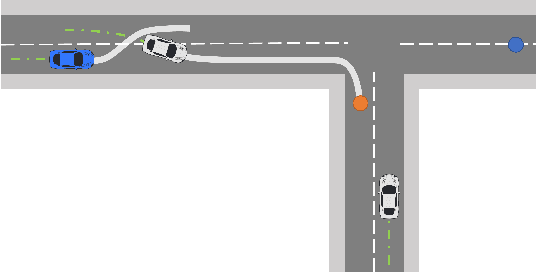
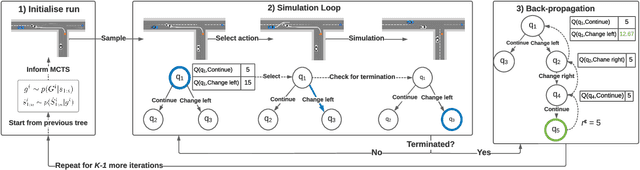
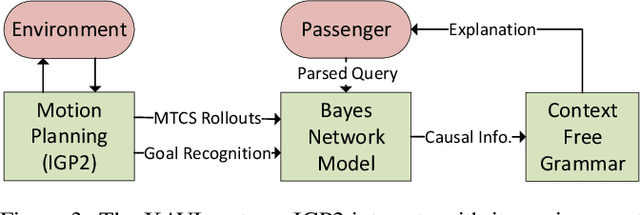
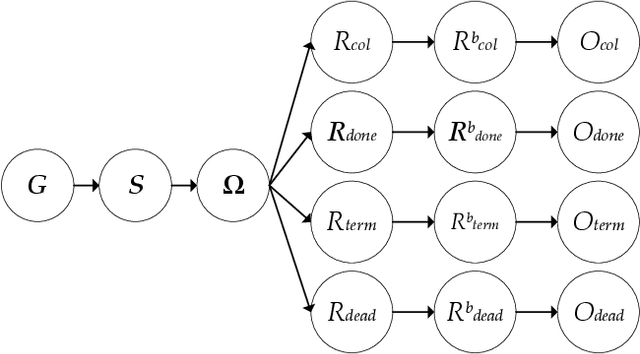
Inscrutable AI systems are difficult to trust, especially if they operate in safety-critical settings like autonomous driving. Therefore, there is a need to build transparent and queryable systems to increase trust levels. We propose a transparent, human-centric explanation generation method for autonomous vehicle motion planning and prediction based on an existing white-box system called IGP2. Our method integrates Bayesian networks with context-free generative rules and can give causal natural language explanations for the high-level driving behaviour of autonomous vehicles. Preliminary testing on simulated scenarios shows that our method captures the causes behind the actions of autonomous vehicles and generates intelligible explanations with varying complexity.
Factorizing Content and Budget Decisions in Abstractive Summarization of Long Documents by Sampling Summary Views
May 25, 2022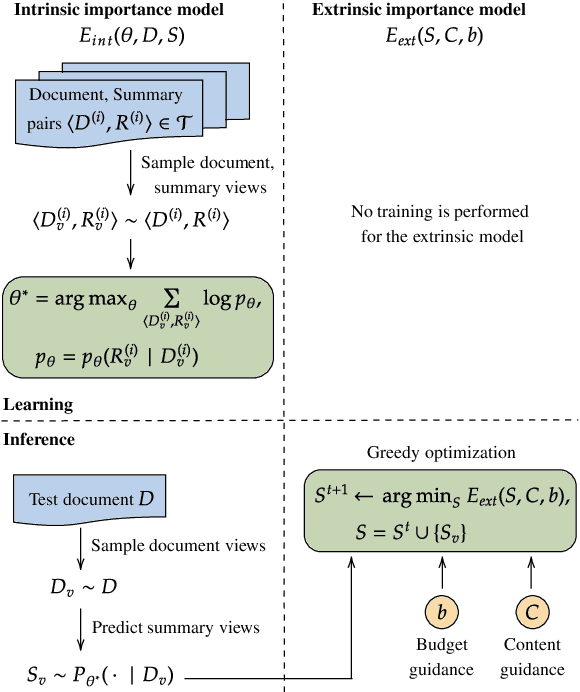
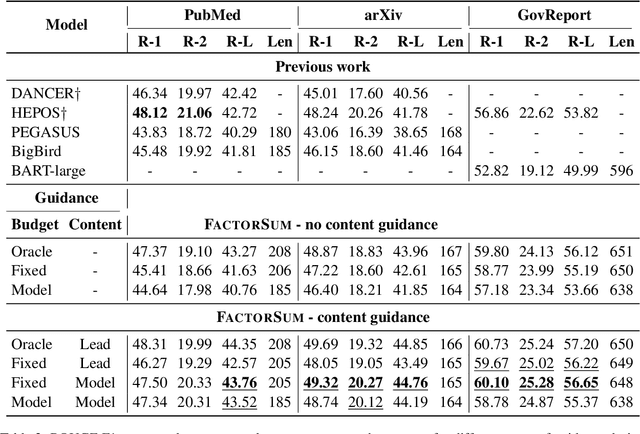
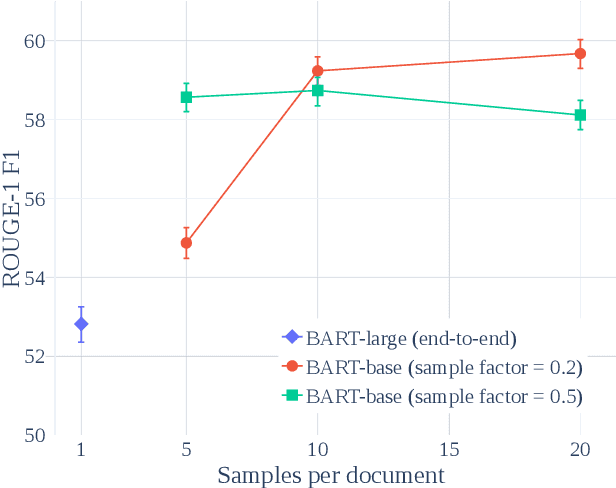
We argue that disentangling content selection from the budget used to cover salient content improves the performance and applicability of abstractive summarizers. Our method, FactorSum, does this disentanglement by factorizing summarization into two steps through an energy function: (1) generation of abstractive summary views; (2) combination of these views into a final summary, following a budget and content guidance. This guidance may come from different sources, including from an advisor model such as BART or BigBird, or in oracle mode -- from the reference. This factorization achieves significantly higher