 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVADER: Towards Causal Video Anomaly Understanding with Relation-Aware Large Language Models
Nov 10, 2025



Video anomaly understanding (VAU) aims to provide detailed interpretation and semantic comprehension of anomalous events within videos, addressing limitations of traditional methods that focus solely on detecting and localizing anomalies. However, existing approaches often neglect the deeper causal relationships and interactions between objects, which are critical for understanding anomalous behaviors. In this paper, we propose VADER, an LLM-driven framework for Video Anomaly unDErstanding, which integrates keyframe object Relation features with visual cues to enhance anomaly comprehension from video. Specifically, VADER first applies an Anomaly Scorer to assign per-frame anomaly scores, followed by a Context-AwarE Sampling (CAES) strategy to capture the causal context of each anomalous event. A Relation Feature Extractor and a COntrastive Relation Encoder (CORE) jointly model dynamic object interactions, producing compact relational representations for downstream reasoning. These visual and relational cues are integrated with LLMs to generate detailed, causally grounded descriptions and support robust anomaly-related question answering. Experiments on multiple real-world VAU benchmarks demonstrate that VADER achieves strong results across anomaly description, explanation, and causal reasoning tasks, advancing the frontier of explainable video anomaly analysis.
MovieCORE: COgnitive REasoning in Movies
Aug 26, 2025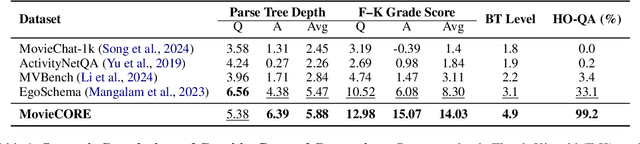
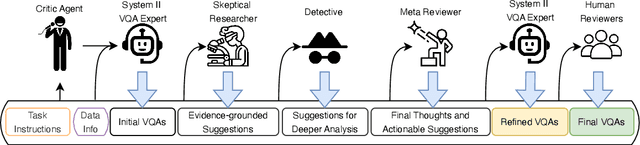
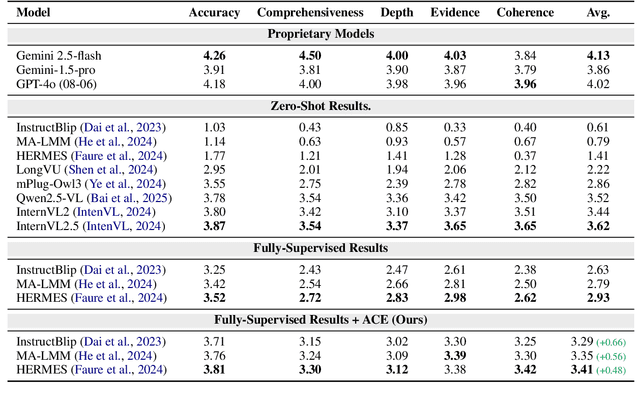

This paper introduces MovieCORE, a novel video question answering (VQA) dataset designed to probe deeper cognitive understanding of movie content. Unlike existing datasets that focus on surface-level comprehension, MovieCORE emphasizes questions that engage System-2 thinking while remaining specific to the video material. We present an innovative agentic brainstorming approach, utilizing multiple large language models (LLMs) as thought agents to generate and refine high-quality question-answer pairs. To evaluate dataset quality, we develop a set of cognitive tests assessing depth, thought-provocation potential, and syntactic complexity. We also propose a comprehensive evaluation scheme for assessing VQA model performance on deeper cognitive tasks. To address the limitations of existing video-language models (VLMs), we introduce an agentic enhancement module, Agentic Choice Enhancement (ACE), which improves model reasoning capabilities post-training by up to 25%. Our work contributes to advancing movie understanding in AI systems and provides valuable insights into the capabilities and limitations of current VQA models when faced with more challenging, nuanced questions about cinematic content. Our project page, dataset and code can be found at https://joslefaure.github.io/assets/html/moviecore.html.
