 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritic in the Loop: A Tri-System VLA Framework for Robust Long-Horizon Manipulation
Mar 05, 2026Balancing high-level semantic reasoning with low-level reactive control remains a core challenge in visual robotic manipulation. While Vision-Language Models (VLMs) excel at cognitive planning, their inference latency precludes real-time execution. Conversely, fast Vision-Language-Action (VLA) models often lack the semantic depth required for complex, long-horizon tasks. To bridge this gap, we introduce Critic in the Loop, an adaptive hierarchical framework driven by dynamic VLM-Expert scheduling. At its core is a bionic Tri-System architecture comprising a VLM brain for global reasoning, a VLA cerebellum for reactive execution, and a lightweight visual Critic. By continuously monitoring the workspace, the Critic dynamically routes control authority. It sustains rapid closed-loop execution via the VLA for routine subtasks, and adaptively triggers the VLM for replanning upon detecting execution anomalies such as task stagnation or failures. Furthermore, our architecture seamlessly integrates human-inspired rules to intuitively break infinite retry loops. This visually-grounded scheduling minimizes expensive VLM queries, while substantially enhancing system robustness and autonomy in out-of-distribution (OOD) scenarios. Comprehensive experiments on challenging, long-horizon manipulation benchmarks reveal that our approach achieves state-of-the-art performance.
Multi-directional Safe Rectangle Corridor-Based MPC for Nonholonomic Robots Navigation in Cluttered Environment
Dec 15, 2025Autonomous Mobile Robots (AMRs) have become indispensable in industrial applications due to their operational flexibility and efficiency. Navigation serves as a crucial technical foundation for accomplishing complex tasks. However, navigating AMRs in dense, cluttered, and semi-structured environments remains challenging, primarily due to nonholonomic vehicle dynamics, interactions with mixed static/dynamic obstacles, and the non-convex constrained nature of such operational spaces. To solve these problems, this paper proposes an Improved Sequential Model Predictive Control (ISMPC) navigation framework that systematically reformulates navigation tasks as sequential switched optimal control problems. The framework addresses the aforementioned challenges through two key innovations: 1) Implementation of a Multi-Directional Safety Rectangular Corridor (MDSRC) algorithm, which encodes the free space through rectangular convex regions to avoid collision with static obstacles, eliminating redundant computational burdens and accelerating solver convergence; 2) A sequential MPC navigation framework that integrates corridor constraints with barrier function constraints is proposed to achieve static and dynamic obstacle avoidance. The ISMPC navigation framework enables direct velocity generation for AMRs, simplifying traditional navigation algorithm architectures. Comparative experiments demonstrate the framework's superiority in free-space utilization ( an increase of 41.05$\%$ in the average corridor area) while maintaining real-time computational performance (average corridors generation latency of 3 ms).
A Novel Biologically Mechanism-Based Visual Cognition Model--Automatic Extraction of Semantics, Formation of Integrated Concepts and Re-selection Features for Ambiguity
Mar 25, 2016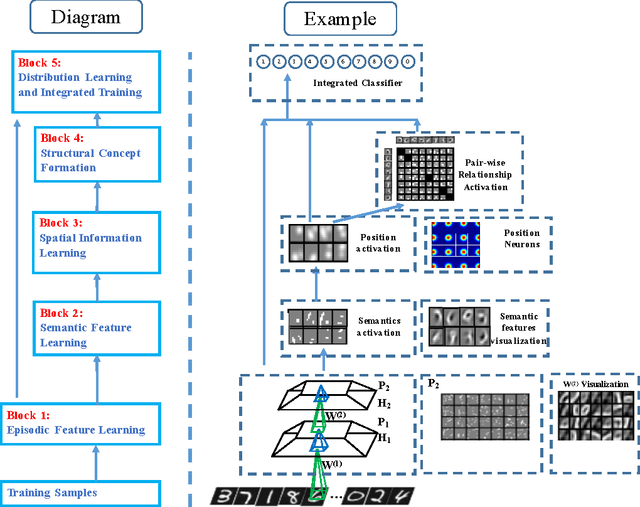
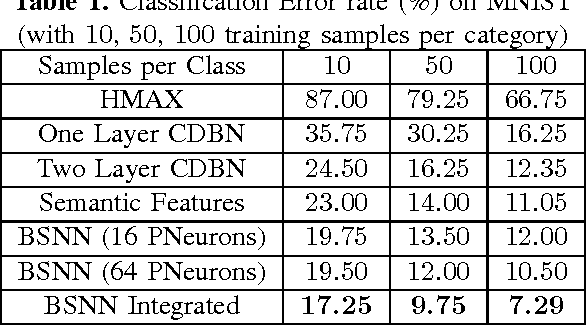
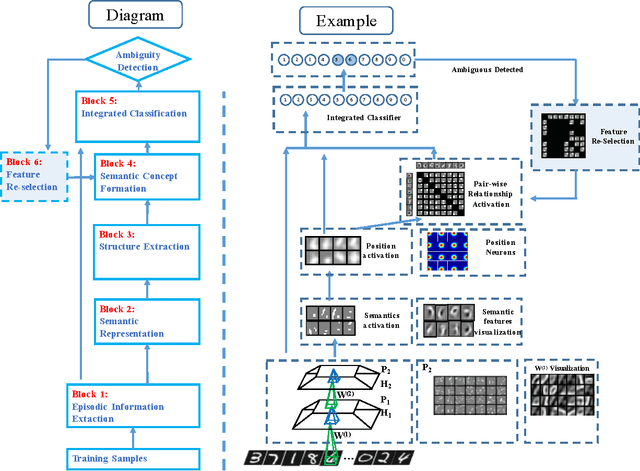
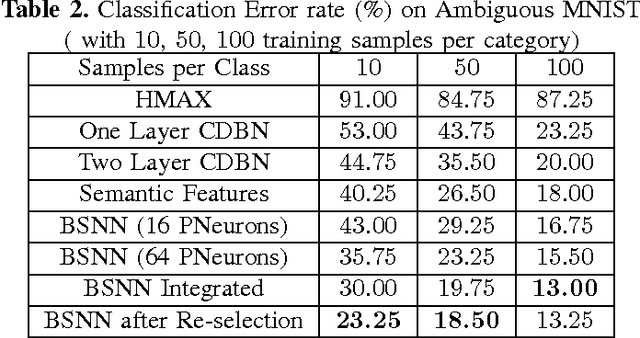
Integration between biology and information science benefits both fields. Many related models have been proposed, such as computational visual cognition models, computational motor control models, integrations of both and so on. In general, the robustness and precision of recognition is one of the key problems for object recognition models. In this paper, inspired by features of human recognition process and their biological mechanisms, a new integrated and dynamic framework is proposed to mimic the semantic extraction, concept formation and feature re-selection in human visual processing. The main contributions of the proposed model are as follows: (1) Semantic feature extraction: Local semantic features are learnt from episodic features that are extracted from raw images through a deep neural network; (2) Integrated concept formation: Concepts are formed with local semantic information and structural information learnt through network. (3) Feature re-selection: When ambiguity is detected during recognition process, distinctive features according to the difference between ambiguous candidates are re-selected for recognition. Experimental results on hand-written digits and facial shape dataset show that, compared with other methods, the new proposed model exhibits higher robustness and precision for visual recognition, especially in the condition when input samples are smantic ambiguous. Meanwhile, the introduced biological mechanisms further strengthen the interaction between neuroscience and information science.