 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBD: A Model-Based Debiasing Framework Across User, Content, and Model Dimensions
Mar 15, 2026Modern recommendation systems rank candidates by aggregating multiple behavioral signals through a value model. However, many commonly used signals are inherently affected by heterogeneous biases. For example, watch time naturally favors long-form content, loop rate favors short - form content, and comment probability favors videos over images. Such biases introduce two critical issues: (1) value model scores may be systematically misaligned with users' relative preferences - for instance, a seemingly low absolute like probability may represent exceptionally strong interest for a user who rarely engages; and (2) changes in value modeling rules can trigger abrupt and undesirable ecosystem shifts. In this work, we ask a fundamental question: can biased behavioral signals be systematically transformed into unbiased signals, under a user - defined notion of ``unbiasedness'', that are both personalized and adaptive? We propose a general, model-based debiasing (MBD) framework that addresses this challenge by augmenting it with distributional modeling. By conditioning on a flexible subset of features (partial feature set), we explicitly estimate the contextual mean and variance of the engagement distribution for arbitrary cohorts (e.g., specific video lengths or user regions) directly alongside the main prediction. This integration allows the framework to convert biased raw signals into unbiased representations, enabling the construction of higher-level, calibrated signals (such as percentiles or z - scores) suitable for the value model. Importantly, the definition of unbiasedness is flexible and controllable, allowing the system to adapt to different personalization objectives and modeling preferences. Crucially, this is implemented as a lightweight, built-in branch of the existing MTML ranking model, requiring no separate serving infrastructure.
A Performance Guarantee for Spectral Clustering
Jul 10, 2020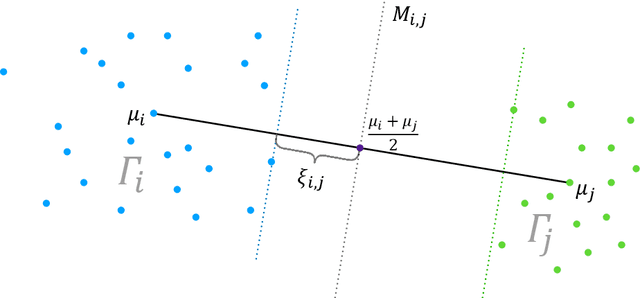
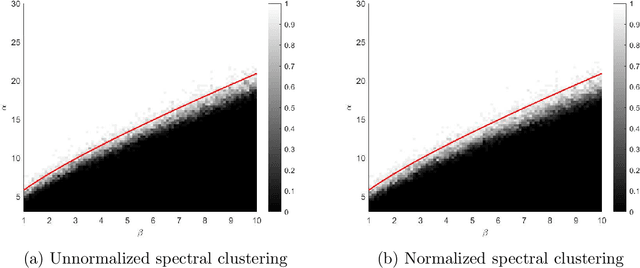
The two-step spectral clustering method, which consists of the Laplacian eigenmap and a rounding step, is a widely used method for graph partitioning. It can be seen as a natural relaxation to the NP-hard minimum ratio cut problem. In this paper we study the central question: when is spectral clustering able to find the global solution to the minimum ratio cut problem? First we provide a condition that naturally depends on the intra- and inter-cluster connectivities of a given partition under which we may certify that this partition is the solution to the minimum ratio cut problem. Then we develop a deterministic two-to-infinity norm perturbation bound for the the invariant subspace of the graph Laplacian that corresponds to the $k$ smallest eigenvalues. Finally by combining these two results we give a condition under which spectral clustering is guaranteed to output the global solution to the minimum ratio cut problem, which serves as a performance guarantee for spectral clustering.
Strong Consistency, Graph Laplacians, and the Stochastic Block Model
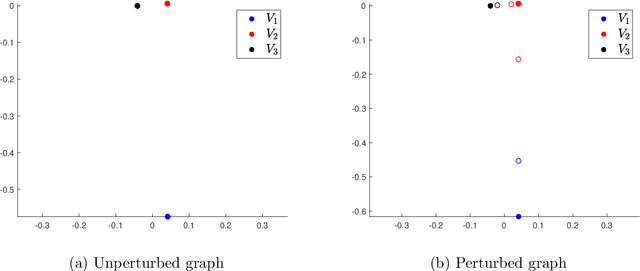
Apr 21, 2020
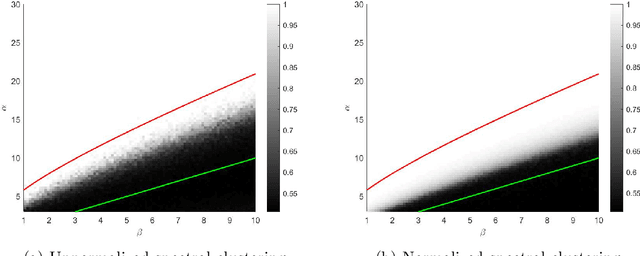
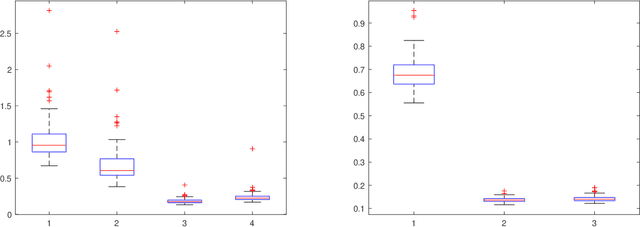
Spectral clustering has become one of the most popular algorithms in data clustering and community detection. We study the performance of classical two-step spectral clustering via the graph Laplacian to learn the stochastic block model. Our aim is to answer the following question: when is spectral clustering via the graph Laplacian able to achieve strong consistency, i.e., the exact recovery of the underlying hidden communities? Our work provides an entrywise analysis (an $\ell_{\infty}$-norm perturbation bound) of the Fielder eigenvector of both the unnormalized and the normalized Laplacian associated with the adjacency matrix sampled from the stochastic block model. We prove that spectral clustering is able to achieve exact recovery of the planted community structure under conditions that match the information-theoretic limits.