KeyGS: A Keyframe-Centric Gaussian Splatting Method for Monocular Image Sequences
Dec 30, 2024



Reconstructing high-quality 3D models from sparse 2D images has garnered significant attention in computer vision. Recently, 3D Gaussian Splatting (3DGS) has gained prominence due to its explicit representation with efficient training speed and real-time rendering capabilities. However, existing methods still heavily depend on accurate camera poses for reconstruction. Although some recent approaches attempt to train 3DGS models without the Structure-from-Motion (SfM) preprocessing from monocular video datasets, these methods suffer from prolonged training times, making them impractical for many applications. In this paper, we present an efficient framework that operates without any depth or matching model. Our approach initially uses SfM to quickly obtain rough camera poses within seconds, and then refines these poses by leveraging the dense representation in 3DGS. This framework effectively addresses the issue of long training times. Additionally, we integrate the densification process with joint refinement and propose a coarse-to-fine frequency-aware densification to reconstruct different levels of details. This approach prevents camera pose estimation from being trapped in local minima or drifting due to high-frequency signals. Our method significantly reduces training time from hours to minutes while achieving more accurate novel view synthesis and camera pose estimation compared to previous methods.
CSAD: Unsupervised Component Segmentation for Logical Anomaly Detection
Sep 01, 2024To improve logical anomaly detection, some previous works have integrated segmentation techniques with conventional anomaly detection methods. Although these methods are effective, they frequently lead to unsatisfactory segmentation results and require manual annotations. To address these drawbacks, we develop an unsupervised component segmentation technique that leverages foundation models to autonomously generate training labels for a lightweight segmentation network without human labeling. Integrating this new segmentation technique with our proposed Patch Histogram module and the Local-Global Student-Teacher (LGST) module, we achieve a detection AUROC of 95.3% in the MVTec LOCO AD dataset, which surpasses previous SOTA methods. Furthermore, our proposed method provides lower latency and higher throughput than most existing approaches.
Bridging Episodes and Semantics: A Novel Framework for Long-Form Video Understanding
Aug 30, 2024



While existing research often treats long-form videos as extended short videos, we propose a novel approach that more accurately reflects human cognition. This paper introduces BREASE: BRidging Episodes And SEmantics for Long-Form Video Understanding, a model that simulates episodic memory accumulation to capture action sequences and reinforces them with semantic knowledge dispersed throughout the video. Our work makes two key contributions: First, we develop an Episodic COmpressor (ECO) that efficiently aggregates crucial representations from micro to semi-macro levels. Second, we propose a Semantics reTRiever (SeTR) that enhances these aggregated representations with semantic information by focusing on the broader context, dramatically reducing feature dimensionality while preserving relevant macro-level information. Extensive experiments demonstrate that BREASE achieves state-of-the-art performance across multiple long video understanding benchmarks in both zero-shot and fully-supervised settings. The project page and code are at: https://joslefaure.github.io/assets/html/hermes.html.