ROUGE scores on multiple benchmarks for long document summarization, namely PubMed, arXiv, and GovReport. Most notably, our model is effective for domain adaptation. When trained only on PubMed samples, it achieves a 46.29 ROUGE-1 score on arXiv, which indicates a strong performance due to more flexible budget adaptation and content selection less dependent on domain-specific textual structure.
On the Trade-off between Redundancy and Local Coherence in Summarization
May 20, 2022
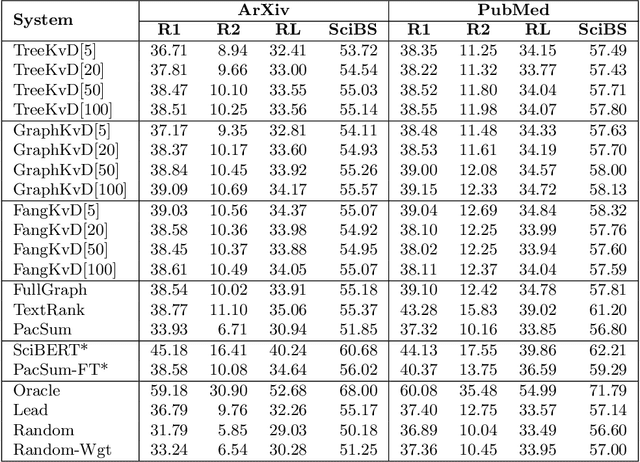

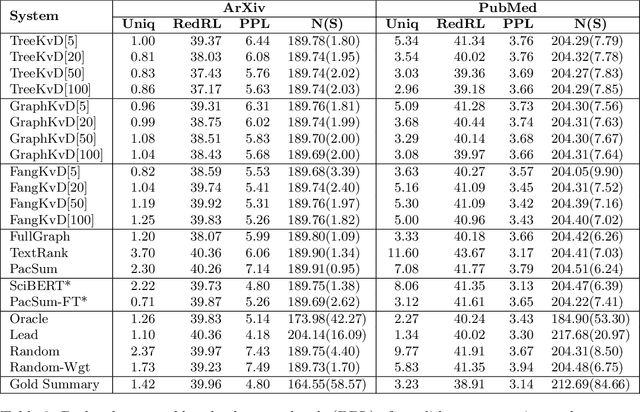
Extractive summarization systems are known to produce poorly coherent and, if not accounted for, highly redundant text. In this work, we tackle the problem of summary redundancy in unsupervised extractive summarization of long, highly-redundant documents. For this, we leverage a psycholinguistic theory of human reading comprehension which directly models local coherence and redundancy. Implementing this theory, our system operates at the proposition level and exploits properties of human memory representations to rank similarly content units that are coherent and non-redundant, hence encouraging the extraction of less redundant final summaries. Because of the impact of the summary length on automatic measures, we control for it by formulating content selection as an optimization problem with soft constraints in the budget of information retrieved. Using summarization of scientific articles as a case study, extensive experiments demonstrate that the proposed systems extract consistently less redundant summaries across increasing levels of document redundancy, whilst maintaining comparable performance (in terms of relevancy and local coherence) against strong unsupervised baselines according to automated evaluations.