Spatio-Temporal Context Prompting for Zero-Shot Action Detection
Aug 29, 2024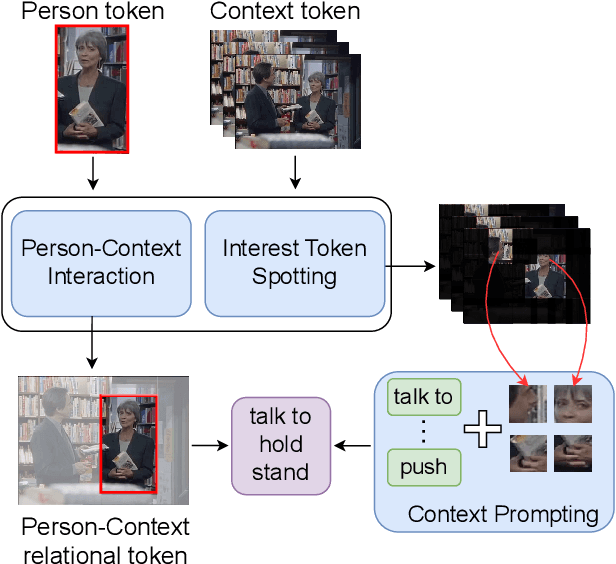
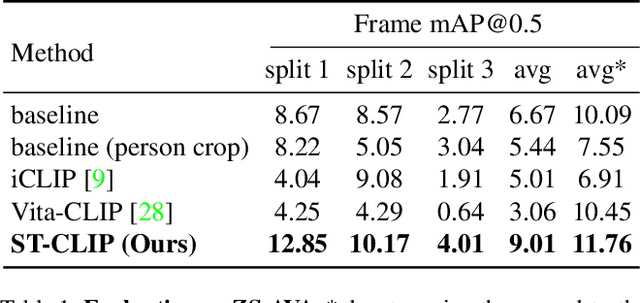
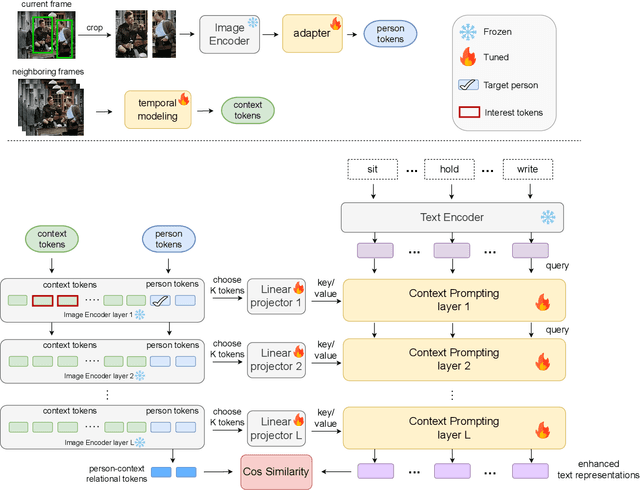
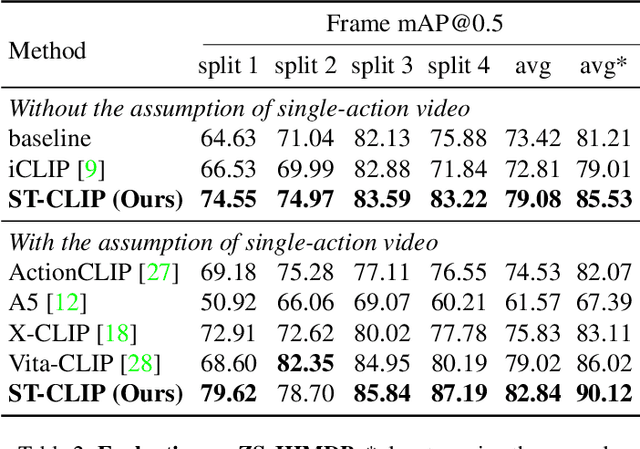
Spatio-temporal action detection encompasses the tasks of localizing and classifying individual actions within a video. Recent works aim to enhance this process by incorporating interaction modeling, which captures the relationship between people and their surrounding context. However, these approaches have primarily focused on fully-supervised learning, and the current limitation lies in the lack of generalization capability to recognize unseen action categories. In this paper, we aim to adapt the pretrained image-language models to detect unseen actions. To this end, we propose a method which can effectively leverage the rich knowledge of visual-language models to perform Person-Context Interaction. Meanwhile, our Context Prompting module will utilize contextual information to prompt labels, thereby enhancing the generation of more representative text features. Moreover, to address the challenge of recognizing distinct actions by multiple people at the same timestamp, we design the Interest Token Spotting mechanism which employs pretrained visual knowledge to find each person's interest context tokens, and then these tokens will be used for prompting to generate text features tailored to each individual. To evaluate the ability to detect unseen actions, we propose a comprehensive benchmark on J-HMDB, UCF101-24, and AVA datasets. The experiments show that our method achieves superior results compared to previous approaches and can be further extended to multi-action videos, bringing it closer to real-world applications. The code and data can be found in https://webber2933.github.io/ST-CLIP-project-page.