Gold Doesn't Always Glitter: Spectral Removal of Linear and Nonlinear Guarded Attribute Information
Mar 15, 2022
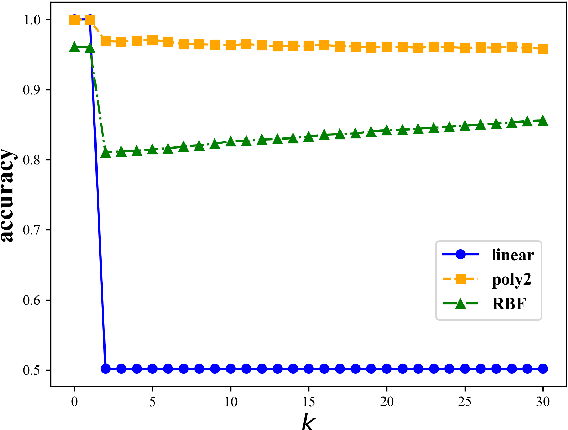

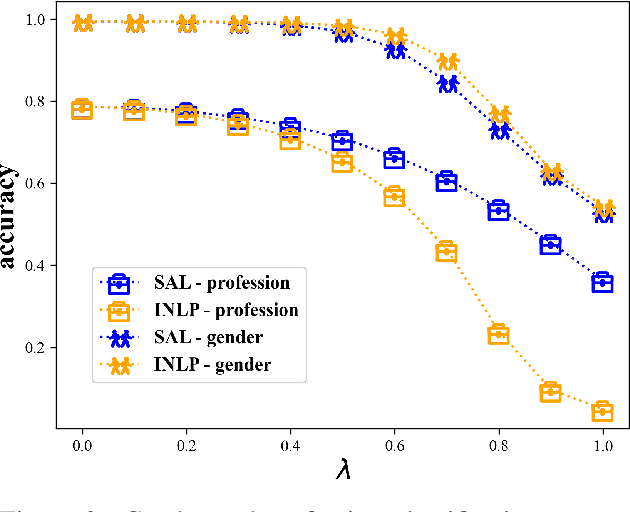
We describe a simple and effective method (Spectral Attribute removaL; SAL) to remove guarded information from neural representations. Our method uses singular value decomposition and eigenvalue decomposition to project the input representations into directions with reduced covariance with the guarded information rather than maximal covariance as normally these factorization methods are used. We begin with linear information removal and proceed to generalize our algorithm to the case of nonlinear information removal through the use of kernels. Our experiments demonstrate that our algorithm retains better main task performance after removing the guarded information compared to previous methods. In addition, our experiments demonstrate that we need a relatively small amount of guarded attribute data to remove information about these attributes, which lowers the exposure to such possibly sensitive data and fits better low-resource scenarios.
Co-training an Unsupervised Constituency Parser with Weak Supervision
Oct 05, 2021
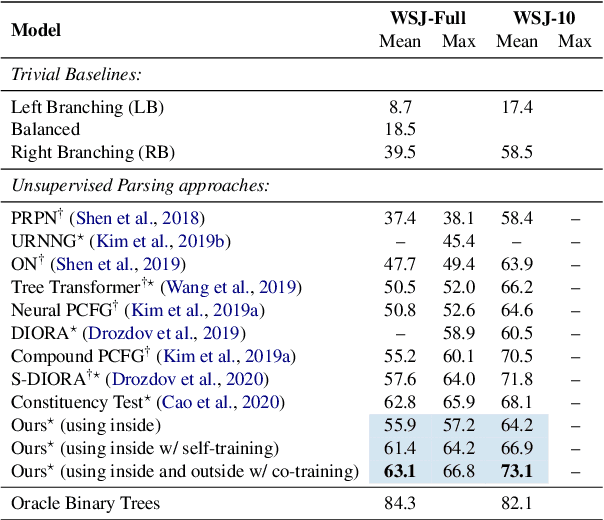

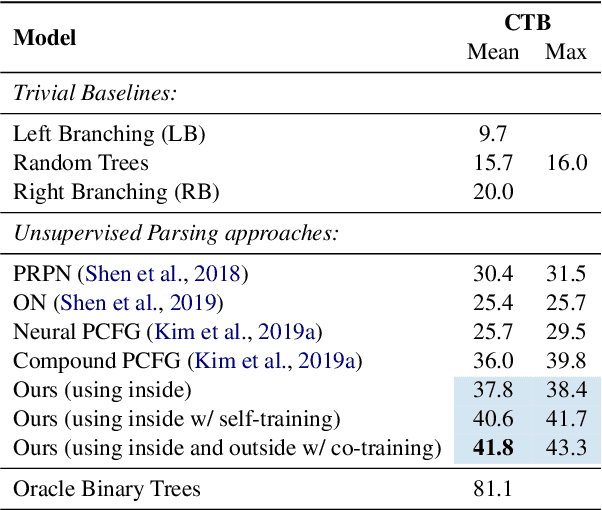
We introduce a method for unsupervised parsing that relies on bootstrapping classifiers to identify if a node dominates a specific span in a sentence. There are two types of classifiers, an inside classifier that acts on a span, and an outside classifier that acts on everything outside of a given span. Through self-training and co-training with the two classifiers, we show that the interplay between them helps improve the accuracy of both, and as a result, effectively parse. A seed bootstrapping technique prepares the data to train these classifiers. Our analyses further validate that such an approach in conjunction with weak supervision using prior branching knowledge of a known language (left/right-branching) and minimal heuristics injects strong inductive bias into the parser, achieving 63.1 F$_1$ on the English (PTB) test set. In addition, we show the effectiveness of our architecture by evaluating on treebanks for Chinese (CTB) and Japanese (KTB) and achieve new state-of-the-art results.\footnote{For code or data, please contact the authors.}
Unsupervised Extractive Summarization by Human Memory Simulation
Apr 16, 2021
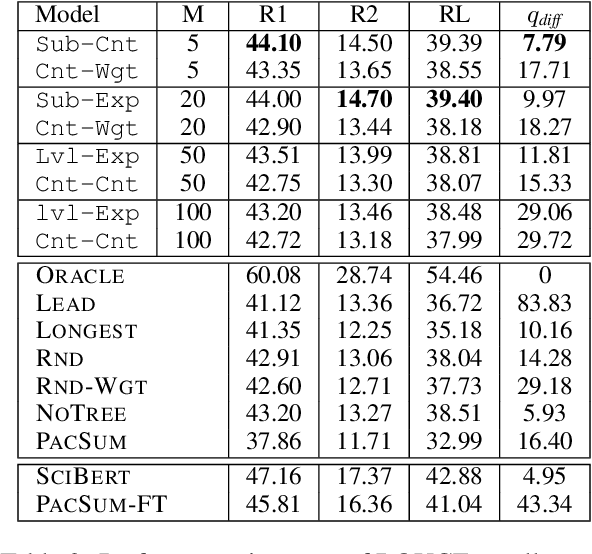
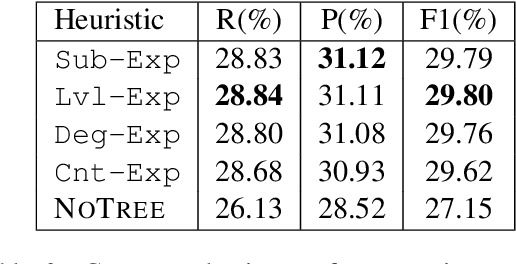
Summarization systems face the core challenge of identifying and selecting important information. In this paper, we tackle the problem of content selection in unsupervised extractive summarization of long, structured documents. We introduce a wide range of heuristics that leverage cognitive representations of content units and how these are retained or forgotten in human memory. We find that properties of these representations of human memory can be exploited to capture relevance of content units in scientific articles. Experiments show that our proposed heuristics are effective at leveraging cognitive structures and the organization of the document (i.e.\ sections of an article), and automatic and human evaluations provide strong evidence that these heuristics extract more summary-worthy content units.