TAB: Text-Align Anomaly Backbone Model for Industrial Inspection Tasks
Dec 15, 2023In recent years, the focus on anomaly detection and localization in industrial inspection tasks has intensified. While existing studies have demonstrated impressive outcomes, they often rely heavily on extensive training datasets or robust features extracted from pre-trained models trained on diverse datasets like ImageNet. In this work, we propose a novel framework leveraging the visual-linguistic CLIP model to adeptly train a backbone model tailored to the manufacturing domain. Our approach concurrently considers visual and text-aligned embedding spaces for normal and abnormal conditions. The resulting pre-trained backbone markedly enhances performance in industrial downstream tasks, particularly in anomaly detection and localization. Notably, this improvement is substantiated through experiments conducted on multiple datasets such as MVTecAD, BTAD, and KSDD2. Furthermore, using our pre-trained backbone weights allows previous works to achieve superior performance in few-shot scenarios with less training data. The proposed anomaly backbone provides a foundation model for more precise anomaly detection and localization.
KFC: Kinship Verification with Fair Contrastive Loss and Multi-Task Learning
Sep 20, 2023Kinship verification is an emerging task in computer vision with multiple potential applications. However, there's no large enough kinship dataset to train a representative and robust model, which is a limitation for achieving better performance. Moreover, face verification is known to exhibit bias, which has not been dealt with by previous kinship verification works and sometimes even results in serious issues. So we first combine existing kinship datasets and label each identity with the correct race in order to take race information into consideration and provide a larger and complete dataset, called KinRace dataset. Secondly, we propose a multi-task learning model structure with attention module to enhance accuracy, which surpasses state-of-the-art performance. Lastly, our fairness-aware contrastive loss function with adversarial learning greatly mitigates racial bias. We introduce a debias term into traditional contrastive loss and implement gradient reverse in race classification task, which is an innovative idea to mix two fairness methods to alleviate bias. Exhaustive experimental evaluation demonstrates the effectiveness and superior performance of the proposed KFC in both standard deviation and accuracy at the same time.
ReST: A Reconfigurable Spatial-Temporal Graph Model for Multi-Camera Multi-Object Tracking
Aug 25, 2023Multi-Camera Multi-Object Tracking (MC-MOT) utilizes information from multiple views to better handle problems with occlusion and crowded scenes. Recently, the use of graph-based approaches to solve tracking problems has become very popular. However, many current graph-based methods do not effectively utilize information regarding spatial and temporal consistency. Instead, they rely on single-camera trackers as input, which are prone to fragmentation and ID switch errors. In this paper, we propose a novel reconfigurable graph model that first associates all detected objects across cameras spatially before reconfiguring it into a temporal graph for Temporal Association. This two-stage association approach enables us to extract robust spatial and temporal-aware features and address the problem with fragmented tracklets. Furthermore, our model is designed for online tracking, making it suitable for real-world applications. Experimental results show that the proposed graph model is able to extract more discriminating features for object tracking, and our model achieves state-of-the-art performance on several public datasets.
A Closer Look at Geometric Temporal Dynamics for Face Anti-Spoofing
Jun 25, 2023



Face anti-spoofing (FAS) is indispensable for a face recognition system. Many texture-driven countermeasures were developed against presentation attacks (PAs), but the performance against unseen domains or unseen spoofing types is still unsatisfactory. Instead of exhaustively collecting all the spoofing variations and making binary decisions of live/spoof, we offer a new perspective on the FAS task to distinguish between normal and abnormal movements of live and spoof presentations. We propose Geometry-Aware Interaction Network (GAIN), which exploits dense facial landmarks with spatio-temporal graph convolutional network (ST-GCN) to establish a more interpretable and modularized FAS model. Additionally, with our cross-attention feature interaction mechanism, GAIN can be easily integrated with other existing methods to significantly boost performance. Our approach achieves state-of-the-art performance in the standard intra- and cross-dataset evaluations. Moreover, our model outperforms state-of-the-art methods by a large margin in the cross-dataset cross-type protocol on CASIA-SURF 3DMask (+10.26% higher AUC score), exhibiting strong robustness against domain shifts and unseen spoofing types.